

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
Memory Ordering(内存序)
By Chen Jie of TinyLab.org 2017-01-29 21:11:17
前言:
在本站译文「实用同步原语伸缩技术 」中,来自 SUSE 实验室的 Davidlohr Bueso 总结了 Linux 内核对 大规模并发 的优化实践,即所谓的“老司机如何开得快”。而本文讨论的内存序,属于“老司机如何开得稳”。加起来,才有老司机开车又快又稳。
话归同步原语,多线程协同,若无同步机制保证,就像足球赛中传球射门,有时球传了队友还没跑到位。而所谓同步机制,基本上是在共享的内存区域,读写“通信变量”。例如,下述程序简述“传球射门”中的协同:
shooter_x = 36 loop:
shooter_y = 25 shooter_in_position == 0 ? goto loop
shooter_in_position = 1 ball_target_x = shooter_x;
loop: ball_target_y = shooter_y;
ball_passing == 0 ? goto loop ball_passing = 1
/* get ball and shoot */ /* pass ball */
左边是射手 - 将己位置写入变量、知会传球方。随后等球至并射门;右边传球方 - 等射手就位,设好传球目的坐标,知会射手并传球。
其中上述逻辑的正确性,取决于共享内存中变量的访问顺序,比如,shooter_in_position 务必在 shooter_x 和 shooter_y 之后(确切的说,是在传球方看来)。然实际顺序,未必等同 编码顺序,这便是内存序问题。
那么,哪些因素造成内存序问题?主要有:
- 编译器进行的指令优化
- CPU 硬件进行的、围绕乱序执行的指令优化
- 缓存一致性、总线上的缓冲等
第 1 点:编译中,高级语言被译成汇编指令,为求性能优化,会进一步调整汇编指令。这种调整,就像好心整理你房间的保姆,不经意把重要物件收在箱底,甚至丢弃掉。 为免编译器好心办坏事,常用嵌入式汇编来防止,例如内核中的 barrier() ,防止编译器跨 barrier() 重排指令:
#define barrier() __asm__ __volatile__("": : :"memory")
第 2 点:CPU 在执行中,根据内部单元忙闲,来重新安排指令。若执行指令所需内部单元都闲着,这条指令就可能被提前执行。这便是乱序执行(有兴趣的童鞋可参见本站「NVIDIA 黑科技: 丹佛核心杀到!」文中关于乱序的比喻)。
乱序执行是围绕“保持内部单元利用率”的指令调整,基于硬件运行时状态进行;与之相对的、编译器优化基于编译时刻的静态输入。
当然,上述优化带来的内存序问题,并不是编译器或硬件自作聪明,而是从优化者的视角,认为所做优化不影响正确性。这个“从优化者的视角”,正是内存序问题所在。对于乱序执行,当指令退出后,CPU 内部状态,比如各寄存器值与顺序执行一致。在另一种优化手段“猜测执行”中,猜错误写的寄存器可以撤销。然而作为外部资源 —— 内存、或严格地说物理地址空间,就不一定了。因它为多核 CPU、DMA 控制器,甚至是设备(MMIO)所共享。换句话说,优化只看 结果,但考虑内存序,需 注重过程。
第 3 点:缓存一致性同样是一个 只看结果 的过程:共享变量被更新,其在每个核的副本,只要之后同步一致即可,不关心具体同步顺序。
第 2、3 点,均与硬件相关,来自 Wiki:Memory ordering 展示了各体系 CPU 可能的内存序调整:
上图: x86 和 x86-64 架构内存序严格,x86 oostore 是 x86 史上一个变种,通过放宽内存序限制,来收获性能。ARMv7、POWER 以及 Alpha 处理器,作为 RISC 体系架构,追求硬件效率,毫无意外放宽内存序限制。其中,曾经号称地球上最快 CPU 的 Alpha,更是做到了极致,例如存在下述可能情形:
/*
* 共享变量
* const int invalid = -1;
* int *result = &invalid;
* int idx; (uninitialized,
* let's say its value is
* 327673313)
*/
// CPU 0: // CPU 1:
/* idx at cache A */ idx = 25;
/* result at cache B */ flush_cache();
result = &idx;
b = *result;
// b = 327673313!!
