

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
jemalloc 之堆占用剖析·内部实现
by Chen Jie of TinyLab.org 2015/11/02
前言
做好一个消费类的操作系统,大概有 4 个方面,分别是表达丰富的用户界面技术、贴合硬件的伸缩框架、清晰结构化的包管理方案以及强有力的剖析手段。
其中,用户界面技术重要性不言而喻,不仅能支撑精彩纷呈的界面设计落地,更能进一步做好分离,方便社会化分工的开发及工业化的复用。而贴合硬件的伸缩框架,例如如何有效利用非对称的多核计算、GPU 计算;如何有效地支持低内存环境等等 —— 软硬同心才是王道。
包管理方案,并非狭义上的 App 包,而是将操作系统整体拆包。是操作系统的静态架构,关系操作系统的扩展、裁剪、更新及成体系化的安全。而强有力的剖析手段,正是透视操作系统内部运作的利器。例如可以有效侦破性能瓶颈和程序缺陷;而在方案选择和对比中,更能作为硬指标阐明情况,减少拍脑袋和 FUD(Fear, Uncertainty, Doubt)的决策。
本文聊的正是剖析技术中的堆占用剖析,也就是统计 malloc/new 出来的内存空间。
Similar heap profiling tools
除了 jemalloc 的 jeprof 外,还有如下一些堆占用剖析工具:
- gperftools 与 jeprof 类似,不过是基于 tcmalloc 的。
- IgProf 欧洲大型强子对撞机项目中用到的内存剖析工具,在 FOSDEM 2015 上的简介幻灯,表述其通过诸如栈上帧(Frame)定位优化,减小了工具自身开销。然初步尝试未果,猜测这些优化尚不成熟。
- heaptrack 也类似上述工具 —— 或是 malloc 实现中内建的剖析功能(jeprof、gperftools),或是通过 LD_PRELOAD 来截获 malloc 等函数调用。heaptrack 提供的 wrapper 脚本,可向已有进程插入 heaptrack。它是通过 gdb 装载剖析库并调用挂钩例程,挂钩全局 malloc* 符号。
- Massif 与上述均不同,它是个 valgrind 带的工具,因此剖析开销要大很多。
对于堆占用剖析工具,大体可以分为间隔采样,转储采样统计,并用工具进行离线分析。其中,采样以 bt(backtrace,调用回溯)为单位进行。在离线分析时,可根据需要,合并相似 bt 来展示内存分配数据;也可比较不同时间点的转储文件;甚至于可视化的呈现。
对于 jemalloc 而言,除了在编译时刻启用 profiling 特性,还需在运行时刻开启:
# 通过环境变量启用:
export MALLOC_CONF="prof:true"
# 或 启用 profiling,但一开始不激活
export MALLOC_CONF="prof:true,prof_active:false"
# 随后在程序代码中通过 mallctl 调用来激活/关闭
bool active = true;
mallctl("prof.active", NULL, NULL, &active, sizeof(active))
采样的间隔也由环境变量设置:export MALLOC_CONF="lg_prof_sample:N",平均每分配出 2^N 个字节 采一次样。当 N = 0 时,意味着每次分配都采样。
转储采样统计,有三种方式:
export MALLOC_CONF="lg_prof_interval:N",分配活动中,每流转 1 « N 个字节,将采样统计数据转储到文件。export MALLOC_CONF="prof_gdump:true",当总分配量创新高时,将采样统计数据转储到文件。- 在程序内主动触发转储:
mallctl("prof.dump", NULL, NULL, NULL, 0)
最后,离线分析工具为 jeprof。其中转储文件中只记录了栈上各函数调用的 地址,故在离线分析时,需结合带符号的可执行程序,来产生可读报告。jeprof 的简单用法,可参见此处博文。
下面来探究 jemalloc 堆占用剖析的内在实现。嗯为何要关心内在实现?这是因为这里是泰晓,知微见著,追本溯源 —— 知晓内在实现,能更好明白堆占用剖析是怎么回事,可达到什么样的力道,从而不受外在工具的制约。
jemalloc 如何进行间隔采样
关于 jemalloc,它大概是目前顶尖的内存分配实现之一。本站内存管理专辑 中,分别以 分配(malloc) 和 释放 (free) 为线索窥视了 jemalloc 3.6.0 版本。而本篇写作时,基于目下最新的 jemalloc 4.0.3 版本。这两版本间的变化也算不小,但基本设计还是一脉相承。
阅过前文,我们知道 jemalloc 对待分配的内存大小,分作三个量级:small,large 和 huge。简单的说,large 是页级的尺寸,huge 是 Chunk 级的尺寸(例如 4MB)。出于简化,此处只关心较为复杂且常见(换言之,有代表性)的 small 和 large 量级内存分配中的剖析。
函数路径:je_malloc/imalloc_body,采样过程如下图所示:
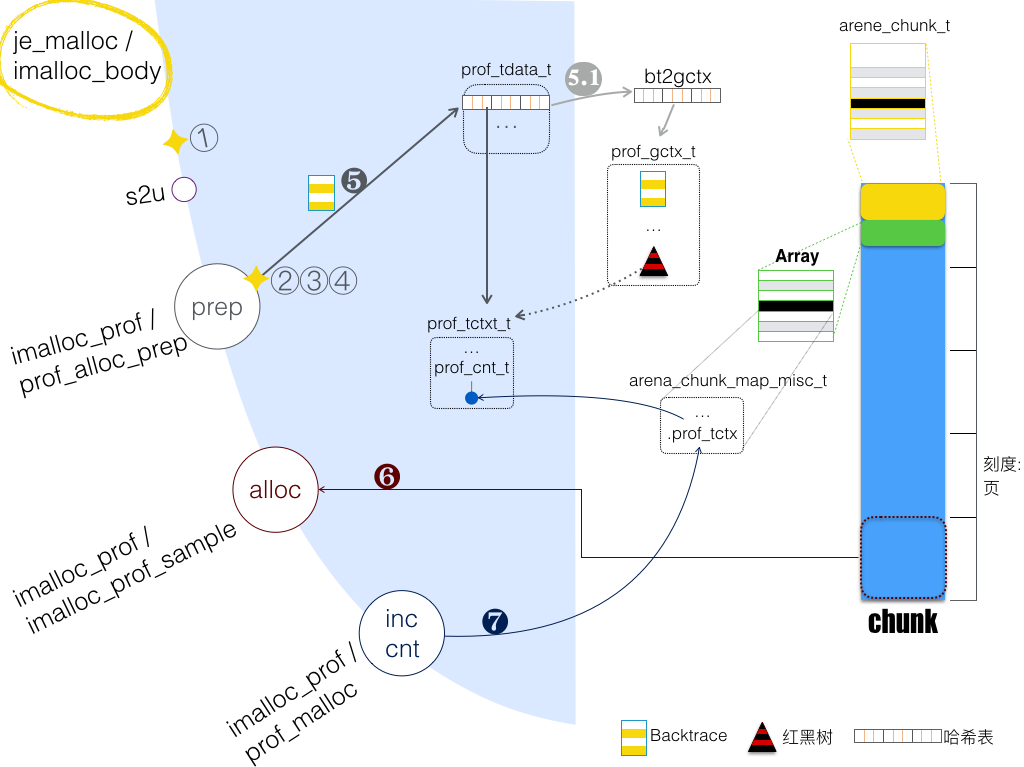
依次按照图中标号介绍:
① opt.prof - 剖析总开关。由环境变量 MALLOC_CONF="prof:true" 来打开。
s2u: 剖析打开时,会 提前 将请求分配的内存大小,“规整”到内部实际分配的大小。故,采样统计的都是规整后内存分配数。
prep: 准备阶段,判断是否进行采样,及采样的准备工作。
② prof.active - 剖析激活与否的开关。使用场景如:MALLOC_CONF="prof:true,prof_active:false"打开剖析,却默认禁用,由外部代码稍后通过 mallctl 来激活。
③ opt.lg_prof_sample - 采样平均间隔(以字节计)。累计本线程分配出的内存,若超过阀值,则触发采样,同时清零、设置新阀值。注意:a) 阀值以“平均 2^lg_prof_sample 字节”做随机分布;b) lg_prof_sample 为 0 时,对每次分配都采样。
④ thread.prof.active - 本线程之剖析激活与否的开关。
❺ 准备进行采样:确保 bt(backtrace)已记录在本地哈希表。这里提到的哈希表,键(key)为 bt,值(value)为 prof_tctx_t 类型,该类型含有数据成员 cnts,其类型为 prof_cnt_t,这是一组计数器:
- curobjs:已分配 内存对象 计数,或者说是内存分配计次(因为每次分配,分配一个 内存对象)。
- curbytes: 已分配内存字节数。
- accumobjs,accumbytes:类似上述(相应)计数。不同的是,上面两计数会在 free(相应内存)时减小,而 accum* 计数不会,换言之,只增不减。
