

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
Memory Ordering(内存序):memory-barrier.txt
By Chen Jie of TinyLab.org 2017-02-14 00:25:17
前言:
前篇就内存序问题由来、同步机制中内存序指令的应用,以及 C/C++ 原子操作相关的内存序做了介绍。其中,编译器和硬件优化只关注结果,而多方协同中却需要关注过程细节,这个矛盾,需内存序指令来调和。另一方面,原子操作,为多方协作排了先后顺序,在此基础上,有些内存序指令可进一步确保临界区访问不重叠(在各方看来),比如 Load-acquire/Store-release。
Documentation/memory-barrier.txt 介绍了 Linux 内核中的内存序实现,相较更为复杂。本文试图从一个新视角,试图一目了然。
Again,本文链接的代码如体系架构相关,选 ARMv8 示例。首先交待下背景。
内存序最小假定
Linux 对于 CPU 内存序,做了如下最小假定:
- 在任何 CPU 中,前后依赖的访存,CPU 按照指令流来发指令。留意这个假定需对 DEC Alpha 作额外步骤,即通过
smp_read_barrier_depends()来清空变量旧缓存:
Q = READ_ONCE(P);
smp_read_barrier_depends(); /* 清空 *Q 在 cache 中的缓存,
* 防止读到过时数据,Alpha only */;
D = READ_ONCE(*Q);
// CPU 执行指令顺序:Q = LOAD P, D = LOAD *Q
- 对于某个 CPU,前后两条访存指令,其一读,另一写,且读和写的区域存在重叠,则该 CPU 严格按指令流序来发指令。
a = READ_ONCE(*X); WRITE_ONCE(*X, b);
// CPU 执行指令顺序:LOAD *X, STORE *X = b
WRITE_ONCE(*X, c); d = READ_ONCE(*X);
// CPU 执行指令顺序:STORE *X = c, d = LOAD *X
但,上述假定有如下例外:
对“位域”(bitfields,类似结构体中“int b1:1;int b2:1;”这样的定义)无效,因编译器很可能产生非原子的 RMW(read-modify-write)代码来操作位域。因此,别拿位域来做并行算法中的同步标记。另一方面,请使用同一把锁,保护 全部位域;若手贱用俩锁来保护邻近两组位,则更新其中一组很可能影响另一组。
上述假定中,假定访存目标是 自然对齐的自然尺寸。比如访存目标尺寸为双字节(short、unsigned short),则要求地址也是双字节对齐。
上述最小假定是为了维持因果性,即指令流中先后俩指令,均对后面某结果有贡献,则其顺序不能改变。这个贡献可能是链式传播的,即一环扣一环(“假定 1”);或是均有贡献(“假定 2”)
“假定 1”谈论的是 Data dependencies;与之相对的是 Control dependencies,即指令流中先前指令,决定了指令流路径,从而间接影响指令流路径上的每个结果。
Control dependencies
通过一组例子来看下实践中 Control dependencies 的注意事项:
- 例1:
READ_ONCE—— 防止编译器合并 a、b 装载;或编译器 “认为 a == 0”,而且剥离掉整个 “if” 语句!smb_rmb()—— 防止 CPU 在乱序执行时,通过分支预测,使得读取 b发生于读取 a之前
q = READ_ONCE(a);
if (q) {
smp_rmb(); /* read barrier */
p = READ_ONCE(b);
}
- 例2:用
WRITE_ONCE而不是直接赋值;若采用直接赋值,编译器可能优化出形如 右边注释块 的代码:
// b = 42;
if (a) // if (a)
WRITE_ONCE(b, a); // b = a;
else
WRITE_ONCE(b, 42);
- 例3:留意到两个
WRITE_ONCE(b, p)一摸一样,编译器可能会提取到“if …”语句之前- 若
WRITE_ONCE()像上描述的那样,被编译器上移,CPU 就可以乱序执行之了(而不是在条件分支之后生效) - 通过塞入 barrier() 来防止。编译器不能跨 barrier() 来重排指令。