CPU 1 先写了 idx 值,随后 flush cache 来强制一个更新广播;最后让 result 指向 idx(其更新广播,由缓存一致协议来决定何时进行,此例假设立即进行了)。
CPU 0 这边,先读取 result 指针,内容为 &idx;然后对指针取值(即读取 idx 值),内容却是 327673313。仿佛先读取 idx,然后再读取 result。
为啥会这样?下图做了简释:
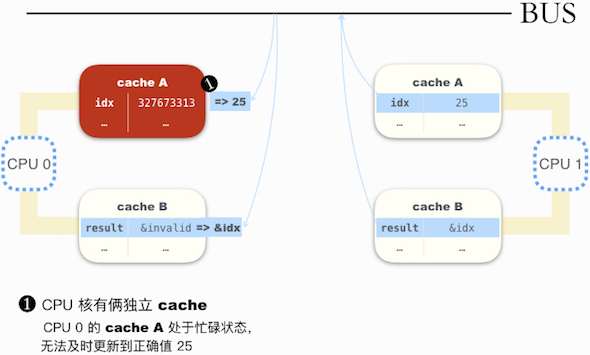
解决第 2、3 点,就需用内存序相关的指令 —— 告诉硬件,在不能重排的地方,别搞事情;同时在关键点或刷新,或监视 共享通信变量的变化。
总结一下,多线程协同需同步机制,而同步机制的实现,得考虑内存序。下面以两个直白的同步机制:spinlock 和 atomic64_add 操作为例,来看下内存序处理。代码摘取当下较火的、armv8 上的实现。
引例:armv8 上的 自旋锁 和 原子加 实现
自旋锁
从锁的基本 API 入手:spin_lock() 和 spin_unlock()。定义于 include/linux/spinlock.h,内容看起来像一个炸鸡块,外面裹了一层“面粉”:用于整合入 kernel 的基础设定框架,例如提供 SMP/UP、inline 编译开关、抢占、死锁检查等等。内在“鸡肉”,对于 armv8 而言,分别是 arch_spin_lock() 和 arch_spin_unlock(),实现了自旋锁的定义,即CPU 循环尝试锁定,直到获得锁。
自旋锁结构体同样是“包了面粉的炸鸡块”,“鸡肉”定义于 arch/arm64/include/asm/spinlock.h
typedef struct {
#ifdef __AARCH64EB__
u16 next;
u16 owner;
#else
u16 owner;
u16 next;
#endif
} __aligned(4) arch_spinlock_t;
owner 和 next 是两个计数器,其中对大小尾端的条件编译,表明内存中,owner 靠前(装载到寄存器后,对应数值低位),而 next 要靠后(装载到寄存器后,对应数值高位)。于是,当我们把 arch_spinlock_t 当作 32bits 来运算时,owner++ 意味着 arch_spinlock_t + 1,而 next++ 意味着 arch_spinlock_t + (1 << 16)。也正因为我们要把 arch_spinlock_t 当作 32bits 运算,所以结构体需要 4 字节对齐。
下图展示 lock 和 unlock 在上述结构体的体现:
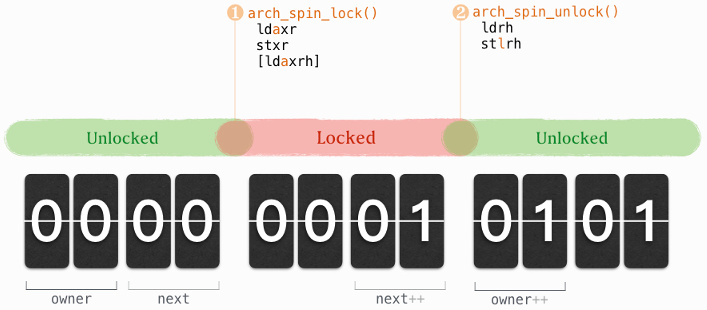
● arch_spin_lock()(其访存操作有:ldaxr, stxr,及可能有的 ldaxr):
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/*
* 预取指令 prfm
* "pstl1strm",跟着字母念:Prefetch for STore to L1 STReaMingly
* Streamlingly 代表流式的,即路过不回头(而非徘徊式)的访问。
* 类 MADV_SEQUENTIAL 之于 madvise()
*/
" prfm pstl1strm, %3\n"
/*
* 高能预警 ★_★
* 以下是 RISC 著名的 LL/SC(Load Link / Store Conditional)指令
* 即针对一个变量的事务内存,这个变量就是 %3,即“传入参数 lock”所指向
*
* "The LL": ldaxr:LoaD Acquire eXclusive Register
* "The SC": stxr: STore eXclusive Register(eXclusive 代表对单变量的事务内存)
* 作为事务内存,stxr 可能失败,比如 ldaxr-stxr 期间“变量 %3”被其他核改变。失败时 %w2 为 1
*/
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n" /* 即 lock->next + 1 */
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n" /* 若 %w2 不为 0(为 1),则回到“标签 1”重试 */
/*
* 至此,我们原子地 “lock->next++”。而 %w0 则是 “lock 旧值”
* 在 “%w0” 中,w 代表 word,armv8 语境中为 32bits 长度。
* “%w0, ror #16” 代表将 %w0 循环右移 16 位,即颠倒了 owner 和 next 位置
* 然后与颠倒前进行异或,结果为 0 代表 owner == next,即获得了锁,前进到“标签 3”
*/
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* 锁被别人拿走了,急的团团转!具体是这样转的:
*/
" sevl\n" /* set event locally,在当前核上设置一个事件,用于防止一种“死锁可能性”:
* 即“当别人释放锁,发 CPU 事件唤醒等待的核来抢”,但这个事件错过了(对
* CPU 而言,只有调用过 wfe 才会监听事件)
*/
"2: wfe\n" /* wait for event,等待事件到达,这会让 CPU 进入低功耗模式 */
" ldaxrh %w2, %4\n" /* LoaD Acquire eXculsive Register Halword,即读取 lock->owner */
" eor %w1, %w2, %w0, lsr #16\n" /* "%w0, lsr #16",逻辑右移 16 位,即“lock 旧值”->next
* 留意到此处借“异或操作 eor”,实现了“比较相等与否”的功能,
* 感受到 RISC 精简指令的光环了吗?
