

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
一次性能 BUG 分析之旅:大量 D 进程卡在 shrink_inactive_list
Bai Haowen 创作于 2020/01/07
By Lotte of TinyLab.org Dec 23, 2019
Description
一个项目中偶现几十上百个 D 进程卡住在 shrink_inactive_list,导致卡顿/卡死/Android SWT 等问题,前前后后,提交了 3 次修复,还没有彻底解决。
Analysis
LOG:
[149459.897408] [3:2065:watchdog] Binder:1042_16 D 0 9917 635 0x00000008
[149459.897427] [3:2065:watchdog] Call trace:
[149459.897435] [3:2065:watchdog] [<ffffff8bf28852d4>] _switch_to+0xb4/0xc0
[149459.897452] [3:2065:watchdog] [<ffffff8bf3a1f6a0>] _schedule+0x7f0/0xad0
[149459.897468] [3:2065:watchdog] [<ffffff8bf3a1f9f0>] schedule+0x70/0x90
[149459.897485] [3:2065:watchdog] [<ffffff8bf3a23b00>] schedule_timeout+0x548/0x668
[149459.897502] [3:2065:watchdog] [<ffffff8bf2959028>] msleep+0x28/0x38
[149459.897517] [3:2065:watchdog] [<ffffff8bf2a1ff38>] shrink_inactive_list+0x118/0x998
[149459.897534] [3:2065:watchdog] [<ffffff8bf2a1cb10>] shrink_node_memcg+0xa18/0x1100
[149459.897552] [3:2065:watchdog] [<ffffff8bf2a1f0b0>] shrink_node+0x108/0x2f8
[149459.897568] [3:2065:watchdog] [<ffffff8bf2a1bcb0>] do_try_to_free_pages+0x178/0x380
[149459.897586] [3:2065:watchdog] [<ffffff8bf2a1b9d0>] try_to_free_pages+0x370/0x4d8
[149459.897605] [3:2065:watchdog] [<ffffff8bf2a071b8>] _alloc_pages_nodemask+0x868/0x1380
[149459.897623] [3:2065:watchdog] [<ffffff8bf2a13784>] __do_pagecache_readahead+0xbc/0x358
[149459.897640] [3:2065:watchdog] [<ffffff8bf29fde4c>] filemapfault+0x11c/0x600
[149459.897647] [3:2065:watchdog] [<ffffff8bf2b479f8>] ext4_filemap_fault+0x30/0x50
[149459.897664] [3:2065:watchdog] [<ffffff8bf2a47f38>] handle_pte_fault+0xb38/0xfa8
[149459.897681] [3:2065:watchdog] [<ffffff8bf2a485c8>] handle_mm_fault+0x1d0/0x328
[149459.897699] [3:2065:watchdog] [<ffffff8bf28a3668>] do_page_fault+0x2a0/0x3e0
[149459.897716] [3:2065:watchdog] [<ffffff8bf28a3364>] do_translation_fault+0x44/0xa8
[149459.897732] [3:2065:watchdog] [<ffffff8bf2880b74>] do_mem_abort+0x4c/0xd0
[149459.897750] [3:2065:watchdog] [<ffffff8bf2882c78>] el0_da+0x20/0x24
[149459.897767] [3:2065:watchdog] Binder:1042_19 D 0 11188 635 0x00000008
[149459.897786] [3:2065:watchdog] Call trace:
[149459.897797] [3:2065:watchdog] [<ffffff8bf28852d4>] _switch_to+0xb4/0xc0
[149459.897804] [3:2065:watchdog] [<ffffff8bf3a1f6a0>] _schedule+0x7f0/0xad0
[149459.897820] [3:2065:watchdog] [<ffffff8bf3a1f9f0>] schedule+0x70/0x90
[149459.897835] [3:2065:watchdog] [<ffffff8bf3a23b00>] schedule_timeout+0x548/0x668
[149459.897853] [3:2065:watchdog] [<ffffff8bf2959028>] msleep+0x28/0x38
[149459.897868] [3:2065:watchdog] [<ffffff8bf2a1ff38>] shrink_inactive_list+0x118/0x998
[149459.897887] [3:2065:watchdog] [<ffffff8bf2a1cb10>] shrink_node_memcg+0xa18/0x1100
[149459.897904] [3:2065:watchdog] [<ffffff8bf2a1f0b0>] shrink_node+0x108/0x2f8
[149459.897922] [3:2065:watchdog] [<ffffff8bf2a1bcb0>] do_try_to_free_pages+0x178/0x380
[149459.897940] [3:2065:watchdog] [<ffffff8bf2a1b9d0>] try_to_free_pages+0x370/0x4d8
[149459.897957] [3:2065:watchdog] [<ffffff8bf2a071b8>] __alloc_pages_nodemask+0x868/0x1380
[149459.897977] [3:2065:watchdog] [<ffffff8bf2a13784>] _do_page_cache_readahead+0xbc/0x358
[149459.897996] [3:2065:watchdog] [<ffffff8bf29fde4c>] filemap_fault+0x11c/0x600
[149459.898013] [3:2065:watchdog] [<ffffff8bf2b479f8>] ext4_filemap_fault+0x30/0x50
[149459.898031] [3:2065:watchdog] [<ffffff8bf2a47f38>] handle_pte_fault+0xb38/0xfa8
[149459.898048] [3:2065:watchdog] [<ffffff8bf2a485c8>] handle_mm_fault+0x1d0/0x328
[149459.898065] [3:2065:watchdog] [<ffffff8bf28a3668>] do_page_fault+0x2a0/0x3e0
[149459.898083] [3:2065:watchdog] [<ffffff8bf28a3364>] do_translation_fault+0x44/0xa8
[149459.898100] [3:2065:watchdog] [<ffffff8bf2880d18>] do_el0_ia_bp_hardening+0xc0/0x158
[149459.898118] [3:2065:watchdog] [<ffffff8bf2882c98>] el0_ia+0x1c/0x20
现象:大量进程从缺页异常入口,调用内存回收接口: shrink_inactive_list -> msleep,使得该进程状态变为 D.
