

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
NVIDIA 黑科技: 丹佛核心杀到!
by Chen Jie of TinyLab.org 2014/11/02
前言
三年前,科技界的猛人公司 NVIDIA 宣布了丹佛项目(Project Denver),开发一种全新的 CPU。今年,承载着 NV 制霸地球野心的 Tegra K1 移动芯片发布。其 GPU 部分基于 Kelper 架构,而 CPU 部分则分为两个版本:
- 第二季度发布的 四核 Cortex-A15 核心版(32 位)
- 及不久随着 Nesux 9 露面的 双核 Denver 核心版(64位)
据评测,Tegra K1 的 GPU 性能略低于 iPad Air 2 所搭载的 A8X。而 Denver 核心的 CPU 单核计算性能(这跑的还是 AArch32 指令集的测试程序哟~)则超越之,位居移动芯片领域榜首,甚至逼近 2011 款的 Macbook Air:
GEEKBENCH 3 SINGLE-CORE:
- 1812 (A8X)
- 1903 (Tegra K1 Denver)
- 1940 (Core i7-2677M)
NV 是如此评价其酷炫屌炸天的 CPU 架构设计:“Dynamic Code Optimization is the architecture of the future”(CPU 构架的未来是基于动态指令代码优化技术)。
顺便说下,这个动态指令代码优化,并不是 NV 独创或首次商业化的。早在若干年前有家叫全美达(Transmeta)的公司就曾推出过采用此技术的 CPU。更值得一提的是,Linus 当时也在全美达参与这项未来黑科技的开发,甚至于朋友们都以为他加入了邪教。。。
OK,让我们来走近看下 NV 的黑科技,首先从目下主流的、乱序执行(OoOE,Out of Order Execute)的 CPU 设计开始。
