

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
Linux Swap 与 Zram 详解
Zhizhou Tian 创作于 2016/12/23
By ZhizhouTian of TinyLab.org 2016-12-23 18:04:30
简介
Zram Swap 是 Linux 内核中采用时间换空间的一种技术。它通过压缩内存(Zram)来作为交换分区,通过压缩比来获取更多可利用的内存空间。该技术目前在各类内存受限的嵌入式系统中,尤其是 Android 手机、电视等设备上广泛采用,本文对此进行了详细介绍。
为了更好地理解,首先我们介绍了内存管理基本概念,内存回收以及内存交换技术。
内存管理基本概念
内存管理区 struct zone
struct zone表示一个内存管理区,用于跟踪page用量、空闲区域、锁等统计信息,内部含有page_high、page_low、page_min三个水位线。
当小于page_low时唤醒swapd进行回收,到达page_high时停止。但即使到达page_min仍然可以使用GFP_ATOMIC分配。此时,分配器会同步调度swap,即直接回收路径。
可以向/proc/sys/vm/min_free_kbytes写入以更改page_min(以kbyte为单位)。
内存管理区共有三个:dma zone、normal zone及high zone,由于 ARM 架构下,normal zone也可以用于 DMA 操作,因此dma zone大小为0。
normal zone管理 1024-128 = 896M 以下的内存,high zone管理896M以上的内存。注意,ARM32 架构下,Linux-v3.2之后的版本中,对此进行了修改,请参考mail list。在这一提交中,将属于内核的1G空间的最后264M划作三个部分:第一个8M用于隔离,第二部分的240M用于vmalloc,最后16M用于连续DMA。也就是说normal zone位于1024-264=760M之下了(同时也是high_memory的值)。
PFN(page frame number)
PFN是在系统初始化时,以4K为单位对所有可用内存进行编号,从0x8000_0000/PAGE_SHIFT开始。内存管理区的(start, end)使用的就是PFN的值。
页 struct page
该结构体用于表示一个页框,在 ARM32 架构中,可以通过mem_map数组与PFN进行对应。该结构体中与页框回收比较相关的成员包括:
unsigned long flags
PG_active、PG_referenced用于表示当前页的活跃状态,并决定是否回收PG_unevictable表示当前页不可以回收PG_mlocked表示当前页被系统调用mlock()锁定了,禁止换出和释放PG_lru表示当前页处于lru链表中PG_swapcache表示当前页正在被换出/换入PG_private及PG_private_2分别用来表示一个zspage的第一个页和最后一个页
struct
address_spacemapping末位为0时,跟踪当前页映射的文件;为1时,指向anon_vma(包含了1至多个vma)
struct list_head lru用于将当前页加入到某个lru的list
在Zram中的重新定义
许多page的属性在zram中另有定义。比如lru用于链接zspage所属的所有页。详细见zram的介绍。
PTE 与 VMA
Page Table Entry表示进程的Page Table中的一项,即最低级的页表项,一般为4K大小。
在Linux中定义为
pte_t(实际上就是一个unsigned 32)。当页驻留在内存中时,则PTE的低12位中包含PFN,且最低位(present位)为1;当页在交换分区中的页槽中时,则PTE的低12位中包含页槽的地址,且最低位为0,这种情况下对这个页访问,硬件会rise一个缺页中断。每个进程的虚拟内存空间都被分为许多的虚拟内存区域(VMAs),VMA是页对齐的一段连续虚拟内存,且这些内存地址都拥有相同的访问权限。比如,进程中,有code、data、stack、heap等VMA。
VMA与PTE的关系:每个VMA的虚拟地址被划分为多个页,这些页可以通过2级映射(ARM32 )或者3级映射(ARM64),通过缺页中断,内核将这些页映射到真实的物理页上,对应page table中的一个pte,所以每个VMA对应0至多个PTE。
内存回收
当系统内存紧张时即会进行内存回收。回收的办法,或者是对文件页进行写回,或者是对匿名页进行交换。
File Cache 与 Anon Page
可以被回收的页可划分为两种:
文件页(file cache)
其特征是与外部存储设备上的某个文件相对应,有外部的后援设备(backend),而
page->mapping末位为0。例如用户控件进程对某个磁盘上的文件使用mmap系统调用时分配的页。在内存回收时,被写过的文件页(脏文件页)将被写回以保存起来。写回之后的页将被释放。而没有被写过的页,比如进程代码段的页,他们是只读的,直接释放就可以了匿名页(anonymous cache).