void msleep(unsigned int msecs)
{
unsigned long timeout = msecs_to_jiffies(msecs) + 1;
while (timeout)
timeout = schedule_timeout_uninterruptible(timeout);
}
signed long __sched schedule_timeout_uninterruptible(signed long timeout)
{
__set_current_state(TASK_UNINTERRUPTIBLE);
return schedule_timeout(timeout);
}
D 进程就是被设置了 TASK_UNINTERRUPTIBLE 进程状态,不可中断的睡眠状态。不可中断,指的并不是 CPU 不响应外部硬件的中断,而是指进程不响应异步信号,信号只会挂到信号队列,而没有机会去立即执行。它不占用 cpu,也不能被杀掉,很直观的现象就是,kill -9 一个 D 进程,是没有效果的,只有等进程获得资源被唤醒才处理信号,才处理 SIGKILL。
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
......
while (unlikely(too_many_isolated(pgdat, file, sc, stalled))) {
if (stalled)
return 0;
/* wait a bit for the reclaimer. */
msleep(100); ////////////////////// 卡在这里
stalled = true;
/* We are about to die and free our memory. Return now. */
if (fatal_signal_pending(current))
return SWAP_CLUSTER_MAX;
}
......
初步定位
该函数已经有跳出功能,不会一直卡住,最多 2 次就会退出去。
说明是大量的进程疯狂地调用 shrink_inactive_list 又被阻塞了一下子,又退出去,又掉进来。所以,不是一直卡死,而是性能瓶颈拥堵在这个地方,congestion.
从上层 systrace 也能看到,很有规律的大概 110ms 一段的 D 状态,一个进程甚至可以持续几十秒。
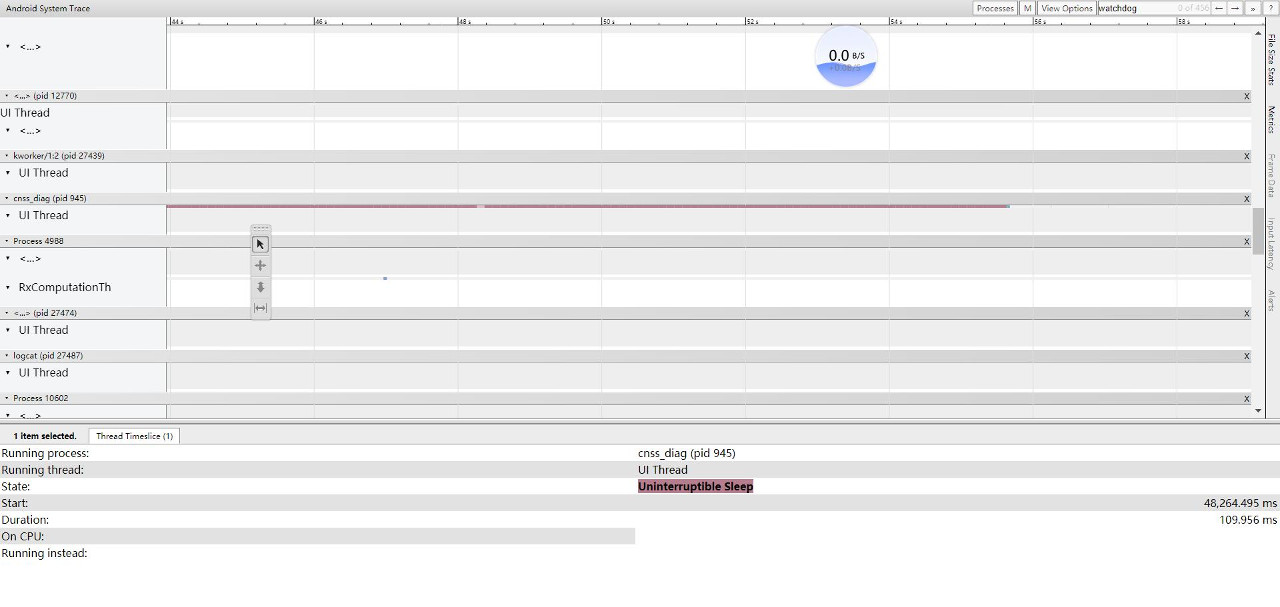
说明隔离页面过多,sleep 100ms,猜测目的是:
- 给时间处理隔离页面,回写文件页到磁盘
- 是控制并发,也许另一个 cpu 也在同样的回收流程导致隔离页这在时刻变大。
所以初步定了两个方向,疑点:
- 内存回收瓶颈,内存回收不及时,内存需求量巨大,而 LMK 没触发,内存有很多匿名页,都在回收和回写文件页等。
- io 读写瓶颈,io 速率慢,某个时间段速率变慢,ufs 频率低,上层读写大量数据,io 占用率过高等。
需要澄清这些疑点,插播一些背景知识.