OoOE 两三景
就像许多技术始于日常生活的司空见惯,我们用一个例子来描述乱序执行的设计。
在这个例子里,人们前往营业厅办理业务,刚来的人排队,然后轮到时入座,等待叫号办业务。而办理柜台是一个不多见的、流水线的方式 —— 办事的人顺次在该柜台的各个子柜台上,完成业务的各个阶段。这里将 CPU 执行的每条指令,类比做办业务的人。
一个全景图如下:
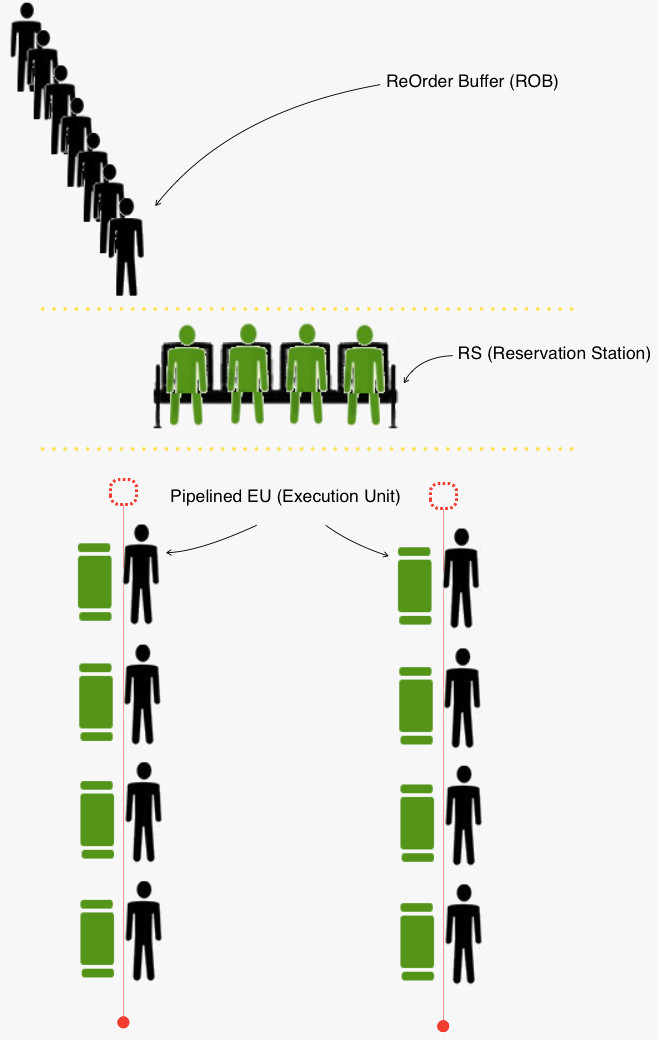
上面这个例子里,介绍了三个部件:
- 重排队列(ROB)。指令顺序进入该队列,等待执行。执行完成后的指令在队列中标记。然后队列另一端依次等待 并将完成的指令出列。
- 保留站(RS)。保留站位于执行单元(EU)之前,本着站内哪条指令就绪,就发送到执行单元,并不顾其先后顺序,从而使执行单元尽量忙碌。保留站是乱序执行的关键环节。
- 执行单元。实际做事的部件,通常是流水线化的。
我们再来放大看下保留站中发生的两个场景。
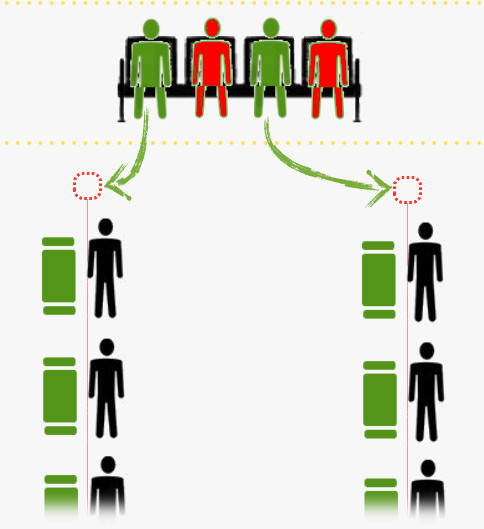
场景一:将就绪指令投放给执行单元。就绪指令即指令依赖的源操作数均已经取得。以前述例子为类比,就绪指令好比办业务所需材料齐备(绿色小人),非就绪指令则类比 所办业务尚缺材料,等待别人办业务时输出(红色小人)。于是,在时钟周期到来时,绿色小人被叫号,前往柜台办理业务。
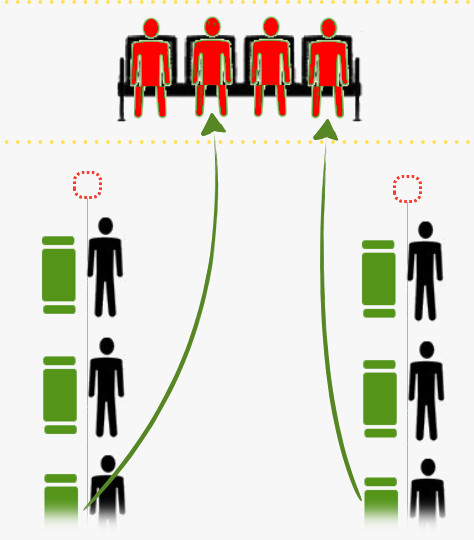
场景二:下一个时刻,保留站中指令获得所缺源操作数。以前述例子为类比,两个手持材料不全的红色小人,得到了所需材料。这些材料是其他人办理业务中输出的。此时,手头材料齐备了的小人就可以被叫号,前往柜台办理业务。
顺序执行也有优点
至此,粗浅地看了下乱序执行是怎么回事。那么问题来了,如何提高 CPU 构架的执行效率?由前述至少有两个努力的方向:
- 增加执行单元。这就好比例子中,增加办业务的柜台数量,从而增加同时进行的业务数量。
- 加大保留站。若保留站中的指令均依次依赖,这又退回到了一次一条的效率了。此时,加大保留站,使之终于有指令不依赖而能并行执行。这个措施同时也说明,硬件上实现的保留站容量,限制了优化执行的效果。
非常遗憾的是,保留站这种神器,制造代价比较大,占面积,吃能源。
所以省掉了保留站等部件、顺序执行的 CPU,有低功耗和省芯片面积的优点。但其每周期执行的指令数(IPC),最多不超过一条。(要是遇到前面的指令等待源操作数,后面的指令不管有依赖的没依赖的,都得等,最终 IPC 哗哗往下掉)
这时,来了个叫 VLIW(Very long instruction word)概念,想法是把原来 N 条无关指令并成一条指令。这样一条 VLIW 指令执行时,相当于原来 N 条指令同时执行。从描述看得出,VLIW 指令比一般的指令要长很多(要不然怎么叫 “Very long” )呢。例如,通常一条 RISC 指令是 4 字节,而全美达的克鲁索处理器一条 VLIW 指令是 16 字节。
那么问题又来了,谁来判断几个操作是无关的,从而塞入一条 VLIW 指令呢?在安腾平台上,这是由编译器来完成的。然而这样做至少有几个问题:
- 程序体积发福:填指令时,若果凑不到足量的无关操作,就不得不加入空操作(nop),于是程序变胖了。
- 编译时刻太早,没法进行某些优化。举个简单例子,“if (a) …”,如 a 是常量,则编译器优化时可以移除一个分支。如是变量,而运行时却被赋固定值,那么这个优化编译器是无能为力了。
Denver 核心本质上也是一款 VLIW,不过它选择在运行时动态优化指令代码,并将其缓存。通常优化这种事,信息越具体所能达到的效果越好,因此运行时动态优化的效果非常让人期待。
Meet the Denver Core
Denver 核心,对外的“接口指令集”是 ARMv8 指令集,因此这是一款 64位 的 ARM 处理器。
