

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
SSDAlloc:用 SSD 扩展内存
by Chen Jie of TinyLab.org 2014/10/05
前言
IPhone 6 面世,其内存容量维持了 1GB 的大小。据一些分析,更大的内存带来了能耗增加,是苹果不愿贸然使用大内存的一个原因。如今,不仅嵌入式设备对能耗格外关注,数据中心也开始重视能耗问题,例如尝试基于 ARM 的服务器来降低能耗。数据中心通常也装备许多内存,然而部署大量内存不仅价格不菲,更消耗大量能源。
某次在企业存储工程师的职位描述中看到 SSDAlloc,细查了下,SSDAlloc 是用 SSD 来扩展内存的一种方法,典型应用场景为类 memcache 的数据缓冲应用。采用 SSD 来扩展内存,不仅能用较低成本获得巨大容量,更有益于减少能耗。
说到这不禁要问,直接用 SSD 做 swap 不就行了,为啥还要整一个 SSDAlloc ?答案是 SSDAlloc 性能要好太多。作 swap 时,内容的读取和改动是以页为单位 —— 读写页内一点点数据,要整页读取,整页写入 —— 不仅消耗了 SSD 读写带宽,写操作更会影响其使用寿命。
以下两图来自 SSDAlloc 的幻灯。
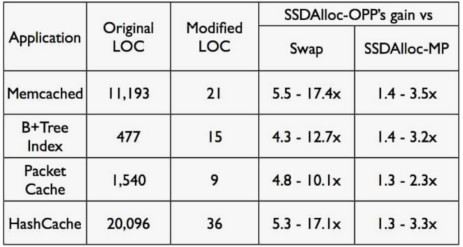
图1:列出了一些常见缓冲应用,迁移到 SSDAlloc 所需代价及所获的收益。可以看到与 swap 相比,性能提升幅度在5倍至10倍左右。
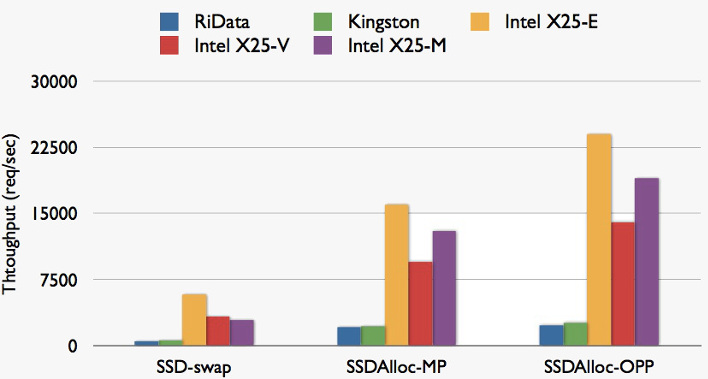
图2:不同型号 SSD 的吞吐量测试,可以看到与 swap 相比的性能巨大增幅。
SSDAlloc 简介
SSDAlloc 的核心是围绕着 OOP(Object Per Page) 模型来展开的,即每个内存页最多放一个对象。对于小于页尺寸的对象,将其置于内存页头部,其余部分留空。大于页尺寸的对象类似,只是占据多个页。通过 OPP 可以借助内存保护机制,区分出对单个对象的读写,从而减少 SSD 层面的读和写。
使用 SSDAlloc 时,仅需将 malloc 等内存分配/释放函数调用替换成 SSDAlloc 的内存分配/释放函数即可。另一个需要修改的地方与数组有关:对于 OPP 数组,其中元素的起始地址间隔为一页大小。
另一方面,采用 OPP 模型对内存使用似乎极为浪费。这里所说的浪费,分为两方面。一是虚拟地址空间的浪费,随着64位计算的进一步普及,这点浪费不算什么。另一方面是物理内存的浪费,为解决这个问题,引入两组件:
- Page Buffer:这是用 FIFO 队列组织起来的所有 OPP 页面。这部分由于是 OPP 方式的,故较浪费物理内存。
- RAM Object Cache:紧致排列的对象。
在实测中 Page Buffer 大小设定在 25MB 以下就有非常好的性能。当 Page buffer 满了以后,按照先入先出序,老的 OPP 中的对象被赶出,页中的有效数据被塞入 RAM Object Cache。RAM Object Cache也在内存中,但其对象排列是紧致的。
从某个角度而言,RAM Object Cache 像是“压缩”的数据,而 Page Buffer 则为“解开”的数据。“解开”是为了处理数据,这里所谓的“处理”一个主要方面是侦测对象的读和写。
下图为 SSDAlloc 的一个总览,图来自 SSDAlloc 的幻灯。
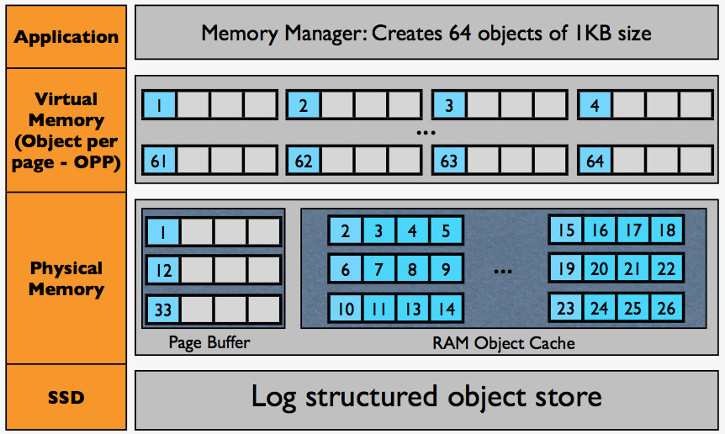
图3:SSDAlloc 结构总览
上图可见,SSDAlloc 分成若干层:
- 应用程序和虚拟内存层。主要是一组内存管理器来分配虚拟地址空间。图中例子为分配了 64 个 1KB 的对象。
- 物理内存层。包含 Page Buffer 和 RAM Object Cache 哥倆的运行时刻。图中展示了在 Page Buffer 中,按照 OPP 模型,对象是怎样映射到物理内存页面上的。以及紧致排列在 RAM Object Cache 中。
- SSD 层。使用对 SSD 友好的日志结构来存储对象。当 RAM Object Cache 满了以后,脏对象被“驱逐”到 SSD 上。
以下按照 SSDAlloc 使用中各个环节来进一步细述。
分配与释放
SSDAlloc 有两类主要的内存管理器,一类是“池”方式的,另一类则是“合并”(coalescing)方式的。“合并”方式主要用来分配 OPP 数组,是一种 ptmalloc 风格(C 库 malloc 也是)的内存管理器。大概的意思是指释放时,和附近挨着的空闲空间合并成较大的块头。同时,每个物理内存页头部会放入一些元数据(例如链表指针之类的),有效数据紧随其后。
以下重点来看最为常用的“池”方式的内存管理器,如下图: 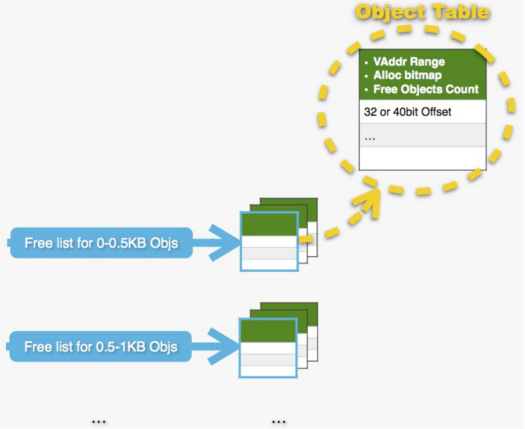
图4:SSDAlloc 的“池”方式内存管理器示意
分配对象所需空间时,按照分配申请的大小,从对应的“池”中(Freelist)分配。例如分配 0.6KB 尺寸的对象时,从对应 0.5-1KB 的“池”中取。
注意,内存管理器分配的是虚拟地址空间,这里:
- 每个“池”对应的存储尺寸范围,以 0.5KB 为进步。
- 每个“池”对应一组 Object Table(s),但只激活一个 Object Table。
- 初始时,每个“池”对应一个 Object Table,这个 Object Table 含有 128 个对象所占虚拟地址空间(虚拟地址范围)。
- 用完以后,翻倍扩充“池”。例如开始“池”中128个“槽”被用完后,建立含有 256 个对象所占虚拟地址空间的 Object Table,并激活之。
- 直至 10000(可配置),之后按照每次加 10000 来扩充“池”。
- 关于 Object Table:
- 拥有 OTID(Object Table ID)。
- 存于内存中。
- 一个 Object Table 对应了一个虚拟地址范围。
- Alloc bitmap 指示了其分配情况。
- Free Objects Count 指示了本表可分配项。某次分配无法从对应的当前“池”满足时,拥有最大 Free Object Count 的 Object Table 被激活,或建立新的 Object Table(见上)并激活。
读与写
当试图访问某对象发生缺页错误,即该对象不在 Page Buffer 中,则试图从 RAM Object Cache 中查询并填充对应页。查询过程为一个哈希表查询,查询键为虚拟地址。如下图所示:
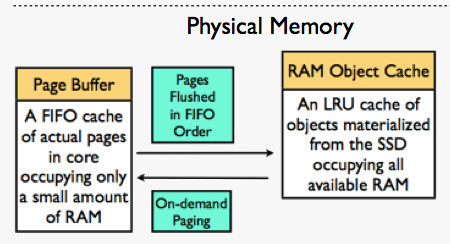
图5:SSDAlloc 处理缺页时,首先试图从 RAM Object Cache 中满足需求。图同时还说明 Page Buffer 采用先入先出序来驱逐“旧”数据到 RAM Object Cache 中。该图据《SSDAlloc Hybrid SSD/RAM Memory Management Made Easy》文中配图微调。
当请求页面不在 RAM Object Cache 中时,需要从 SSD 上读取,即定位其在 SSD 上扇区号(offset)并读入,过程如下:
- 查询 ATM(Address Translation Module)。ATM 是一个在内存中的平衡二叉树,查找发生缺页的虚拟地址所在虚拟地址范围(key),从而找到 OTID(Value)。