其特征是,内容不来自于外部存储设备,
page->mapping末位为1,例如为用户进程进程中的malloc系统调用分配的页即属于匿名页。在内存回收时,匿名页将会被交换到交换区而保存起来。交换之后页将被释放。
除了一些特殊的页面分配方法(比如在映射时即进行页面分配,以提高性能)之外,大多用户进程的页(无论是文件页还是匿名页)都是通过page fault进行分配的。这些属于用户进程的页中,除了PG_unevictable修饰(不可回收)的页面都是可以进行回收的(关于这个部分的介绍请见这里,比如ramfs所属页、mlock()的页等)。当页面通过page fault被分配的时候,file page cache 被加入到非活动链表中(inactive list), 匿名页(anonymous page)被加入到活动链表中(active list)。
LRU 算法
在内存回收时,系统会对页加以选择:如果选择经常被用到的页,即便回收了,马上又要被用到,这样不仅不能降低内存紧张的情形,反而会增加系统的负担。所以应当选择不太常用的页(或最近没有被用到的页)来回收。采用的主要算法就是LRU算法。
Linux为了实现该算法,给每个zone都提供了5个LRU链表:
- Active Anon Page,活跃的匿名页,
page->flags带有PG_active - Inactive Anon Page,不活跃的匿名页,
page->flags不带有PG_active - Active File Cache,活跃的文件缓存,
page->flags带有PG_active - Inactive File Cache,不活跃的文件缓存,
page->flags不带有PG_active - unevictable,不可回收页,
page->flags带有PG_unevictable
共包含四种操作:
- 将新分配的页加入到lru链表
- 将inactive的页从放到inactive list的链表尾部
- 将active的页转移到inactive list
- 将inactive的页移到active list
而inactive list尾部的页,将在内存回收时优先被回收(写回或者交换)。
lru 缓存
每个zone都有一套lru链表,而zone使用一个spinlock对于LRU链表的访问进行保护。在SMP系统上,各个CPU频繁的访问和更新lru链表将造成大量的竞争。因此,针对lru的四种操作,每个CPU都有四个percpu的struct page*数组,将进行需要进行相应操作的页先缓存在这个数组中。当数组满或者内存回收时,则将数组中的页更新到相应的lru上。
举个例子:当CPU0从normal zone上分配了一个页之后,即将这个页放到操作1的数组中。当数组满了之后,则将数组中的页逐个的加入到对应的zone所属的inactive page list或者inactive anon list(根据page可以得到对应的zone信息和该page是一个文件页还是匿名页的信息。新页首次加入lru链表,默认状态为inactive)。
lru list 的更新
除非进行页面回收,否则内存页在挂到lru list上之后是不移动的。对于匿名页和文件页,lru有着不同的更新策略:
对于匿名页链表的更新
系统要求inactive anon lru的总量不能低于某个值。该值是一个经验值。对于1G的系统,要求inactive anon lru上挂的内存页总量不低于250M。当内存回收启动时发现inactive anon不足时,则从active anon lru list尾部拿一些page(一般为32个),将他们的PTE中的ACCESSD标记清0(每次访问这个页面,硬件会将该位置1),放在inactive list的链表头。然后遍历inactive lru的链表尾部,如果此时ACCESSD的标记为1(说明最近被访问过),则重新放到active list中,否则将交换出去。
对于文件页链表的更新
系统要求inactive file-cache lru上页的总量不低于active file-cache lru上页的总量即可。当内存回收启动时发现不满足上述情况,则从active file-cache lru链表的尾部拿一些page,清空ACCESSED标记,保持
PG_referenced,放到inactive的头部。然后扫描inactive的尾部,并进行以下处理:如果是
PG_referenced为1,清0,不管ACCESSSED标记是什么,都放到active file-cache lru的头。如果映射了该文件页的进程的PTE中有ACCESSED标记为1,则放到active file-cache lru的头。否则,则写回并释放。
那么,为什么相对匿名页,文件页会使用一个PG_referenced呢?这是因为一个文件页,常常是被多个进程映射的。对这个标记的设置,在read/write等系统调用中。
文件页与匿名页的回收比例
内存回收时,会按照一定的比例对匿名页与文件缓存的回收,而swapiness就是这个比值。可以通过/proc/sys/vm/swappiness进行设置。当这个值为0时,则表示仅以释放文件页来回收内存,设置为100的时候,则一半来自文件页,一半来自匿名页。
调用内存回收接口的两条路径
有两条路径会调用内存回收接口:
- 当系统分不出内存时,在内存分配函数中同步调用内存回收接口,称为同步回收
- 内核线程kswapd会在zone的水位下降到
page_low时醒来并调用内存回收接口,称为异步回收
是时候祭出这张图了:
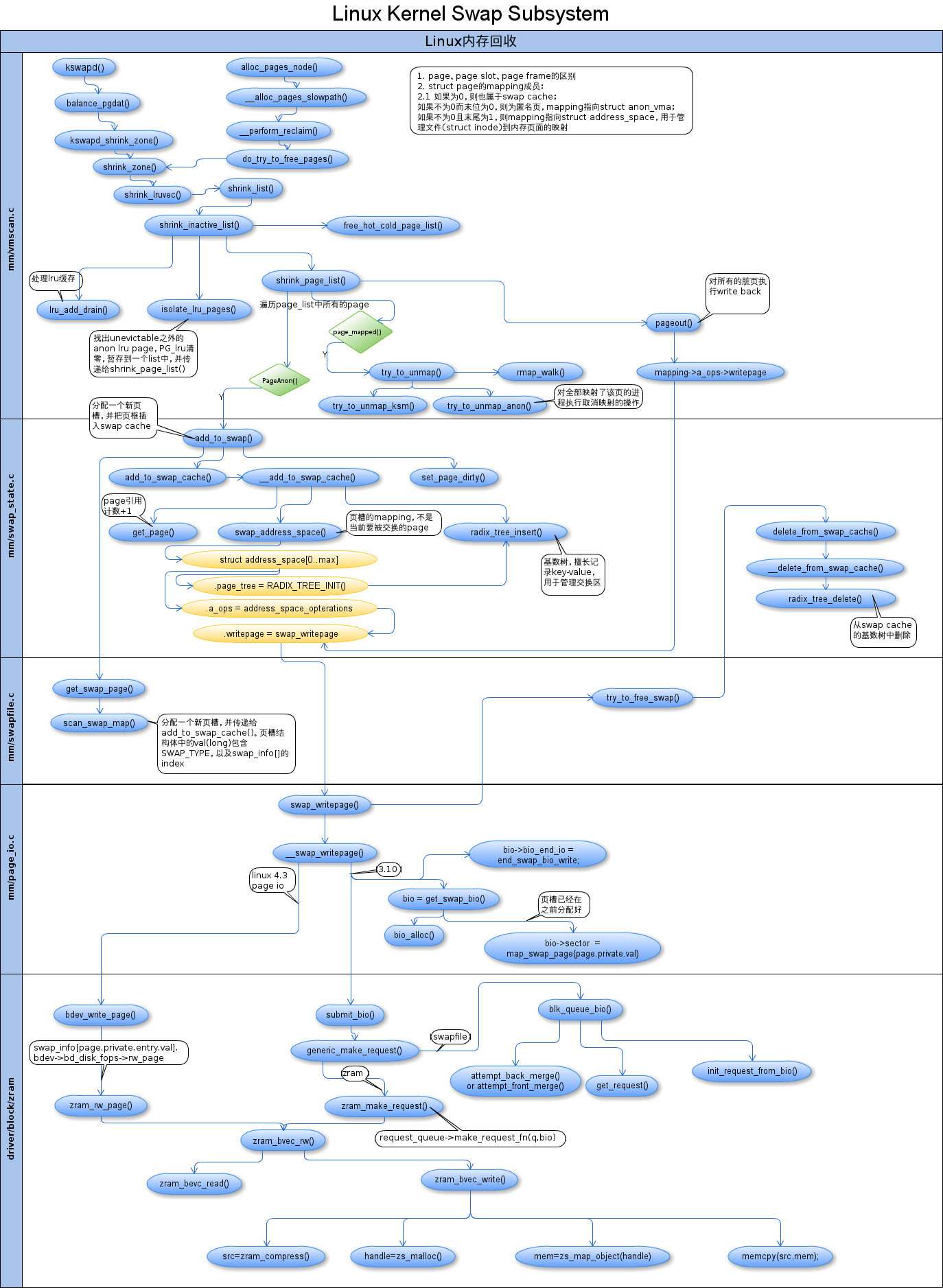
两条路径都会调用shrink_zones(),而该函数会对每个zone的inactive lru list进行回收。 对于文件页的处理,这里不作讨论。接下来讨论对匿名页的处理,即交换。
匿名页的内存回收 - 交换
交换用来为匿名页提供备份,可以分为三类:
- 属于进程匿名线性区(如用户态堆栈、堆)的页
- 属于进程私有内存映射的脏页
- 属于IPC共享内存的页
就像请求调页,交换对于程序必须是透明的。即不需要在程序中嵌入交换相关的特别指令。每个pte都包含一个present位,内核利用这个标志来通知属于某个进程地址空间的页已经被换出。在这个标志之外,Linux还利用pte中的其他位存放页标识符(swapped-out page identifier)。 该标识符用于编码换出页在磁盘中的位置。当缺页异常发生时,相应的异常处理程序可以检测到该页不在Ram中,然后换入页。
交换子系统主要功能为:
- 在磁盘上建立交换区
- 管理交换区空间,分配与释放页槽
- 利用已被换出的页的pte的换出页标识符追踪数据在交换区中的位置
- 提供函数从ram中把页换出到交换区或换入到ram