*/
" cbnz %w1, 2b\n" /* 若还没拿到锁,回“标签 2”再试! */
"3:"
: "=&r" (lockval) /* %0 */, "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT) /* %5 */
: "memory");
/* 形如 "=&r" 被称作“操作数的限定”(Constraints for asm Operands)。比如
* "=" 代表写入,"&" 代表输入输出寄存器不能重叠,"r" 代表分配个通用寄存器作中间载体
* 参见:https://gcc.gnu.org/onlinedocs/gcc/Constraints.html
*/
}
spinlock 锁定过程是先取号,再等候叫号。同时,spinlock 也是一种 CPU 多核间的“秒杀游戏”,只不过这个“秒杀”是取号时进行的。
如果比较下我们生活中遇到的秒杀 —— 不断点击重试,或是进入套路式的“下一步”...“下一步”,最后“失败重来” —— spinlock 这种先取号登记,再按取号顺序分配,是不是更省心、更有公平感?
● arch_spin_unlock()(其访存操作有:ldrh, stlrh):
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(
" ldrh %w1, %0\n" /* LoaD Register Halfword,即读取 lock->owner */
" add %w1, %w1, #1\n" /* 即 lock->owner + 1 */
" stlrh %w1, %0" /* STore reLease Register Halfword */
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}
自旋锁中的访存与内存序
在 lock() 过程中有三条访存指令:
- ldaxr、访存特点:Acquire、eXclusive
- stxr、访存特点:eXclusive
- ldaxrh、访存特点:Acquire、eXclusive
第一、二条中,exclusive 的 load 和 store 配对,构成了 LL/SC。而 Acquire 则是和 unlock 中的 reLease 配对。
第三条访存指令是条件执行的(当 spinlock 处于未锁定状态,则被跳过),其中 Acquire 是和 unlock 中的 reLease 配对。但为啥这个里也有 eXclusive 呢?当某个 CPU 核(ARM 术语唤做 PE)进入某地址的“Exclusive Access”,另一个核对该地址的 Store 操作将使之回到“Open Access”,并产生事件,使之从 wfe 中“醒来”(参见「ARM® Architecture Reference Manual ARMv8, for ARMv8-A architecture profile 」,“B2.10.2 Exclusive access instructions and Shareable memory locations”)。
在 unlock() 过程中有两条访存指令:
- ldrh、访存特点:无
- stlrh、访存特点:reLease
这个 reLease 就和 lock() 中的 Acquire 构成了所谓的 Load-Acquire 和 Store-Release:
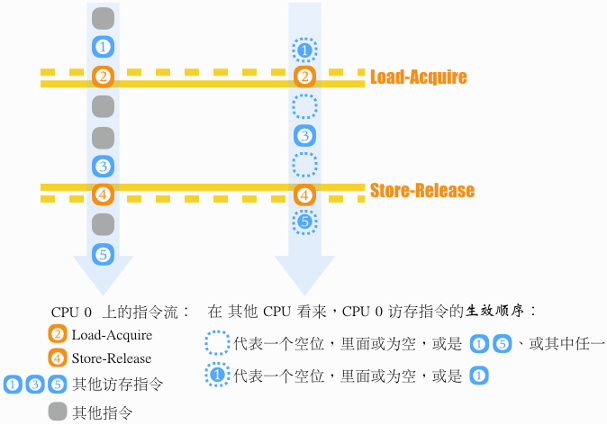
指令流中,夹在 Load-Acquire 和 Store-Release 之间的访存,既不能早于 Load-Acquire 生效,也不能晚于 Store-Release 生效。换言之,Load-Acquire 和 Store-Release 隔出一个临界区来,当某线程修改并离开临界区后,其对临界区的 全部修改 能 立即 被下一个进入临界区的线程看到。
Load-Acquire 和 Store-Release 为实现锁所需的内存序指令。
64 位原子加
64 原子加的系列操作,由“arch/arm64/include/asm/atomic_ll_sc.h”中的宏 ATOMIC64_OPS(add, add) 所展开。其中根据原子加操作返回值,分成了三类:
- 不返回:
atomic64_add - 返回加以后的值:
atomic64_add_return* - 返回加之前的值:
atomic64_return_add*
上表中,展开了 atomic64_add_return 实现,可以看到 RISC 没有原子操作指令,again,通过著名的 LL/SC(ld?xr/st?xr)对单变量的事务内存来实现。另外,上述展开包含了俩内存序指令:
stlxr:store-release,使得本操作可以和atomic64_add_return_acquire配对,构成对某个临界区的协商访问。dmb ish:跟着字母念 - Data Memory Barrier for Inner SHareable domain - 是一个共享内存中的内存屏障。既然是共享内存,与谁共享呢?通常是多核系统中的其它 CPU 核,所以这条指令也是 smp_mb()在 arm 上的实现。另一个需留意的 —— 不仅需要写者执行“内存屏障”,来把更新立即通知到总线;读者也需执行之,来清空本地旧相应缓冲,及时得到最新版本。就好像一方喊“天王盖地虎”,另一方应“宝塔镇河妖”,这个协商才能玩得转。
顺便说一下后缀 _relaxed,意味着本操作,是一个放松内存序限制的版本,比如atomic64_add_return_relaxed,相比 atomic64_add 除了有返回值外,主体实现是一致的。
C/C++ 规范中的内存序
C/C++ 在原子操作函数中,包含一个内存序参数,用于定制的多线程协商访问。其中 C++ 规范中的阐述更详细,以下择之来详细展开。
#include <atomic>
std::atomic<int> cnt = {0};
void f()
{
for (int n = 0; n < 1000; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
std::memory_order_relaxed 是一个内存序参数,意思是内存序无限制,胡来吧🙃。除此之外,还有如下内存序可指定:
std::memory_order_consume:用在 std::atomic::load 中,依赖 load 进来值的操作(仔细想想,什么叫“依赖”呢?即指令流中排在 load 之后,并以 load 结果为输入的那些指令),不能在 load 之前生效。除了 Alpha 之外的平台,基本上就是一个编译器级别的屏障,参见前言中关于 Alpha 的图例。std::memory_order_acquire、memory_order_release:load-acquire 与 store-release。std::memory_order_acq_rel:read-modify-write(RMW)操作,原子操作包含“acquire”和“release”:当前线程中 访存操作“生效顺序的重排”,不能跨越“本 RMW 中的 store”;store 之后,其结果能被其它线程的 acquire 操作所看到。std::memory_order_seq_cst:Sequentially-consistent ordering —— 除了包含“acquire”和“release”,所有“memory_order_seq_cst”的原子操作,构成一个全局的序列(a single total modification order)。- 每个“memory_order_seq_cst”原子操作,在序列中拥有一个序号。
- 换言之,A、B 和 C 仨“memory_order_seq_cst”原子操作,若 A 在 B 前(A appears before B),B 在 C 前(B appears before C),则 A 在 C 前(A appears before C)。这就是所谓的 传递性(Transitivity)。
- 下例中,若 CPU 1 fence 晚于 CPU 0(in the single total modification order),则 CPU 1 能成功读到 CPU 0 写的 M:
// CPU 0 // CPU 1
write M;
std::atomic_thread_fence(
std::memory_order_seq_cst); /*
^ * the fence in CPU 1 is __after__
\ * the fence in CPU 0 in
appears after * the single total modification order
\ */
`--------------- std::atomic_thread_fence(
std::memory_order_seq_cst);
read M; /* perceive the modification
from CPU 0 successfully */
memory-barrier.txt
Documentation/memory-barrier.txt 介绍了 Linux 内核实现的、更复杂的内存序问题解决方案。限于篇幅,拟在新开篇作翻译和学习笔记。
小伙伴们新年快乐,鸡年大吉!
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