page cache
导致这个情况的原因是:进程在申请内存的时候,发现该 zone 的 freelist 上已经没有足够的内存可用,所以不得不去从该 zone 的 LRU 链表里回收 inactive 的page,这种情况就是 direct reclaim(直接回收)。direct reclaim 会比较消耗时间的原因是,如果回收的是 dirty page,就会触发磁盘 IO 的操作,它会首先把 dirty page 里面的内容给回写到磁盘作同步,再去把该 page 给放到 freelist 里。
下图来看下 memory,page cache,Disk I/O 的关系。
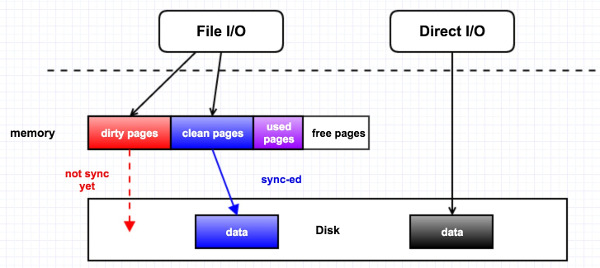
举个简单的例子,比如我们 open 一个文件时,如果没有使用 O_DIRECT 这个flag,那就是 File I/O, 所有对磁盘文件的访问都要经过内存,内存会把这部分数据给缓存起来;但是如果使用了 O_DIRECT 这个flag,那就是 Direct I/O, 它会绕过内存而去直接访问磁盘,访问的这部分数据也不会被缓存起来,自然性能上会降低很多。
page reclaim
在直观上,我们有一个认知,我们现在读了一个文件,它会被缓存到内存里面,如果接下来的一个月我们一直都不会再次访问它,而且我们这一个月都不会关闭或者重启机器,那么在这一个月之后该文件就不应该再在内存里头了。这就是内核对 page cache 的管理策略:LRU(最近最少使用)。即把最近最少使用的 page cache 给回收为 free pages。(页框回收算法 PFRA 远没有这么简单)
内核的页回收机制有两种:后台周期性回收和直接回收。
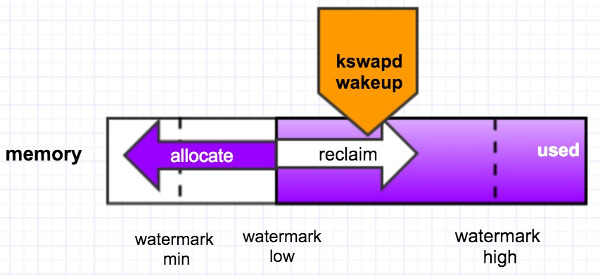
后台回收
有一个内核线程 kswapd 来做,当内存里 free 的 pages 低于一个水位(page_low)时,就会唤醒该内核线程,然后它从 LRU 链表里回收 page cache 到内存的 free_list 里头,它会一直回收直至 free 的 pages 达到另外一个水位 page_high 才停止. 如下图所示,
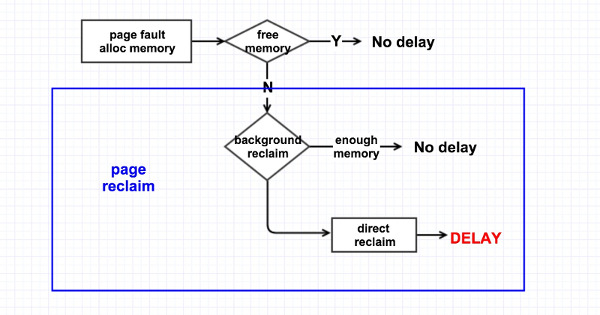
直接回收
在发生 page fault/alloc memory 时,没有足够可用的内存,于是线程就自己直接去回收内存,它一次性的会回收 32 个 pages。逻辑过程如下图所示,
所以,在内存优化上:
- 抬高 watermark 可以间接减少内存回收的并发量,减轻卡在 shrink_inactive_list.
- 提高回收效率,如 LMK 的效率。
然而,还是没彻底解决这个问题,所以我们把疑点再次指向 io。
尝试抓取更多的信息,来了解触发瓶颈的微观过程。
- 跑 monkey 增加 io 使用率、io 读写速度监控,以时间片为 100ms,监控连续 D 状态,并收集 D 进程堆栈信息、内存信息等。
- 打开 ftarce 的 vmscan 和 writeback 两个监控点,apk 监控到持续 D 状态就进dump,从 dump 解析 ftrace,再使用 kernelshark 来观察一些数据。
echo 1 > /sys/kernel/debug/tracing/events/writeback/enable
echo 1 > /sys/kernel/debug/tracing/events/vmscan/enable
echo 1 > /sys/kernel/debug/tracing/tracing_on
为了准备再深入上述的微观过程,需要再补充一些代码和流程图:
- memory reclaim
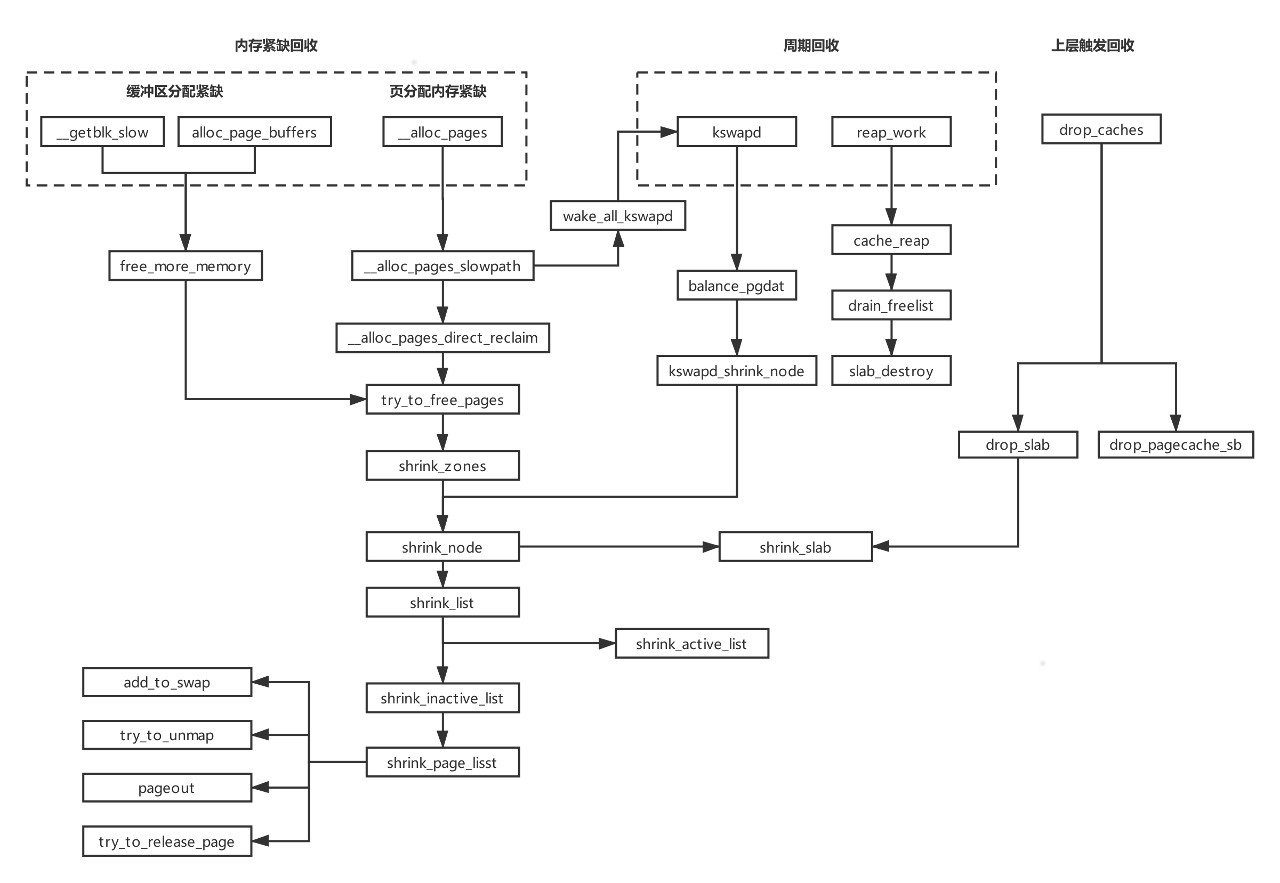
- shrink_inactive_list
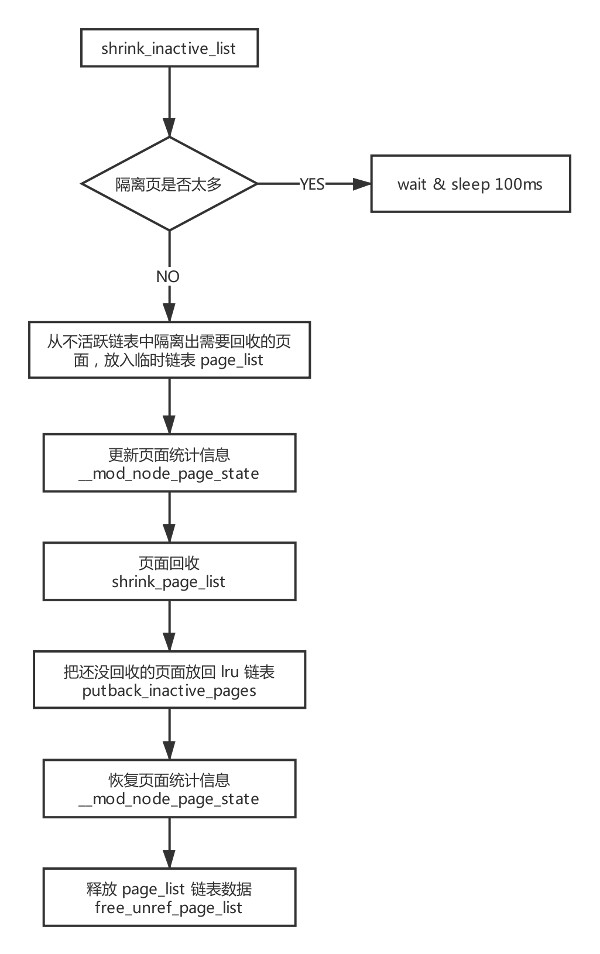
收缩不活跃链表:
/*
* shrink_inactive_list() is a helper for shrink_node(). It returns the number
* of reclaimed pages
*/
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
LIST_HEAD(page_list);
unsigned long nr_scanned;
unsigned long nr_reclaimed = 0;
unsigned long nr_taken;
struct reclaim_stat stat = {};
isolate_mode_t isolate_mode = 0;
int file = is_file_lru(lru);
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
struct zone_reclaim_stat *reclaim_stat = &lruvec->reclaim_stat;
bool stalled = false;
while (unlikely(too_many_isolated(pgdat, file, sc))) { // 如果隔离的页太多就进入睡眠