交换可以用来扩展内存地址空间,使之被用户态进程有效的使用。一个系统上运行的应用所需要的内存总量可能会超出系统中当前的物理内存总量,其原理就是将暂时不用的内存交换出去,待用到的时候再交换进来。
交换区的数据结构
从内存中换出的页存放在交换区(swap area)中。交换区可架设在磁盘分区、大文件甚至内存型文件系统中。同时可以存在MAX_SWAPFILES(32左右)个不同类型的交换区,而并发操作的交换区可以提高性能。
每个交换区都由一组页槽(page slot)组成,每个页槽大小一页。交换区的第一个页槽永久存放有关交换区的信息:
union swap_header {
struct {
char reserved[PAGE_SIZE - 10];
char magic[10]; /* SWAP-SPACE or SWAPSPACE2,用于标记分区或文件为交换区 */
} magic;
struct {
char bootbits[1024]; /* Space for disklabel etc.包含分区数据、磁盘标签等 */
__u32 version; /* 交换算法的版本 */
__u32 last_page; /* 可有效使用的最后一个槽 */
__u32 nr_badpages;/* 有缺陷的页槽的个数 */
unsigned char sws_uuid[16];
unsigned char sws_volume[16];
__u32 padding[117];/* 用于填充的字节 */
__u32 badpages[1]; /* 用来指定有缺陷的页槽的位置 */
} info;
};
创建与激活交换区
通过mkswap可以将某个分区设置成交换区,初始化 union swap_header,检查所有页槽并确定有缺陷页槽的位置。交换区由交换子区组成,子区由页槽组成,由swap_extent来表示,包含页首索引、子区页数及起始磁盘扇区号。当激活交换区时,组成交换区的所有子区的链表将创建。存放在磁盘分区中的交换区只有一个子区,但是存放在文件中的交换区可能有多个子区,这是因为文件系统可能没有把该文件全部分配在磁盘的一组连续块中。
交换区优先级
同时存在有多个交换区时,快速交换区(存放在快速磁盘中的交换区)可以获得高优先级。查找页槽时从优先级最高的交换区开始搜索。如果优先级相同,则循环使用以平衡负载。
交换区描述符
每个活动的交换区都有自己的swap_info_struct:
struct swap_info_struct {
unsigned long flags; /* SWP_USED etc: see above,交换区标志 */
signed short prio; /* swap priority of this type,交换区优先级 */
struct plist_node list; /* entry in swap_active_head */
struct plist_node avail_list; /* entry in swap_avail_head */
signed char type; /* strange name for an index */
unsigned int max; /* extent of the swap_map,最大页槽数 */
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
struct swap_cluster_info *cluster_info; /* cluster info. Only for SSD */
struct swap_cluster_info free_cluster_head; /* free cluster list head */
struct swap_cluster_info free_cluster_tail; /* free cluster list tail */
unsigned int lowest_bit; /* index of first free in swap_map */
unsigned int highest_bit; /* index of last free in swap_map */
unsigned int pages; /* total of usable pages of swap */
unsigned int inuse_pages; /* number of those currently in use */
unsigned int cluster_next; /* likely index for next allocation */
unsigned int cluster_nr; /* countdown to next cluster search */
struct percpu_cluster __percpu *percpu_cluster; /* per cpu's swap location */
struct swap_extent *curr_swap_extent; /* 指向最近使用的子区描述符 */
struct swap_extent first_swap_extent;/* 第一个交换子区。由于是块设备所以仅有一个交换子区 */
struct block_device *bdev; /* swap device or bdev of swap file */
struct file *swap_file; /* seldom referenced */
unsigned int old_block_size; /* seldom referenced */
unsigned long *frontswap_map; /* frontswap in-use, one bit per page */
atomic_t frontswap_pages; /* frontswap pages in-use counter */
spinlock_t lock; /*
* protect map scan related fields like
* swap_map, lowest_bit, highest_bit,
* inuse_pages, cluster_next,
* cluster_nr, lowest_alloc,
* highest_alloc, free/discard cluster
* list. other fields are only changed
* at swapon/swapoff, so are protected
* by swap_lock. changing flags need
* hold this lock and swap_lock. If
* both locks need hold, hold swap_lock
* first.