- 通过发生缺页的虚拟地址,获得对应对象的起始虚拟地址。再通过该地址相对虚拟地址范围的偏移,可得对应的 OTO(Object Table Offset)。
- 通过 OTID 得到 Object Table(数组),进而通过 OTO 来获得数组中对应项,项中内容为扇区号。
- 每个扇头两字节存了首个在本扇区开头的对象的偏移。由于每个对象大小、所属 记录到元数据中,于是进一步遍历可以定位对象。
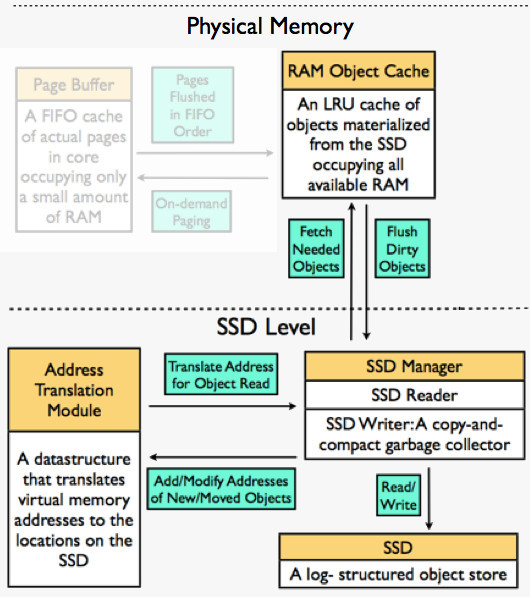
图6:SSDAlloc 处理缺页时,页面不在 RAM Object Cache 中,此时进一步从 SSD 层取得。该图据《SSDAlloc Hybrid SSD/RAM Memory Management Made Easy》文中配图微调。
当首次写一个对象时,还会将对象标记为脏,脏对象被赶出 RAM Object Caches时,需要刷到 SSD 上。刷的过程:
- 在积累一定数量的脏对象时触发。在日志结构头部读取足够数量,部分填充的块。
- 塞入脏对象一起写入新的位置上。
- 每个 SSD 上存储的对象有如下元数据 ,这是个反向指针,用来更新 Object Table 对应项(因为写到了新位置上)。同时也用来确定该对象是否已被释放。
- 为减少 SSD 的读请求,在内存中维持每 128KB 块的可用空间总量计数。
小结
至此,我们粗略看了下 SSDAlloc 全貌。
几个说明:
- SSDAlloc 已申请专利,专利公开号:US20120239871 A1。
- 本文内容主要源自《SSDAlloc: Hybrid SSD/RAM Memory Management Made Easy》。
以下来进一步 YY 下。首先,SSDAlloc 能加入手机等移动设备的“豪华午餐”吗?例如 App 切换中,使用 SSD 扩展的内存来保存相关上下文。
App 被切换移出时,需保存会话及相关的数据,例如操作路径的栈(按下后退键出栈);对于线视频播放 App ,还可能有播放进度,当前播放帧的预览图,已下载的缓冲等等。这样当 App 被再次切回时,用户可以继续先前会话。这些会话及其相关数据,都可以存在融入 SSDAlloc 技术的内存缓冲。
关于 SSDAlloc,有一点未提及,即其“持久性框架(Durability Framework)”。即 SSDAlloc 相关全数据可以保存在 SSD 上,从而使状态跨越重启。这样,在例如系统更新不得不重启手机等移动设备,之后,用户的各 App 会话还能继续:打开 youku 还从重启前观看的视频进度处开始,游戏还在之前玩了一半的关卡处暂停,之前打开的网页还继续开着… —— 该特性并不需要每个 App 实现自己的会话保存功能,而是利用基于 SSDAlloc 技术、系统提供的某种框架即可。
最后来 YY 的一点,源自对安装 Linux 时决定 swap 分区大小的厌恶。SSDAlloc 同样需要一个 SSD 存储区域来支撑,这个区域,推测起来,应该不是文件,而是分区的块设备。这样,又回到了这个该死的问题 —— 预留多少呢?
另一方面,SSDAlloc 在块层使用日志结构来减少写次数,这实际上是和 flash 友好的文件系统(例如现在很火的 F2FS)是类似的思路。那么,是否可以将 SSDAlloc 的 SSD 相关部分结合到文件系统中?
如此,除了代码复用以外,我们再也不用担心类似 swap 分多少合适的问题了。同时,块的写操作在整个文件系统循环,有助于更好地平均各块写寿命。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