if (stalled)
return 0;
/* We are about to die and free our memory. Return now. */
if (fatal_signal_pending(current))
return SWAP_CLUSTER_MAX;
/* wait a bit for the reclaimer. */
msleep(100);
stalled = true;
}
// 将 lru 缓存中的页移到各个 lru 链表中去
lru_add_drain();
if (!sc->may_unmap)
isolate_mode |= ISOLATE_UNMAPPED;
spin_lock_irq(&pgdat->lru_lock);
// 隔离部分 lru 中的页,保存到临时链表 page_list 中
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,
&nr_scanned, sc, isolate_mode, lru);
// 相关统计信息更新
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
reclaim_stat->recent_scanned[file] += nr_taken;
if (current_is_kswapd()) {
if (global_reclaim(sc))
__count_vm_events(PGSCAN_KSWAPD, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_KSWAPD,
nr_scanned);
} else {
if (global_reclaim(sc))
__count_vm_events(PGSCAN_DIRECT, nr_scanned);
count_memcg_events(lruvec_memcg(lruvec), PGSCAN_DIRECT,
nr_scanned);
}
spin_unlock_irq(&pgdat->lru_lock);
if (nr_taken == 0)
return 0;
// 执行页面回收,待回收的页放在 page_list 中,回收完成之后没有被回收的页也被放在 page_list 中返回
nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, 0,
&stat, false);
spin_lock_irq(&pgdat->lru_lock);
if (current_is_kswapd()) {
if (global_reclaim(sc))
__count_vm_events(PGSTEAL_KSWAPD, nr_reclaimed);
count_memcg_events(lruvec_memcg(lruvec), PGSTEAL_KSWAPD,
nr_reclaimed);
} else {
if (global_reclaim(sc))
__count_vm_events(PGSTEAL_DIRECT, nr_reclaimed);
count_memcg_events(lruvec_memcg(lruvec), PGSTEAL_DIRECT,
nr_reclaimed);
}
// 将没有回收的页放回对应链表中,如果页的引用计数为 0 就放到 page_list 中返回
putback_inactive_pages(lruvec, &page_list);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&pgdat->lru_lock);
mem_cgroup_uncharge_list(&page_list);
// 释放掉引用计数变为 0 的页
free_unref_page_list(&page_list);
/*
* If dirty pages are scanned that are not queued for IO, it
* implies that flushers are not doing their job. This can
* happen when memory pressure pushes dirty pages to the end of
* the LRU before the dirty limits are breached and the dirty
* data has expired. It can also happen when the proportion of
* dirty pages grows not through writes but through memory
* pressure reclaiming all the clean cache. And in some cases,
* the flushers simply cannot keep up with the allocation
* rate. Nudge the flusher threads in case they are asleep.