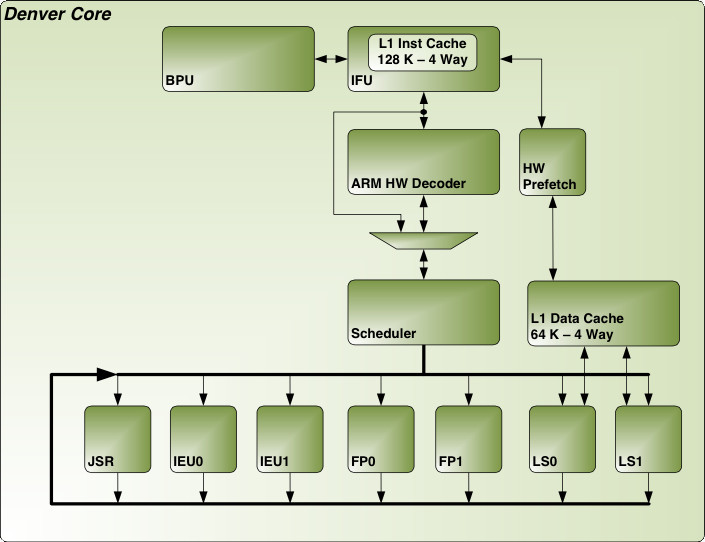
对上图唠叨下:
- 动态指令代码优化,并不取代其他硬件优化部件。上图中,有 BPU(分支预测单元)、HW Prefetch(内存预取单元,同时负责指令和数据预取)
- IFU 取指单元,带有一个 4 路的 128 KB一级缓冲。有意思的是所取指令不仅是 ARMv8 指令,还可能是内部的微代码(应该是一种 VLIW 指令)。前种类型的指令,还要过硬件解码器。后种类型的指令则直接执行。
- 七组执行单元:分支单元(JSR)x1,整数单元(IEU)x2,浮点/ NEON 单元(FP)x2,访问单元(LS)x2。这通常意味着峰值 IPC 能达到 7,不过两组 LS 单元能同时执行 2 条装载和存储指令,理论峰值 IPC 要高于 7。
NV 提到,和先烈全美达相比,通过大幅增强硬件综合素质,来避免运行非原生指令(ARMv8 指令)时性能下降太多。
下面两组示意图,介绍动态指令代码优化技术:
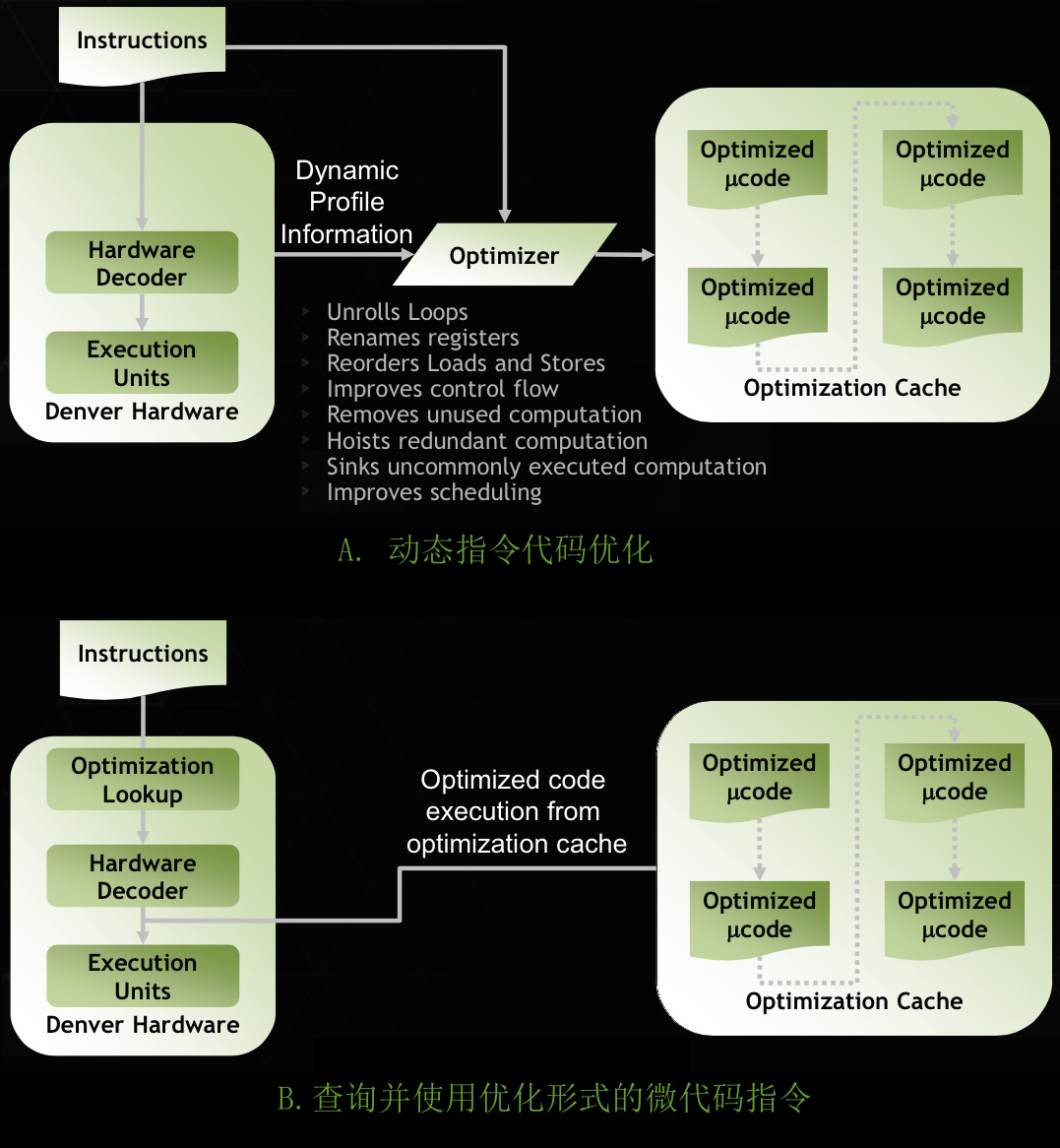
- A. 动态指令代码优化:在某个核空闲时,开始指令代码的优化(翻译)过程。该过程依据运行时的动态剖析数据,落实多种优化手段。最后将优化生成的微代码指令块用链表的方式组织起来,并存在预留的 128 MB 物理内存中。
- B. 查询并使用优化形式的微代码指令。提到一个查询器,来查询缓存的优化微代码指令块,细节不详。
由此可见 Denver Core 的绝招在于代码跑过几遍后,变得飞快。就好像火影(Naruto)中的雷影,活化以后,速度爆快。
同时我们也留意到,与 OoOE 相比,动态指令代码优化的范围不受硬件部件尺寸的限制,且不用次次去优化,优化效果更好,并且省电。
讨论
首先,想问“双核,单核性能强” vs “四/八核,单核性能弱”,选前者还是后者?