注意:标号为 5.1) 过程,当 bt 未见于本地哈希表,需在全局哈希表中找到,并插入本地哈希表。全局哈希表,键(key)为 bt,值(value)为 prof_gctx_t 类型。若全局哈希表中也无有,则新建记录:bt 存于 prof_gctx_t,并作为键(key)。
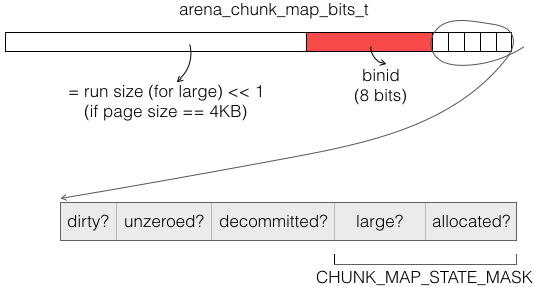
❻ 分配内存:有两特点。一是 Chunk 头部元数据有 arena_chunk_map_misc_t 之数组,其中每项对应一页(Chunk 含有多个内存页)。arena_chunk_map_misc_t 保存了 ❺ 返回的 prof_tctx_t 地址。另,此处可见,分配的内存必须在页级大小,于是就有了第二个特点:
不足页级大小的分配,或者说 small 量级的分配,晋级(promote)到 large 量级分配。此时,对应的 arena_chunk_map_bits_t,large 位和 run size 均设置;但同时 binid 也设置。binid 指示了 promote 前应该分配的尺寸:
❼ 增加 prof_tctxt_t 中相应计数。
再来看看内存释放时,prof_tctxt_t 中计数如何减小,函数路径je_free/ifree/prof_free/prof_free_sampled_object:通过 待释放内存块 之指针,找到 prof_tctx_t(参见 ❻)。若计数减为 0, 则进一步考虑销毁 prof_tctx_t 甚至于 prof_gctx_t 结构。
此处注意:prof_tctx_t 位于分配发起线程的本地存储,而释放可能位于其他线程。故需锁保护。
jemalloc 如何转储采样统计
发起转储有仨情形:
- opt.lg_prof_interval - 单个 arena(中文唤做竞技场,一个竞技场供几个线程共享,换言之,这几个线程角斗 arena 中的资源),每流转 1 « opt.lg_prof_interval 字节,进行转储。其函数路径有:
- arena_malloc_small/prof_idump: 从 arena 分配出 small 量级内存块。此路径仅限单线程情形(!isthreaded)。
- arena_tcache_fill_small/prof_idump:从 arena 转出内存到 tcache,供进一步分配 small 量级内存块。
- arena_malloc_large/prof_idump: 从 arena 分配出 large 量级内存块。
- tcache_bin_flush_small/prof_idump: 从 tcache(把 small 量级上、某档尺寸下缓冲) 转入到 arena。
- tcache_bin_flush_large/prof_idump: 类上,但是 large 量级。
- tcache_destroy/prof_idump
- opt.prof_gdump - 使用的 Chunk 数创新高时,进行转储。函数路径为 chunk_register/prof_gdump。
- prof.dump - 外部代码调用
mallctl("prof.dump", NULL, NULL, NULL, 0),进行转储。