*/
if (stat.nr_unqueued_dirty == nr_taken)
wakeup_flusher_threads(WB_REASON_VMSCAN);
sc->nr.dirty += stat.nr_dirty;
sc->nr.congested += stat.nr_congested;
sc->nr.unqueued_dirty += stat.nr_unqueued_dirty;
sc->nr.writeback += stat.nr_writeback;
sc->nr.immediate += stat.nr_immediate;
sc->nr.taken += nr_taken;
if (file)
sc->nr.file_taken += nr_taken;
trace_mm_vmscan_lru_shrink_inactive(pgdat->node_id,
nr_scanned, nr_reclaimed, &stat, sc->priority, file);
return nr_reclaimed;
}
页面回收:
- shrink_page_list
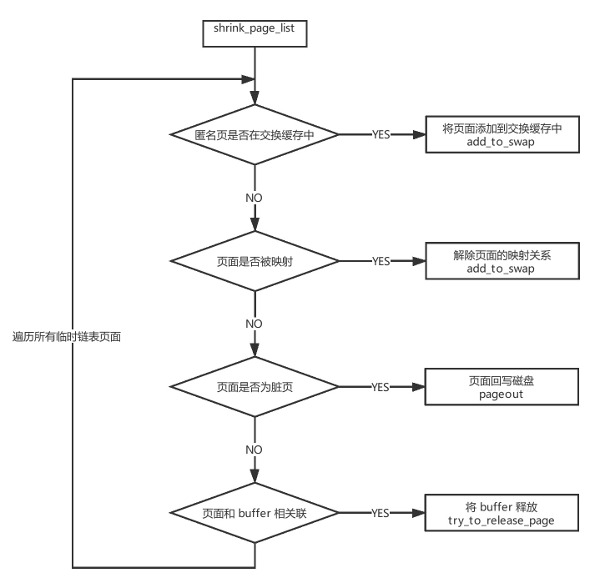
ftrace + kernelshark 辅助分析
执行页面回收中页面状态
ftrace 会抓取下面这些信息统计,所以提前了解下。
struct reclaim_stat {
unsigned nr_dirty;// page_list中脏页数
unsigned nr_unqueued_dirty;// page_list中脏页但是没有放入块设备请求队列中的页数
unsigned nr_congested;// page_list中阻塞的页数
unsigned nr_writeback; // page_list中处于回写中但是不是被回收的页数
unsigned nr_immediate; //page_list中即回写中而且即将被回收的页数
unsigned nr_activate;// page_list中近期被访问过需要添加到 activate list 的页数
unsigned nr_ref_keep;// page_list中近期被访问过的页数
unsigned nr_unmap_fail;//解除映射失败的页数
};
经过一段时间的老化测试,测试同学终于抓到 log 了。
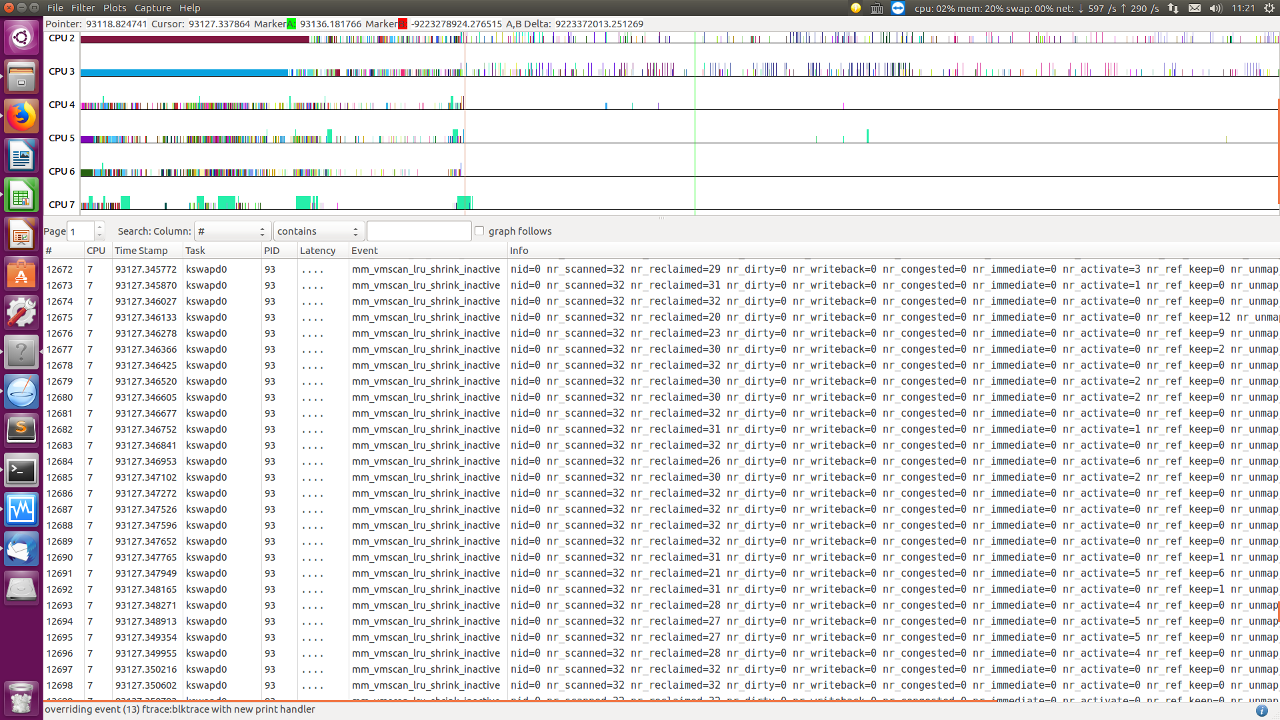
图中显示 nr_dirty,nr_congested,nr_writeback 几乎都是 0,只有零星 nr_activate 被再访问的页面要添加回 active list.