这就像问,三个臭皮匠,顶个诸葛亮,选三个臭皮匠呢?还是选孔明?
IMHO,还是选孔明好。多核 CPU 需要配套多线程编程,介个需要改造程序。且不论改造工作量,就算大部分都改造了,多线程间通信也会带来一定延时,增加了响应时间,这对人机交互密集的手机等设备而言是个坏消息。顺便说一句,即使在服务器上的应用,也有些应用序列化很强,难以并行编程,需要依赖彪悍的单核性能。据说 12306 某些内部逻辑就是。
因此,我们看到苹果的设备一直保持着较高的单核性能 和 较少的核数。NV 的 Tegra K1 也是这种思路。我甚至觉得,Tegra K1 之所以出“四核A15”和“双核 Denver”两个版本,也是向消费者讲一个故事,这个故事就是四个臭皮匠,不如两孔明,你用过就知道了。
另外,在工程上,NV 也展示了它的成熟。Tegra K1 同时引入新的 GPU 核和 CPU 核,分成两步走。先是成熟的 CPU(4个A15)核搭配新的 GPU 核(Kelper),然后再引入新的 CPU 核( Denver Core)。除了拆分风险,前者的存在,还为 Denver Core 的工程实现提供一个技术对比参照,从而明确技术规格上的定位。(: 国产 *芯,是否从中借鉴些工程上的思路?不再是犹如一场说走就走的旅行,全凭一时爱好和口号,最后做出了toy(s)?
市场上的细腻,工程上的成熟,这些还不算丹佛项目中最为耀眼的。时光倒退 3 年,甚至更远的年份至项目酝酿阶段,面对那时的 Intel 市场和产品所构筑的高墙,仍决定进军 CPU 领域并如今初现锋芒,这份远见和决心,令人颤抖。作为对比,也许有许多公司,看不清未来,也少了自知而不信自,于是把鸡蛋散在多个“当时热点”的篮子中,结果…它们最后都碎了。
最后,再回多核这个话题上,似乎“少数高性能核” 比 “多数低性能核” 要好。在“少数高性能核”基础上,再搭配一些低性能核,形成异构多核,也有其存在意义。
单核高性能的达成,通常需要诸如更大的缓存、更激进的内存预取等等方式,这意味着更高的能耗。考虑减少能耗,就像油价猛涨时期考虑如何节约,有人会准备多辆不同排量的车,短途代步用小排量的,长途高速用中等排量的,而复杂地形则用巨猛排量的。
类比过来,可以采用异构的多核设计,将轻量级任务,在保证响应前提下运作于低能核上;重量级任务则运作于高能核上。这是一种以节能为目的的多核方案,在这造个词称之为“矩核”:
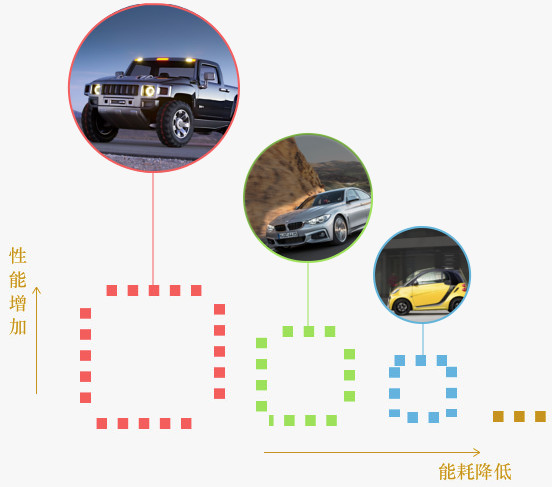
识别轻/重量级任务,并将其派发到适合的核上,便是“矩核”实现上的关键。此处列出一系列办法:
- 通过亲和度来固定特定任务到指定核上
- 通过指令来触发调度(专利申请号:201210149055X)。这需要应用在多线程开发时,考虑区分重量级线程(如那些在该线程上集中进行密集计算的)和轻量级线程。
- 或再如 MX4,big.LITTLE(A17.A7)中实现的内核调度器层面的调度。感兴趣?召唤文章来详细介绍,to be continued? @吴章金falcon @…
参考链接
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