*/
struct work_struct discard_work; /* discard worker */
struct swap_cluster_info discard_cluster_head; /* list head of discard clusters */
struct swap_cluster_info discard_cluster_tail; /* list tail of discard clusters */
};
** flags 字段**:包含的位的含义为:
enum {
SWP_USED = (1 << 0), /* is slot in swap_info[] used?指示该交换区是否是活动的 */
SWP_WRITEOK = (1 << 1), /* ok to write to this swap?是否可以写入,只读为0 */
SWP_DISCARDABLE = (1 << 2), /* blkdev support discard */
SWP_DISCARDING = (1 << 3), /* now discarding a free cluster */
SWP_SOLIDSTATE = (1 << 4), /* blkdev seeks are cheap */
SWP_CONTINUED = (1 << 5), /* swap_map has count continuation */
SWP_BLKDEV = (1 << 6), /* its a block device */
SWP_FILE = (1 << 7), /* set after swap_activate success */
SWP_AREA_DISCARD = (1 << 8), /* single-time swap area discards */
SWP_PAGE_DISCARD = (1 << 9), /* freed swap page-cluster discards */
/* add others here before... */
SWP_SCANNING = (1 << 10), /* refcount in scan_swap_map */
};
swap_map字段:指向一个计数器数组,交换区的每个页槽对应一个元素。如果计数器值等于0,那么页槽就是空闲的,如果是正数,表示共享该换出页的进程数;如果计数器值为SWAP_MAP_MAX,那么存放这个页槽的页就是永久的,不能从相应的页槽中删除;如果计数器值为SWAP_MAP_BAD,那么这个页槽就是有缺陷的,不可以使用。
#define SWAP_MAP_MAX 0x3e /* Max duplication count, in first swap_map */
#define SWAP_MAP_BAD 0x3f /* Note pageblock is bad, in first swap_map */
#define SWAP_HAS_CACHE 0x40 /* Flag page is cached, in first swap_map,表示页被缓存了? */
由于一个页可以属于几个进程的地址空间,所以它可能从一个进程的地址空间被换出,但仍然保留在ram中。因此可能把同一个页换出多次。一个页在物理上仅被换出并存储一次,但是后来每次换出该页都会增加swap_map计数(同时_mapcount会减小吗?)。其实现逻辑为swap_duplicate():
使用
swap_type(swap_entry_t)提取所在分区及offset,通过swap_info[]获得struct swap_info_struct *,通过struct swap_info_struct->swap_map[]获得页槽计数值。使用
swap_count(unsigned char)来查看页槽计数值是不是SWAP_MAP_BAD增加页槽计数值
- 如果参数为
SWAP_HAS_CACHE,则是原有值加上它(表示当前页被缓存了?) - 如果参数为1,则判断是否超出
SWAP_MAP_MAX,不超出则增加1 - 如果计数值包含COUNT_CONTINUED,则可能是用来处理vmalloc page的?