说明现场不存在 dirty 页面很多,回写 io 遇到瓶颈的情况。这个猜想不成立了。
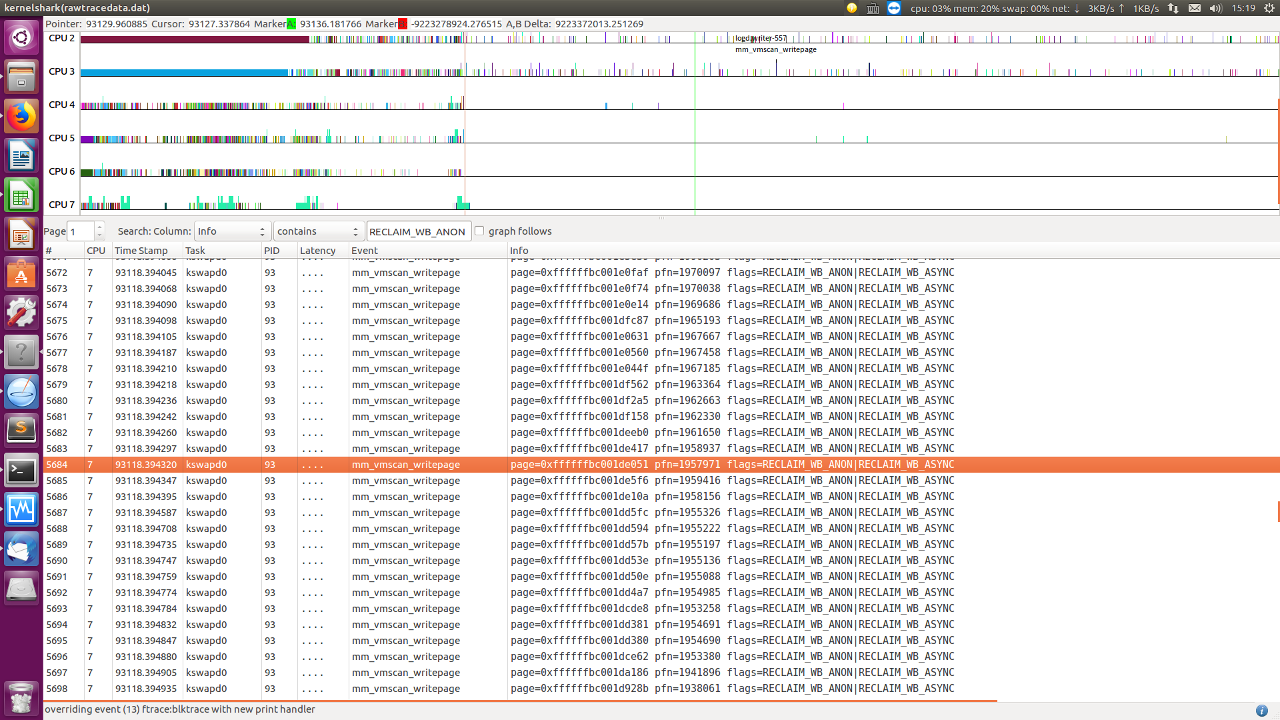
图中显示在 34 秒内,所有在 pageout() 中的页面,全是 anon 页面,没有 file ?
查看 writeback trace event.
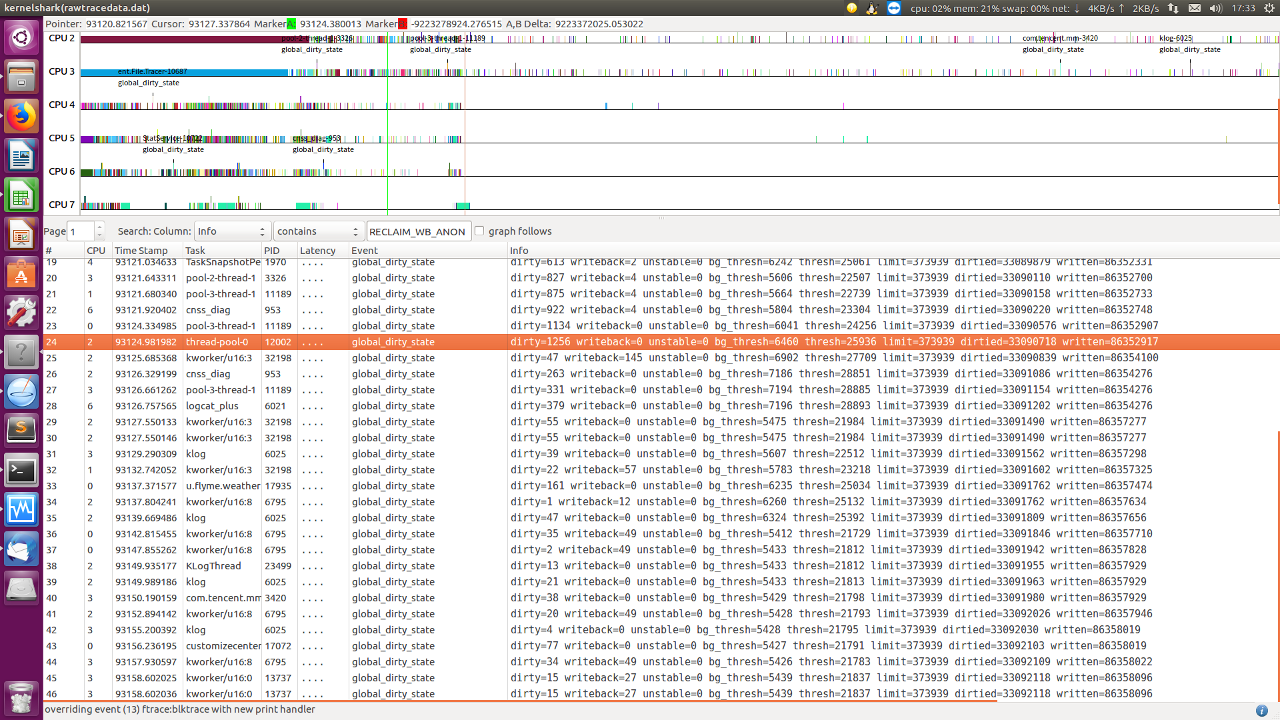
同样,没有很多 writeback 量
从测试结果看到:
- apk 监控到的 io 使用率不高
- 从 ftrace 看到回写量不大
通过最新的数据信息,回到之前的两个大方向:
一是内存紧缺,内存回收不及时,内存需求量大。LMK 没触发,内存有很多匿名页,都在回收和回写文件页等。(抬高水位、加速 LMK 触发,还有复现,不能彻底解决)二是 io 速率慢,某个时间段速率变慢,ufs 频率低,上层读写大量数据,io 占用率过高等。(数据证明,io 量不多,没有瓶颈)
那么,之前的两个方向猜想,都落空了。那会是什么意想不到的原因?