总之,opt.lg_prof_interval 是以 arena 为单位的、依据内存流水账的定期转储,故对 huge 量级的分配不统计。opt.prof_gdump 是站在全局,观察 Chunks 的每个峰值,较为宏观。而 prof.dump 是外部代码触发的,大概最贴近大部份使用场景。
另,prof_idump 和 prof_gdump,最终都调用了 prof_dump。prof_dump 内部用了 3 个 Pass 来完成转储:
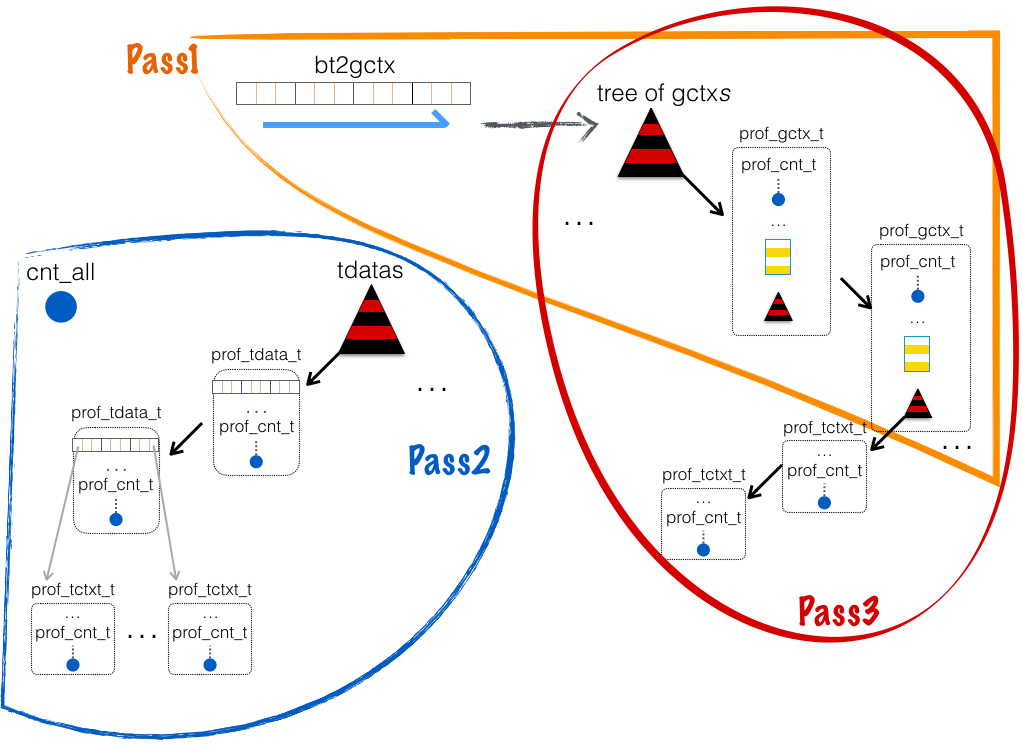
- Pass1:遍历全局哈希表,将各个 prof_gctx_t 插入到新建的 gctxs_tree 中。同时对每个 prof_gctx_t:
- pin 住(nlimbo++),阻止别的线程来销毁它。
- 清零内含计数器 cnt_summed。该计数器用于统计对应函数路径(一个 prof_gctx_t 对应一个 bt)分配出的内存。
- Pass2:遍历红黑树 tdatas,对每个 prof_tdata_t:
- 清零内含计数器 cnt_summed。该计数器用于统计 prof_tdata_t(即此线程下)分配出的内存。
- .dumping = true
- 遍历本地哈希表,对每个状态为 “prof_tctx_state_nominal” 的 prof_tctx_t:
- 状态改为 “prof_tctx_state_dumping”
- 计数累加到 prof_tdata_t. cnt_summed
- 最后将各个 prof_tdata_t. cnt_summed 汇总到 cnt_all 计数器 - 即目前已分配出的所有内存。
- Pass3:遍历红黑树 gctxs_tree,对每个 prof_gctx_t:
- 遍历 .tctxs(也是个红黑树),对每个状态为 “prof_tctx_state_dumping” 或 “prof_tctx_state_purgatory” 的 prof_tctx_t:
- 将计数汇总到 prof_gctx_t. cnt_summed
- 遍历 .tctxs(也是个红黑树),对每个状态为 “prof_tctx_state_dumping” 或 “prof_tctx_state_purgatory” 的 prof_tctx_t:
综述,Pass2 统计出了各个线程已分配内存、全部已分配内存,Pass3 统计了每个函数路径(bt)分配出的内存。
上面 3 个 Pass 中,更改了几个数据结构的状态,它们如下恢复:
- prof_gctx_finish:销毁 gctxs_tree 时,每个
prof_gctx_t.nlimbo-- - prof_gctx_finish/tctx_tree_iter/prof_tctx_finish_iter:将 prof_tctx_t 状态恢复为
prof_tctx_state_nominal
后记
虽说这是第三篇 jemalloc 文,然 jemalloc 探索之旅还未结束,例如多线程情形下的数据并发访问、spinlock vs mutex lock、优化单线程情形、utrace 框架 ... 以及其中的数据结构和算法。
“google 面试必有数据结构和算法” —— 想必这个故事广为流传。另一方面,也许日复一日的工作中,鲜有接触红黑树,也渐渐模糊了哈希表。那么,放下繁琐的心,看看这些数据结构,是否又找回一些宁静了呢?
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