- 如果参数为
需要注意的是,首次分配页槽时(也就是get_swap_page调用scan_swap_map),会将SWAP_HAS_CACHE传递给页槽计数
lowest_bit字段:第一个空闲页槽
highest_bit字段:最后一个空闲页槽
cluster_next字段:存放下一次分配时要检查的第一个页槽的索引
cluster_nr字段:存放已经分配的空闲页槽数
swap_info:struct swap_info_struct swap_info[]表示所有的交换区,数组长度MAX_SWAPFILES,用nr_swapfiles - 1来表示数组中最后一个已经激活的交换区的index。
换出页标识符
pte共有三种状态:
- 当页不属于进程的地址空间(进程页表下),或者页框还没有分配给进程时,此时是空项
- 最后一位为0,表示该页被换出。此时pte表示为换出页标识符。
- 最后一位为1,页在ram中。
在换出状态下,pte被称为swap_entry_t(换出页标识符):typedef struct { unsigned long val; } swp_entry_t;
该标识符由三个部分充满一个long:最高5bit表示来自哪个swap分区,2bit表示是否来自于shmem/tempfs,24bit表示在页槽中的offset,交换区最多有2^24个页槽(64GB)。最后一位为0表示该页已经换出。
激活与禁止交换区
需要注意的是,交换分区的大小设置必须在交换分区尚未激活的状态下。swapon
swapon:激活交换分区(以/dev/zram0为例)。
函数原型:SYSCALL_DEFINE2(swapon, const char __user *, specialfile, int, swap_flags)
在使用gdb调试时,需要断点 sys_swapon 才能断点到该函数。下面是该函数的具体逻辑
struct swap_info_struct *p = alloc_swap_info()分配一个sistruct file *swap_file = file_open_name("/dev/zram0");打开设备节点,获得文件描述符。之前一直以为在kernel里不能打开文件,这里看来并非如此。struct inode *inode = swap_file->f_mapping->host;通过f_mapping可以获得struct file的struct address_space,再通过->host来获得所属于的inode。claim_swapfile(p, inode):声明/dev/zram0被p独占- 通过
S_ISBLK来判断当前inode是否是块设备 - 通过
blkdev_get(p->bdev, O_EXCL, p)来以独占模式打开p->bdev,并说明独占者为p - 通过
set_blocksize(p->bdev, PAGE_SIZE)将设备的块大小设置为一页
- 通过
- 操作
swap_headerpage = read_mapping_page(),读取swap的第一个页;union swap_header *swap_header = kmap(page);获得swap的头unsigned long maxpages = read_swap_header(p, swap_header)返回可以分配的总页数。取决于两点,swap_entry_t中swap offset的bit数,以及pte在不同架构下的长度。
unsinged char *swap_map = vzalloc(maxpages),调用vzalloc来对每一个页槽分配计数值p->cluster_next = prandom_u32() % p->highest_bit,将cluster_next设置为一个随机页槽位置cluster_info = vzalloc(maxpages/SWAP_CLUSTER*sizeof(*cluster_info)):以SWAP_CLUSTER为单位,为所有的页槽分组。p->percpu_cluster = alloc_percpu(struct percpu_cluster)setup_swap_map_and_extents- 遍历
swap_header->info.nr_badpages,为0,掠过 - 遍历所有cluster,
i = maxpages不小于所有cluster的,掠过 - 将第0个
struct swap_cluster_info->data自增1,表示usage counter自增1 setup_swap_extents创建交换子区(swap extents),由于满足S_ISBLK(块设备),仅有一个交换子区- 遍历全部的cluster,并通过cluster->data将它们串起来
- 由于
p->cluster_next是随机的,所以cluster的index也是随机的。这个cluster被赋值给p->free_cluster_head。 - 从
free_cluster_head所在的cluster开始,每个cluster的struct swap_cluster_info->data都等于下一个cluster的index。如果已经是最后一个cluster了则会绕到第0个 - 如果是第0个则跳过(第0个cluster不被使用吗?)
- 由于
- 遍历
调用
enable_swap_info,将当前的swap_info_struct按照prio加入到swap_avail_head。在该函数中,total_swap_pages += p->pages,也就是说该变量等于所有交换分区的页槽数之和。- 成功返回
swapoff(TODO)
try_to_unuse()(TODO)
分配与释放页槽
struct swap_cluster_info {
unsigned int data:24; /* 如果下一个cluster是空闲的则存储在这里 */
unsigned int flags:8; /* 参考下面的define */
};
#define CLUSTER_FLAG_FREE 1 /* This cluster is free */
#define CLUSTER_FLAG_NEXT_NULL 2 /* This cluster has no next cluster */
struct percpu_cluster {
struct swap_cluster_info index; /* Current cluster index */
unsigned int next; /* Likely next allocation offset */
};
一个cluster就是SWAPFILE_CLUSTER(256)个page slot组合在一起的块,所有空闲的cluster将组织在一个链表中。在SSD页槽搜索算法中,为每一个CPU都分配了一个cluster,所以每个cpu都能从它自己的cluster中分配页槽并顺序的swapout,以便增加swapout的吞吐量。