那回去看看卡住的代码,too_many_isolated 代码。
static int __too_many_isolated(struct pglist_data *pgdat, int file,
struct scan_control *sc, bool stalled)
{
unsigned long inactive, isolated;
if (file) {
if (stalled) {
inactive = node_page_state_snapshot(pgdat,
NR_INACTIVE_FILE);
isolated = node_page_state_snapshot(pgdat,
NR_ISOLATED_FILE);
} else {
inactive = node_page_state(pgdat, NR_INACTIVE_FILE);
isolated = node_page_state(pgdat, NR_ISOLATED_FILE);
}
} else {
if (stalled) {
inactive = node_page_state_snapshot(pgdat,
NR_INACTIVE_ANON);
isolated = node_page_state_snapshot(pgdat,
NR_ISOLATED_ANON);
} else {
inactive = node_page_state(pgdat, NR_INACTIVE_ANON);
isolated = node_page_state(pgdat, NR_ISOLATED_ANON);
}
}
/*
* GFP_NOIO/GFP_NOFS callers are allowed to isolate more pages, so they
* won't get blocked by normal direct-reclaimers, forming a circular
* deadlock.
*/
if ((sc->gfp_mask & (__GFP_IO | __GFP_FS)) == (__GFP_IO | __GFP_FS))
inactive >>= 3;
return isolated > inactive;
}
没有很复杂的逻辑,只有简单的 isolated 和 inactive 统计计数比较。
所以,只能是更直接的猜想:isolated file 统计一直偏大,导致一直判断 too_many_isolated 为真,卡在 shrink_inactive_list.
根据这个猜想,从 log 中打印的 mem info,也看到 isolated file 一直偏大,一直在增加,不会减少。好像印证了猜想似的。
LOG:
<6>[95299.607369] isolated(anon):0kB isolated(file):37880kB
<6>[95318.568833] isolated(anon):0kB isolated(file):37752kB
<6>[95323.773350] isolated(anon):0kB isolated(file):37752kB
<6>[97520.184804] isolated(anon):0kB isolated(file):44604kB
<6>[97525.658037] isolated(anon):0kB isolated(file):44604kB
<6>[97754.256431] isolated(anon):0kB isolated(file):44604kB
<6>[97759.418172] isolated(anon):0kB isolated(file):44604kB
<6>[97764.574908] isolated(anon):0kB isolated(file):44604kB
<6>[97769.735128] isolated(anon):0kB isolated(file):44604kB
<6>[98543.638667] isolated(anon):0kB isolated(file):44684kB
<6>[98548.905397] isolated(anon):0kB isolated(file):44684kB
<6>[98554.209671] isolated(anon):0kB isolated(file):44684kB
<6>[99996.798031] isolated(anon):0kB isolated(file):51572kB
<6>[100002.122853] isolated(anon):0kB isolated(file):51572kB
<6>[100007.359023] isolated(anon):0kB isolated(file):51572kB
<6>[100146.079882] isolated(anon):0kB isolated(file):51700kB
<6>[100151.313065] isolated(anon):0kB isolated(file):51572kB
<6>[100156.587622] isolated(anon):0kB isolated(file):51572kB
<6>[100328.483071] isolated(anon):0kB isolated(file):51700kB
<6>[100520.245217] isolated(anon):0kB isolated(file):51572kB
<6>[100550.688429] isolated(anon):0kB isolated(file):51572kB
<6>[100555.913634] isolated(anon):0kB isolated(file):51572kB
<6>[100669.226582] isolated(anon):0kB isolated(file):51572kB
<6>[100935.069661] isolated(anon):0kB isolated(file):51688kB
<6>[100940.240279] isolated(anon):0kB isolated(file):51572kB
<6>[100945.476071] isolated(anon):0kB isolated(file):51828kB
<6>[103104.120921] isolated(anon):0kB isolated(file):53344kB
<6>[103121.900214] isolated(anon):0kB isolated(file):53344kB
<6>[103481.197823] isolated(anon):0kB isolated(file):53412kB
<6>[103486.555528] isolated(anon):0kB isolated(file):53412kB
<6>[103721.346234] isolated(anon):0kB isolated(file):53412kB
<6>[103726.655700] isolated(anon):0kB isolated(file):53540kB
<6>[103731.961321] isolated(anon):0kB isolated(file):53540kB
<6>[103737.236295] isolated(anon):0kB isolated(file):53540kB
<6>[103742.470632] isolated(anon):0kB isolated(file):53412kB
<6>[103747.661019] isolated(anon):0kB isolated(file):53284kB
<6>[103752.973978] isolated(anon):0kB isolated(file):53412kB
柳暗花明又一村
对 NR_ISOLATED_FILE/NR_ISOLATED_ANON 的统计增减主要分布在 vmscan.c、migrate.c 和 PPR (某司进程内存回收)模块。理论上内核 vmscan.c(成双成对) migrate.c 都不会有问题,PPR 模块插入在 vmscan. c 和 task_mmu.c 里,而我们 IMS 没有直接使用 PPR,嫌疑最大。于是,在上游确实找到了个相关的 patch: mm: do not shrink pages marked for reclaim by MADV_FREE:
MADV_FREE clears pte dirty bit and then marks the page lazyfree (clear SwapBacked). PPR increments ISOLATE_FILES count, then isolates page and invokes a reclaim. Inbetween if this lazyfreed page is touched by user then it becomes dirty. PPR in shrink_page_list in try_to_unmap finds the page dirty, marks it back as PageSwapBacked and skips reclaim. As PageSwapBacked set, PPR identifies the page as anon and decrements ISOLATED_ANON, thus creating isolated count mismatch.