- 若
乱序执行 CPU 通常具备猜测执行能力,即依据历史猜条件分支会走哪一条,然后提前执行。猜测执行的指令会作上标记,直到条件被确定 —— “猜对”则让生效(比如写到 architecture registers,或是写到物理内存中;“猜错”则作废)。
另一留意到的是,WRITE_ONCE() 在写原生类型的时候,不带 barrier() 所以不会阻止编译器重排指令,这就是为什么需手动在代码中植入 “barrier()”
q = READ_ONCE(a);
/*
* Without barrier(), WRITE_ONCE(b, p) may be
* combined and moved here by compiler
*/
if (q) {
barrier();
WRITE_ONCE(b, p);
do_something();
} else {
barrier();
WRITE_ONCE(b, p);
do_something_else();
}
- 反面教材1:条件被编译器优化掉,比如下面例中 MAX == 1。这个条件总是成立,编译器会去掉条件判断,将总是成立的分支直接提到外面来:
q = READ_ONCE(a);
if (q % MAX) {
WRITE_ONCE(b, p);
do_something();
} else {
WRITE_ONCE(b, r);
do_something_else();
}
- 反面教材2:还是条件被编译器优化掉,不过以另一方式:
q = READ_ONCE(a);
if (q || 1 > 0)
WRITE_ONCE(b, 1);
- 反面教材3:条件块之外的
WRITE_ONCE(c, 1),不受分支指令护序,所以会被 CPU 乱序执行:
q = READ_ONCE(a);
if (q) {
WRITE_ONCE(b, p);
} else {
WRITE_ONCE(b, r);
}
WRITE_ONCE(c, 1); /* BUG: No ordering against the read from "a". */
上面三例和前两个反面教材,全是谈论 Control dependencies 中如何防范编译器优化“作祟”。下面顺着再给几例“编译器优化使坏的”、“不易察觉”的情况。
小心编译器优化
反面教材1:
p = 0x76543210; // 请使用 WRITE_ONCE(p, 0x76543210);
给 p 赋值的对象,是一个很大的立即数。这样就无法用一条指令来完成赋值了(因为指令长度,比如 RISC 处理器通常是 32bits,32bits 中只会留一点点,比如 16bits 来编码立即数,这样就需要多条指令了)。编译器可能会用多条立即数“存”指令来,使得期间有多次“存”的动作,其他 CPU 核就可能观察到中间一个“撕裂”的值。
反面教材2:
struct __attribute__((__packed__)) foo {
short a;
int b;
short c;
};
struct foo foo1, foo2;
...
foo2.a = foo1.a;
foo2.b = foo1.b;
foo2.c = foo1.c;
这个是一个 __packed__ 结构体,所以域 int b 之前没有 padding,即起始地址不是 4 字节对齐的。编译器可能用一条 32bit load,来装载“foo1.a”和“foo1.b 的一部分”;再一条 32bits load,来装载“foo1.b 的剩下部分”和“foo1.c”。再两条 32bits store 指令写到 foo2 上。这里,foo1.b 的复制中,也出现了中间的“撕裂”值。所以,还是要请出“WRITE_ONCE” 和 “READ_ONCE”来帮忙:
foo2.a = foo1.a;
WRITE_ONCE(foo2.b, READ_ONCE(foo1.b));
foo2.c = foo1.c;
load/store 地址不对齐的内存变量,有些体系架构下需多条指令,比如 MIPS 要用“lwr + lwl” 来完成一次非对齐 32bits load、“swr + swl” 来完成一次非对齐 32bits store。很显然,其他 CPU 核仍可能观察到中间的“撕裂”值。所以,应避免多线程中去直接使用这样的结构体。
哪些场合需保证内存序?内核有哪些 APIs 可用?