搜索页槽的函数路径为:
kswapd --> balance_pgdat --> kswapd_shrink_zone --> shrink_zone --> shrink_lruvec --> shrink_list --> shrink_inactive_list --> shrink_page_list --> pageout --> shmem_writepage --> get_swap_page --> scan_swap_map
get_swap_page:在该函数中,它会以plist_for_each_entry_safe来遍历swap_avail_head。若仅有一个交换分区,则该list仅有一个元素,所以该函数除了一些合理性判断外,作用就是调用了scan_swap_map:
- 若
scan_swap_map返回非0,则get_swap_page返回对应的swap entry:swp_entry(si->type, offset) - 若返回0,则遍历其他交换分区。由于此处仅有一个交换分区,因此直接返回0。
scan_swap_map,原型为:
static unsigned long scan_swap_map(struct swap_info_struct *si, unsigned char usage),执行逻辑:
由于采用了SSD页槽搜索算法,因此会直接跳入
scan_swap_map_try_ssd_cluster,为当前CPU分配cluster:percpu_cluster->index = si->free_cluster_head,percpu_cluster->next = cluster_next(&si->free_cluster_head),最终通过参数返回offset = si->cluster_next,进入check状态checks状态,对得到的页槽(offset)进行检查,在这里执行的逻辑有:- 如果offset所在页槽已经有人用了(
si->swap_map[offset] != 0),则goto scan,进入扫描状态 si->inuse_pages++- 如果
si->inuse_pages == si->pages,说明已经全部用光,此时将当前si从swap_avail_head中删除,get_swap_page就不会遍历到这个交换分区了 si->swap_map[offset] = usage,此处usage为传入参数SWAP_HAS_CACHEsi->cluster_next = offset + 1,这样下次分配时即可从当前cluster的下一个页槽分配了。si->flags -= SWP_SCANNING,退出分配页槽的状态,返回offset
- 如果offset所在页槽已经有人用了(
scan状态:从当前offset开始遍历整个交换分区- 从当前offset开始,遍历到
si->highest_bit,如果有空闲页槽则进入check状态 - 否则会绕到
si->lowest_bit,遍历到刚刚offset的位置,如果有空闲页槽就进入check状态 - 如果根本找不到空闲页槽,则退出分配页槽状态,返回0
- 从当前offset开始,遍历到
交换高速缓存
向交换区来回传送页会引发很多竞争条件,具体的说,交换子系统必须仔细处理下面的情形:
- 多重换入:两个进程可能同时要换入同一个共享匿名页
- 同时换入换出:一个进程可能换入正由PFRA换出的页
交换高速缓存(swap cache)的引入就是为了解决这类同步问题的。关键的原则是,没有检查交换高速缓存是否已包含了所涉及的页,就不能进行换入或换出操作。有了交换高速缓存,涉及同一页的并发交换操作总是作用于同一个页框的。因此,内核可以安全的依赖页描述符的PG_locked标志,以避免任何竞争条件。
考虑一下共享同一换出页的两个进程这种情形。当第一个进程试图访问页时,内核开始换入页操作,第一步就是检查页框是否在交换高速缓存中,我们假定页框不在交换高速缓存中,那么内核就分配一个新页框并把它插入到交换高速缓存,然后开始I/O操作,从交换区读入页的数据;同时,第二个进程访问该共享匿名页,与上面相同,内核开始换入操作,检查涉及的页框是否在交换高速缓存中。现在页框是在交换高速缓存,因此内核只是访问页框描述符,在PG_locked标志清0之前(即I/O数据传输完毕之前),让当前进程睡眠。
当换入换出操作同时出现时,交换高速缓存起着至关重要的作用。shrink_list()函数要开始换出一个匿名页,就必须当try_to_unmap()从进程(所有拥有该页的进程)的用户态页表中成功删除了该页后才可以。但是当换出的页写操作还在执行的时候,这些进程中可能有某个进程要访问该页,而产生换入操作。在写入磁盘前,待换出的页由shrink_list()存放在交换高速缓存。考虑页由两个进程(A和B)共享的情况。最初,两个进程的页表项都引用该页框,该页有两个拥有者。当PFRA选择回收页时,shrink_list()把页框插入交换高速缓存。然后PFRA调用try_to_unmap()从这两个进程的页表项中删除对该页框的引用。一旦这个函数结束,该页框就只有交换高速缓存引用它,而引用页槽的有这两个进程和交换高速缓存。假如正当页中的数据写入磁盘时,进程B又访问该页,即它要用该页内部的线性地址访问它,那么缺页异常处理程序会发现页框正在交换高速缓存中,并把物理地址放回进程B的页表项。如果上面并发的换入操作没发生,换出操作结束,则shrink_list()会从交换高速缓存删除该页框并把它释放到伙伴系统。
可以认为交换高速缓存是一个临时区域,该区域存有正在被换入或换出的匿名页描述符。当换入或换出结束时(对于共享匿名页,换入换出操作必须对共享该页的所有进程进行),匿名页描述符就可以从交换高速缓存删除。
交换高速缓存的实现:
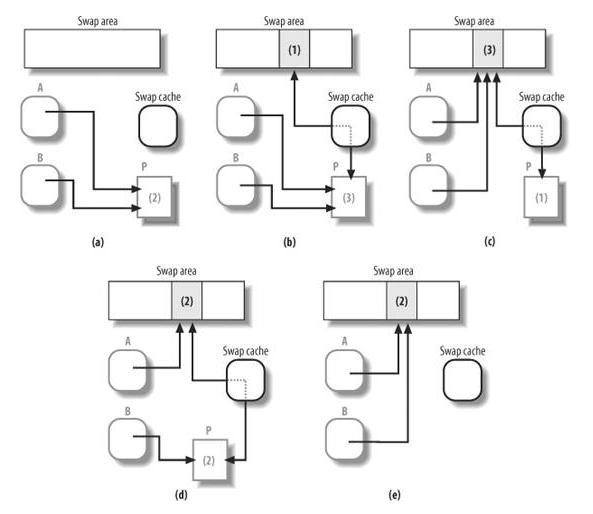
交换高速缓存由页高速缓存数据结构和过程实现。页高速缓存的核心就是一组基数树,基数树算法可以从address_space对象地址(即该页的拥有者)和偏移量值推算出页描述符的地址。
在交换高速缓存中页的存放方式是隔页存放,并有如下特征:
- 页描述符的mapping字段为null
- 页描述符的
PG_swapcache标志置位 - private字段存放于该页有关的换出页标识符
此外,当页被放入交换高速缓存时,页描述符的count字段和页槽引用计数器的值都会增加,因为交换高速缓存既要使用页框,也要使用页槽。
最后,交换高速缓存中的所有页只使用struct address_space swapper_spaces[MAX_SWAPFILES],因此只有一个基数树(由struct address_space.page_tree指向)对交换高速缓存中的页进行寻址。struct address_space.nrpages则用来存放交换高速缓存中的页数。
插入交换高速缓存的函数为__add_to_swap_cache(),主要执行步骤为:
- 调用
get_page(),增加该page的引用计数_mapcount(或称_refcount) - 置位
PG_swapcache - 将
page->private设置为页槽索引 - 调用
swap_address_space()从上面的swapper_spaces中获得address_space。 - 调用
radix_tree_insert()将页插入到基数树中(address_space->page_tree)
页换出
第一步,准备交换高速缓存。如果shrink_page_list()函数确认某页为匿名页(PageAnon()函数返回1)而且交换高速缓存中没有相应的页框(页描述符的PG_swapcache标志为0),内核就调用add_to_swap()函数。该函数会在交换区分配一个页槽,并把一个页框(其页描述符作为参数传递进来)插入交换高速缓存。函数主要执行步骤如下:
- 调用
get_swap_page()分配一个新的页槽,如果失败则返回0 - 调用
add_to_swap_cache(),插入基数树
第二步,更新页表项。通过调用try_to_unmap()来确定引用了该匿名页的每个用户态页表项的地址,然后将换出页标识符写入其中。大概调用过程就是
try_to_unmap()remap_walk()remap_walk_anon()–>rwc->remap_one()try_to_unmap_one,通过page->private获得entry,构造出一个swp_pteset_pte_at(),将swp_pte设置给pte
第三步,将数据写入交换区。在这一步里会检查页是否是脏页(PG_dirty是否置位,为什么仅针对脏页?是因为没写的也可以直接被释放吗?)。如果是,则pageout()将会被执行。其具体逻辑为:
调用
is_page_cache_freeable()判断该页的引用数,除了调用者、基数树(即swapcache)之外,还可能有某些buffer在引用该页(此时page的PG_private或PG_private2必定有置位)。如果并非如此就退出pageout()如果页的mapping为空则,要么退出
pageout(),要么该页属于buffer。通过page_has_private()来判断是否如此。如果是的话,则通过try_to_free_buffer()来释放缓冲区(这个缓冲区是文件系统缓冲,具体逻辑还需要研究)清零
PG_dirty,pageout()回调page->mapping->a_ops->writepage(),而page的mapping指向全局变量swapper_spaces数组中某元素(任一元素都相同),从而调用swap_writepage,具体逻辑为:- 在
try_to_free_swap()中调用page_swapcount()检查是否至少有一个用户态进程引用该页。有趣的是,这里并不检查`page->_mapcount`,而是检查对应的页槽的引用计数。如果引用数为0,则将swapcache删除(从基数树中删除页框索引) - 调用
__swap_writepage,传入bio_end_io_t类型的回调函数end_swap_bio_write()- 首先检查交换分区有无
SWP_FILE,即是否正常开启并运行中。zram交换分区标志为0x53,并无此标志。(具体见swap_info_struct->flags的描述) - 调用
bdev_write_page(),向块设备中写入指定页。参数有:struct swap_info_struct->bdev(在zram中,zram_rwpage等函数都注册在这个block device的opts中)、page所对应的sector、要交换的page。进入该函数时,页被锁住且PG_writeback不置位,退出时状态相反。期间通过bdev->bd_disk->fops->rw_page回调zram_rw_page。
- 首先检查交换分区有无
- 在
第四步,将page释放。取消PG_locked。并将page->lru加入到free_pages。最后,数组free_pages会被free_hot_cold_page_list()释放,而交换不成功的页则要被putback
页换入
当进程试图对一个已被换出的页进行寻址时,必然会发生页的换入。在以下条件全满足时,缺页异常处理程序会触发一个换入操作,关于这个部分的详细说明,在进程地址空间的寻址中有详细说明:
- 引起异常的地址所在的页是一个有效的页,也就是说,它属于当前进程的一个线性区
- 页不在内存中,也就是页表项的Present标志被清除
- 与页有关的页表项不为空,但是
PG_dirty位被清零,意味着页表项乃是一个换出页标识符
Zram 交换技术
zram即是上文提及的交换区的一种实现,与传统交换区实现的不同之处在于,传统交换区是将内存中的页交换到磁盘中暂时保存起来,发生缺页的时候,从磁盘中读取出来换入。而zram则是将内存页进行压缩,仍然存放在内存中,发生缺页的时候,进行解压缩后换入。根据经验,LZO压缩算法一般可以将内存页中的数据压缩至1/3,相当于原本三个页的数据现在一个页就能存下了,赚到了两个页,从而使可用内存感觉起来变多了。
Zram 基本操作:
对zram的设置,必须在交换区未激活的状态下执行:
echo 3 > /sys/block/zram0/max_comp_streams
echo $((400*1024*1024)) > /sys/block/zram0/disksize
创建交换区,详细见mkswap:
mkswap /dev/block/zram0
激活交换区:
swapon /dev/block/zram0
关闭交换区:
swapoff /dev/zram0
Zram 中主要的数据结构
struct size_class及struct zspage:
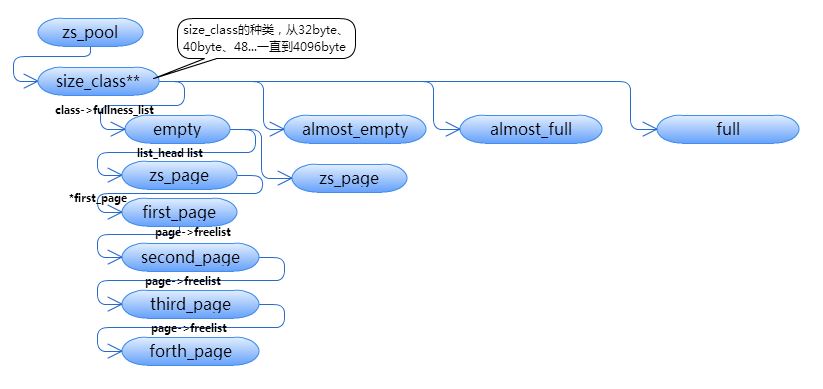
Zram 使用了__alloc_page()接口来整页整页的获取内存。一般情况下,我们会将页再次划分,以保证其内存被充分的使用尽量少的产生内存碎片。但是,由于来自用户的页被压缩后,其大小在[0, 4096]范围内是随机的。那么将页分配为多大都不合适。
因此,Zram将内存页进行了不同大小的划分,大小的范围是[32byte, 4096byte],间隔8byte,也就是32byte、40byte、48byte直到4096byte。对于压缩后不足32byte的也使用32byte单位的页来存储。Zram使用了struct size_class类型来表示它们。其定义为:
struct size_class {
spinlock_t lock;
struct page *fullness_list[_ZS_NR_FULLNESS_GROUPS];
/*
* Size of objects stored in this class. Must be multiple
* of ZS_ALIGN.