This results in too_many_isolated() check causing delay in reclaim. Skip reclaiming lazyfreed pages in PPR path.
这个 patch 正是修复了 isolated count mismatch 的问题,导致一直让 isolated file 增大,下面来两个相关知识:
- MADV_FREE (since Linux 4.5)
The application no longer requires the pages in the range specified by addr and len. The kernel can thus free these pages, but the freeing could be delayed until memory pressure occurs. For each of the pages that has been marked to be freed but has not yet been freed, the free operation will be canceled if the caller writes into the page. After a successful MADV_FREE operation, any stale data (i.e., dirty, unwritten pages) will be lost when the kernel frees the pages. However, subsequent writes to pages in the range will succeed and then kernel cannot free those dirtied pages, so that the caller can always see just written data. If there is no subsequent write, the kernel can free the pages at any time. Once pages in the range have been freed, the caller will see zero-fill-on-demand pages upon subsequent page references.
The MADV_FREE operation can be applied only to private anonymous pages (see mmap(2)). In Linux before version 4.12, when freeing pages on a swapless system, the pages in the given range are freed instantly, regardless of memory pressure.
- madvise system call
madvise(2) is a system call used by processes to tell the kernel how they are going to use their memory, allowing the kernel to optimize the memory management according to these hints to achieve better overall performance.
When an application wants to signal the kernel that it isn’t going to use a range of memory in the near future, it can use the MADV_DONTNEED flag, so the kernel can free resources associated with it. Subsequent accesses in the range will succeed, but will result either in reloading of the memory contents from the underlying mapped file or zero-fill-on-demand pages for mappings without an underlying file. But there are some kind of apps (notably, memory allocators) that can reuse that memory range after a short time, and MADV_DONTNEED forces them to incur in page fault, page allocation, page zeroing, etc. For avoiding that overhead, other OS like BSDs have supported MADV_FREE, which just mark pages as available to free if needed, but it doesn’t free them immediately, making possible to reuse the memory range without incurring in the costs of faulting the pages again. This release adds Linux support for this flag.
Recommended LWN article: Volatile ranges and MADV_FREE
madvise 系统调用,会建议内核,在从 addr 指定的地址开始,长度等于 len 参数值的范围内,该区域的用户虚拟内存应遵循特定的使用模式,使内核可以选择适当的预读和缓存技术。如果使用 madvise() 函数的程序明确了解其内存访问模式,则使用此函数可以提高系统性能。
自 4.5 开始,引入 MADV_FREE 参数(这是为什么 4.9 内核才出现该问题,这需要上层和底层同时支持,才会出现本问题)。简单来说,MADV_FREE 就是让上层设置一段内存可以释放内存的标志,但是底层并不会立即释放,以便让上层可以在短时间内重复访问,以免增加缺页异常等性能开销。也叫 lazy free,它只能用于匿名页面。
根据描述,触发 isolated file 统计增大的路径是:(代码省略不贴)
- 上层调用 madvise 系统调用,使用 MADV_FREE 时,清除 dirty bit 和 SwapBacked bit,把 lazyfree page 加入 inactive file list。
- PPR 增加 ISOLATE_FILES 计数(SwapBacked=0),隔离页面并触发回收
- 上层访问 lazyfreed 页面,dirty=1
- PPR 执行 reclaim_pte_range -> reclaim_pages_from_list -> shrink_page_list ->try_to_unmap -> try_to_unmap_one 设置 SwapBacked=1, 并跳出回收
- PPR 继续执行 reclaim_pte_range -> reclaim_pages_from_list,putback_lru_page 的时候,因为 SwapBacked=1,减少了 NR_ISOLATED_ANON 计数,而不是减少当初增加的 NR_ISOLATED_FILE 计数。
- 导致 NR_ISOLATED_FILE 一直被增加
所以,需要在 PPR 中过滤 lazyfree 页面,避免这个 NR_ISOLATED_FILE 计数异常,导致的卡 too_many_isolated.
匿名页面一开始就会设置 SwapBacked=1, 并且只有在上层设置 lazyfree 页面时才会清除 ClearPageSwapBacked(page) ,没别的地方了。
所以,PageAnon(page) && !PageSwapBacked(page) 能指示这是 lazyfree 页面。
小结
ok,已经理清了前因后果。再退一步,试想下,假如上游没有修复这个 patch。我们能不能想出来?我觉得很难,因为我们缺乏 madvise 的相关认识,并且它经过了 dirty, SwapBacked 标志的变化(好像几乎没办法做这么微观的页面标志追踪?),才导致 NR_ISOLATED_ANON/FLIE 的变化。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