保证内存序,常用 内存屏障 方法。依据各级正确性要求,提供了各种力度的内存屏障。比如通用内存屏障,隔开了(指令流中)其前后的访存指令。而弱一些的读屏障,则隔开(指令流中)其前后的内存读访问;写屏障则隔开(指令流中)其前后的内存写访问。
一个粗略的 “内存序使用场合” 与相应的 “内存序 APIs” 对应如下图:

Interprocessor interaction
多核间协同,保证内存序的基础屏障为 smp_mb / smp_rmb / smp_wmb / smp_read_barrier_depends,即通用内存屏障 / 读屏障 / 写屏障 / “依赖读”屏障。屏障使用需要配对,即沟通双方,一方用 通用内存屏障 或弱化为 写屏障;另一方用通用内存屏障,或弱化为 读屏障(或是可进一步弱化为 “依赖读”屏障)。
基础之上、扩展的屏障如下:
smp_store_mb:store 某变量 + 通用内存屏障lockless_dereference:相当于*ptr,但在装载 “ptr” 的值,与装载 “ptr 的值所示地址处的变量” —— 这两个有依赖的装载之间,插入一个smp_read_barrier_depends
留意到这些是多核协同用到的内存屏障,在 UP 编译配置下(即关闭内核对多核支持),退化为一个编译屏障(即 barrier())。
另要提一句,通用内存屏障之间,符合全局的“传递性”,A,B,C 三个通用内存屏障,若 A 在 B 前,B 在 C 前,则 A 在 C 前。换言之,任意两个通用内存屏障必有先后。其实就是所谓的 “Sequential Consistency” (参见前篇评论区,或对应论文「WRL_Research_Report_957」)。由于指令流中 通用内存屏障 前的访存指令,生效在屏障前;之后的生效在屏障后 —— 故屏障间的先后,进一步影响屏障附近的访存指令。
ACQUIRE / RELEASE
在 Linux 一系列锁的构造:
- spin lock
- R/W spin locks
- mutexes
- semaphores
- R/W semaphores
其 “锁定” 和 “释放” 操作暗含内存屏障,下面这个图来自前篇中 spinlock 内存序介绍:
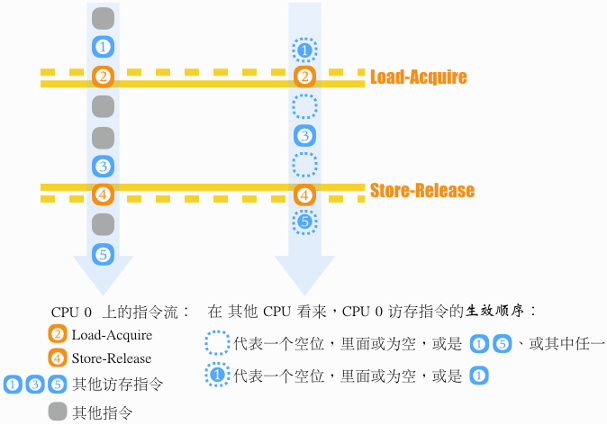
图中 “虚实线” 恰如交规中的“虚实线” ,虚线一侧访存可能转入临界区,而临界区内访存无法越过 “实线”,从而不能逃逸出临界区。
如果不想让临界区之前 “内存写” 窜入临界区,可使 smp_mb__before_spinlock,然后再施 ACQUIRE。
一组 ACQUIRE 和 RELEASE 可构成 局部的“传递性”,例如下面例子中,cpu0 - 2 构成了一条局部的先后序链:
- 留意 cpu0、cpu1 之普通访存操作都被 load-acquire 约束在临界区;cpu2 无普通访存操作
- 若有 r0 == 0 && r1 == 1 && r2 == 1,则可知其序为 cpu0 > cpu1 > cpu2
- cpu3 不在局部序链中,故可能存在 “r0 == 0 && r1 == 1 && r2 == 1 && r3 == 0 && r4 == 0”
- 留意 r3 的写端为 cpu0,读端为 cpu3;r4 写端为 cpu3,读端为 cpu1
- 若 cpu3 的
smp_mb在局部的先后序链中,则由 r3、r4 可知 cpu3 > cpu0、cpu1 > cpu3,即 cpu1 > cpu3 > cpu0 与第二点矛盾,故 cpu3 不在(反证法)
int u, v, x, y, z; /* all are initialized to zero */
void cpu0(void)
{
r0 = smp_load_acquire(&x);
WRITE_ONCE(u, 1);
smp_store_release(&y, 1);
}
void cpu1(void)
{
r1 = smp_load_acquire(&y);
r4 = READ_ONCE(v);
r5 = READ_ONCE(u);
smp_store_release(&z, 1);
}
void cpu2(void)
{
r2 = smp_load_acquire(&z);
smp_store_release(&x, 1);
}
void cpu3(void)
{
WRITE_ONCE(v, 1);
smp_mb();
r3 = READ_ONCE(u);
}
Other IMPLICIT kernel barriers
某些 kernel 函数自带 barrier 效果,他们是:
- 开关中断函数:但仅相当于编译器的屏障(即
barrier()) - 睡眠和唤醒函数:“wait_*()” 和 complete()、“wake_up*()”
- 其他:比如
schedule()系列函数,相当于mb()
下面展开睡眠和唤醒函数,首先 set_current_state() 含 smp_mb。于是,所有调到它的函数都含通用屏障:
prepare_to_wait()
prepare_to_wait_exclusive()
wait_event()
wait_event_interruptible()
wait_event_interruptible_exclusive()
wait_event_interruptible_timeout()
wait_event_killable()
wait_event_timeout()
wait_on_bit()
wait_on_bit_lock()
其次,执行唤醒的代码,通常形如下例:
event_indicated = 1;
wake_up(&event_wait_queue); // 或 wake_up_process(event_daemon);