*/
int size;
unsigned int index;
/* Number of PAGE_SIZE sized pages to combine to form a 'zspage' */
int pages_per_zspage;
struct zs_size_stat stats;
/* huge object: pages_per_zspage == 1 && maxobj_per_zspage == 1 */
bool huge;
};
可是这种办法还是有一个缺陷:每个页最末尾的,不足一个单位大小的内存被浪费了。此时选择的办法是,将几个页联合起来(最多四个页),选择浪费最少的方案:
struct zs_pool *zs_create_pool(const char *name, gfp_t flags) {
for (i = zs_size_classes - 1; i >= 0; i--) {
size = ZS_MIN_ALLOC_SIZE + i * ZS_SIZE_CLASS_DELTA;
pages_per_zspage = get_pages_per_zspage(size);
class->pages_per_zspage = pages_per_zspage;
}
...
}
static int get_pages_per_zspage(int class_size) {
for (i = 1; i <= ZS_MAX_PAGES_PER_ZSPAGE; i++) {
int zspage_size;
int waste, usedpc;
zspage_size = i * PAGE_SIZE;
waste = zspage_size % class_size;
usedpc = (zspage_size - waste) * 100 / zspage_size;
if (usedpc > max_usedpc) {
max_usedpc = usedpc;
max_usedpc_order = i;
}
}
return max_usedpc_order;
}
这几个联合起来的page,被称为zspage。在一个zspage中,至少包含一个page,最多有4个page。 他们的特征是:
- 第一个页的
struct page->flags中有PG_private标记 - 最后一个页的
struct page->flags中有PG_private2标记 - 每个页之间用
struct page->freelist相互串联起来(第一个页的freelist指向第二个页,第二个指向第三个…)
还有一个问题需要被考虑:当某个级别上的zspage被写满了,该怎么记录他们呢?
这时在struct size_class中,引入了fullness_list。fullness_list共有四个指针,分别指向完全空、基本空、基本满和完全满的zspage list,当分配zram存储单位时(zs_object),按照基本满->基本空->完全空的顺序,释放的时候,则会遵从完全满->基本满->基本空->完全空的顺序。在完全空的时候,zs_free()才会调用free_zspage()对zspage进行释放。
zspage的内存存储结构与zs_object
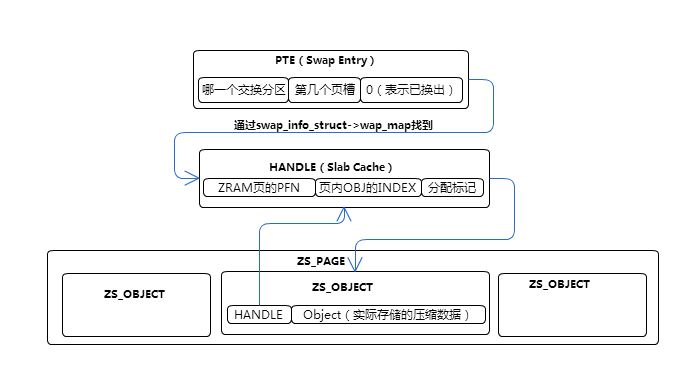
Zram会将zspage按照固定大小进行分割,而每一个单元就被称为一个zs_object。一个zs_object分为两个部分,第一个部分是一个头,其内容是一个指向某个slab对象的指针handle;第二部分则是实际上的压缩数据。上图所示的,是一个zs_object与pte之间的关系:
pte通过交换分区+页槽值可以找到当前这个pte被存储到了哪个页槽上。通过页槽值及swap_map数组找到在zram内存存储的位置。其位置为某个页的pfn+页内的zs_object的index。
换出到Zram交换分区
static int zram_bvec_write(struct zram *zram, struct bio_vec *bvec, u32 index, int offset)
{
struct page *page = bvec->bv_page;
zcomp_compress(zram->comp, zstrm, uncmem, &clen);
zs_malloc(meta->mem_pool, clen);
zs_get_total_pages(meta->mem_pool);
unsigned char * cmem = zs_map_object(meta->mem_pool, handle, ZS_MM_WO);
copy_page(cmem, src);
}
zram_bvec_write()主要过程为:
- 调用
zcomp_compress将源数据压缩 - 调用
zs_malloc从zram分配一块内存(zs_object) - 调用
zs_map_object映射zs_object - 调用
memcpy把压缩数据拷贝到zs_object
zs_malloc:
该函数的作用是根据调用者提供的大小,分配出合适大小的zs_object以便存储压缩数据。
unsigned long zs_malloc(struct zs_pool *pool, size_t size) {
first_page = find_get_zspage(class);
if (!first_page) {
first_page = alloc_zspage(class, pool->flags);
set_zspage_mapping(first_page, class->index, ZS_EMPTY);
}
obj = obj_malloc(first_page, class, handle);
}
具体流程如下:
- 调用
find_get_zspage找到基本满或者基本空的zspage - 如果没有找到,则分配新的zspage
- 将这个zspage以指定大小划分,每个单位的头部为i++
- 将几个page连起来
- 从zspage中获得第一个没有被使用的
zs_object并返回
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