而与之对应的睡眠代码,形如下:
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (event_indicated)
break;
schedule();
}
上面代码头几句解构开来看,如下(左边是 sleeper,右边是 waker,留意 waker 带了个“写屏障” (<write barrier>) ):
CPU 1 CPU 2
=============================== ===============================
set_current_state(); STORE event_indicated
smp_store_mb(); wake_up();
STORE current->state <write barrier>
<general barrier> STORE current->state
LOAD event_indicated
注:只有真正执行了唤醒操作,才会有“写屏障”。因为“写屏障”是在唤醒过程中执行。
唤醒函数都自带“写屏障”:
complete();
wake_up();
wake_up_all();
wake_up_bit();
wake_up_interruptible();
wake_up_interruptible_all();
wake_up_interruptible_nr();
wake_up_interruptible_poll();
wake_up_interruptible_sync();
wake_up_interruptible_sync_poll();
wake_up_locked();
wake_up_locked_poll();
wake_up_nr();
wake_up_poll();
wake_up_process();
此节最后一个注意事项,来自这个例子:
/* sleeper */ /* waker */
my_data = value;
event_indicated = 1;
set_current_state(TASK_INTERRUPTIBLE);
if (event_indicated)
break;
__set_current_state(TASK_RUNNING);
do_something(my_data);
wakeup(&event_wait_queue);
sleeper 可能恰好看到 event_indicated 为 1,但尚未收到 my_data 的新值 value。纠正如下:
/* sleeper */ /* waker */
my_data = value;
smp_wmb(); /* ★_★ */
event_indicated = 1;
set_current_state(TASK_INTERRUPTIBLE);
if (event_indicated) {
smp_rmb(); /* ★_★,参见本文开头
* 关于 Control dependencies 讨论*/
break;
}
__set_current_state(TASK_RUNNING);
do_something(my_data);
wakeup(&event_wait_queue);
Atomic Operations
原子操作其实也属于多核间协同,它们被特别提到因为:
- 除了 “显示锁定操作”,每个返值(无论返旧值或新值)的原子操作,都(效果上)包含一个
smp_mb(回见前篇中 ARMv8 上原子加的介绍):
// 可用来实现 ACQUIRE 以及 RELEASE
xchg();
atomic_xchg(); atomic_long_xchg();
atomic_inc_return(); atomic_long_inc_return();
atomic_dec_return(); atomic_long_dec_return();
atomic_add_return(); atomic_long_add_return();
atomic_sub_return(); atomic_long_sub_return();
atomic_inc_and_test(); atomic_long_inc_and_test();
atomic_dec_and_test(); atomic_long_dec_and_test();
atomic_sub_and_test(); atomic_long_sub_and_test();
atomic_add_negative(); atomic_long_add_negative();
test_and_set_bit();
test_and_clear_bit();
test_and_change_bit();
/* when succeeds */
cmpxchg();
atomic_cmpxchg(); atomic_long_cmpxchg();
atomic_add_unless(); atomic_long_add_unless();
- “显示锁定操作”,带有 load ACQUIRE / store RELEASE 内存屏障:
// 实现锁时,应首先考虑用这些原子操作:
test_and_set_bit_lock();
clear_bit_unlock();
__clear_bit_unlock();
- 不暗含内存屏障:
atomic_add();
atomic_sub();
atomic_inc();
atomic_dec();
// 可用来实现 RELEASE
atomic_set();
set_bit();
clear_bit();
change_bit();
对于不含内存屏障的原子操作,可通过前后加入 smp_mb__before_atomic 和 smp_mb__after_atomic,来带入内存屏障。比如引用计数的实现中:
obj->dead = 1; /* 指示对象已经消亡 */
smp_mb__before_atomic();
atomic_dec(&obj->ref_count); /* 若缺了上个内存屏障,可能观察到
* obj->ref_count == 0,但 obj->dead != 1
Interrupts、Accessing Devices
CPU 和 设备间通信,或通过系统内存(System Memory),或通过 MMIO(Memory Mapped IO)或 IN/OUT 指令。
思考 DMA(Direct Memory Access):CPU 分配一段缓冲区,然后把 缓冲区地址 及 输入数据 丢给设备。设备工作完成后,结果存在缓冲区,并中断 CPU 告之。
在中断中,CPU 从缓冲区取结果,或继续填下一段输入。如前述开关中断的函数仅暗含编译屏障(即 barrier()),故需内存屏障来保证彼此看到正确的数据,这就是 dma_wmb 和 dma_rmb(以及 wmb、rmb 和 mb):
- Documentation/memory-barrier.txt 中关于两者描述,提及了其作用于连续的物理内存。我们知道,常常设备只能 DMA 低(物理)地址的连续区域。
- 通过 IOMMU 单元,一些设备能够访问虚拟地址,故无需物理内存连续。此时,内存屏障应该是通过
mb、wmb和rmb。 dma_wmb和dma_rmb比wmb和rmb更加轻量,这个说法来自 patchwork:5334001。- 下面例子展示其用法:
// desc 结构体负责 CPU 与设备 通信
if (desc->status != DEVICE_OWN) {
// 从下面注释来看,dma_rmb 像是 Control dependencies
// 防范乱序执行的措施,参见文章开头处讨论
//
// 不过,另一方面,访问 desc->data 之前,同样要加 dma_rmb,
// 因为读和写的内存屏障要配对嘛
/* do not read data until we own descriptor */
dma_rmb();
/* read/modify data */
read_data = desc->data;
desc->data = write_data;
/* flush modifications before status update */
dma_wmb();
// 留意下面这个赋值,起到了关门的作用(A Gate Variable!)
// 即对某一方,如果是“开门状态”,必然”门后已经准备妥当”
// (“准备妥当”意为,通过 dma_wmb 保证对方能 __完整__ 看到)
/* assign ownership */
desc->status = DEVICE_OWN;
// 这个据说是处理 cache 一致性的
/* force memory to sync before notifying device via MMIO */
wmb();
// 以下这个操作访问设备的 MMIO
/* notify device of new descriptors */
writel(DESC_NOTIFY, doorbell);
}
另外,既然涉及系统内存,必关系 cache 一致性问题(其中,上述内存屏障应已包含类似工作,但有时,也许还需要显式操作 cache):
- 问题1:各个 CPU 写给设备的东东 还在 cache,尚未抵达内存。解法是各 CPU flush(或有需要,invalidate)相应 cacheline。
- 问题2:设备 DMA 回来的内存数据,1) 却被某个 CPU 覆写了一部分(该 CPU cache 中的脏行正在回写内存);2) 或 CPU 自己的 cache 未觉察到相应内存区域的更新,使 CPU 从 cache 中读到了旧数据。解法是各 CPU invalidate 相应 cacheline。
MMIO 空间,通常由物理地址窗口来定义,比如 MIPS 32bits 下的 kseg1,intel 的 MTRR 或 PATs。这些物理地址窗口,通常没有 cache 罩着(但可以再细分出窗口,应用写合并优化 (Write Combine,或用龙芯术语,Uncache Accelerate) )。
对 MMIO 空间访问,通过 “readX” 和 “writeX”:
readb(读 1 字节)、readw(读 2 字节)、readl(读 4 字节)、readq(读 8 字节)writeb(写 1 字节)、writew(写 2 字节)、writel(写 4 字节)、writeq(写 8 字节)
上述两类访问方式,保证 同一物理地址窗口中,它们之间 是全序的,且不会作合并优化。
- 但不排除总线上存在缓冲,从而最终抵达设备时顺序不保证,可以采用 先写再读同一地址 来进一步保证顺序(但这样做可能让某些设备罢工)。
- 对于可预取的 IO memory,也许需要
mmiowb来保证“写”操作。
最后,上述两类访问,存在对应的 “_relaxed” 版本:
- 访问同一外围设备 时,relaxed 操作间是全序的
- 其他情况下,比如与普通访存不保证顺序;不能被约束在 LOCK / UNLOCK 所包含的临界区(要约束,请考虑
mmiowb)
MMIO 内存序呈现更加的硬件多变性,进一步信息参见「LWN: Semantics of MMIO mapping attributes across architectures」。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
