

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
内存分配奥义·malloc in OS X
by Chen Jie of TinyLab.org 2015/2/22
前言
苹果的一切似乎都透着其背后的设计气息(Oh! Back up, the author is going to play zhuangbility !! 喔!退后,作者要开始装 B 了 !!)~~~ 苹果的代码也不例外,通常表现抽象的模型,通常直击清晰的场景,通常带着一些防呆编码来侦测客户代码中的错误。抽象的模型在不同代码间塑现,使得呈现出一种整体性;清晰的场景来垂直整合,使得呈现一种便利性;而防呆编码则像一种绅士的成熟气质,错误代价较小而便于包容。
文归正题,在内存分配设计中,首先看到的是一种基于分配区域(malloc_zone)的概念:
typedef struct _malloc_zone_t {
...
size_t (*size)(struct _malloc_zone_t *zone, const void *ptr); /* returns the size of a block or 0 if not in this zone; must be fast, especially for negative answers */
void *(*malloc)(struct _malloc_zone_t *zone, size_t size);
void *(*calloc)(struct _malloc_zone_t *zone, size_t num_items, size_t size); /* same as malloc, but block returned is set to zero */
void *(*valloc)(struct _malloc_zone_t *zone, size_t size); /* same as malloc, but block returned is set to zero and is guaranteed to be page aligned */
void (*free)(struct _malloc_zone_t *zone, void *ptr);
void *(*realloc)(struct _malloc_zone_t *zone, void *ptr, size_t size);
void (*destroy)(struct _malloc_zone_t *zone); /* zone is destroyed and all memory reclaimed */
const char *zone_name;
...
/* Empty out caches in the face of memory pressure. The callback may be NULL. Present in version >= 8. */
size_t (*pressure_relief)(struct _malloc_zone_t *zone, size_t goal);
} malloc_zone_t;
zone 的存在,使得多种内存分配逻辑并存,成为可能。例如,YY 下,为保持会话的持续性,从由 SSDAlloc 实现的 zone 中分配内存。
内存分配、释放和响应内存压力
本节,我们从内存分配、释放过程,以及内存不足时的响应过程,来一窥 malloc_zone(libmalloc)。
首先,就像我们在 jemalloc 之旅中发现的那样,内存分配系统会依据请求的大小,来对待处理。malloc_zone 的尺寸分类如下表:
分配类型 | 处理 size 范围 | 档位数 | 粒度(QUANTA) |
nano | 0(返回16) – 256 B | 16 | 16 B |
tiny | 0(返回 16) – 63×16 B | 63 | 16 B |
small | >=1GB:1009 B – 127 KB | 255 31 | 512 B |
large | > small | N/A | kernel page size |
上表中,malloc_zone 对请求尺寸分成了 4 类,其中 nano 和 tiny 分配粒度相同,且后者范围覆盖前者,其中蹊跷稍后说明。对于 small 而言,其档位数取决于 系统总的物理内存 的是否多于 1GB。注意,相邻两档之间差一个粒度(这实际上是个量子的概念了,所以被称为 Quanta)。
作为对比, jemalloc (chunk size == 4MB,page size == 4KB,x86-64) 的情况是这样的:
分配类型 | 处理 size 范围 | 档位数 | 粒度(QUANTA) |
small | 0(返回 8 ) – 57344 B | 44 internal/class_size.sh | N/A (归档位) |
large | 57345 B – 接近 chunk size | N/A | page size |
huge | > large | chunk size |
The NanoZone
NanoZone 仅用来分配 Nano 尺寸量级的内存。除了尺寸范围,使用 NanoZone 还有如下要求:
- 必须是 64 位进程
- 环境变量 MallocNanoZone 值为 “1″。对于 App 进程,该环境变量会自动设为 1。
NanoZone 会惦记着一块固定地址起始的、足够大的地址空间。NanoZone 正常情况下进行无锁分配;且在内存紧张时释放掉的地址空间,将不再使用(向前推进所使用的窗口)。这就是为何有上述两大要求:
- 64 位确保地址空间资源够多,可以任性地“浪费”。
- App 生命周期较短,故浪费(“泄漏”)一点无关系;且 App 处理 UI,需低延时,故期望无锁的内存分配。
NanoZone 分配失败,则会从其 helper zone – Scalable Zone 中分配。NanoZone 将其惦记的空间划分为如下几个级别:
- Magazines(弹仓?)每个物理 CPU 核(非 SMT 虚拟 CPU),拥有一个属于它的地址空间范围,大小为 512 GB。
- Bands(波段)耗尽一个 Band,用下一个 Band。一个 Band 大小为 2 MB。
- Slots(槽),每个 Slot 应对一种尺寸的分配请求,也即对应一档。一个 Slot 大小为 128 KB;16 个 Slots 构成一个 Band。
分配时,从对应 Magazine 中的 对应档位 取一个空闲的块,这是一个对单向链表的原子操作。如下图所示: 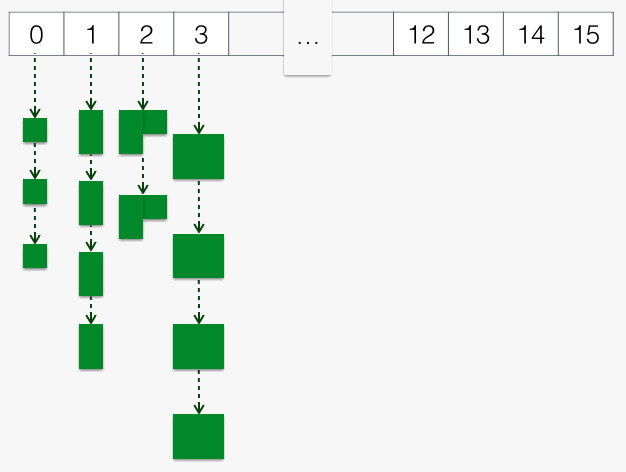
如果恰好没有空闲块,则:
- 是否耗尽当前 Slot?如无,则由 slot_bump_addr 起分配出一个内存块 (同时 slot_bump_addr 前进)。
- 呀,耗尽了当前 Slot,但是下一个 Band 的对应 Slot 已经被映射了。用这个 Slot。
- 呀,耗尽了当前 Band,拓宽到下一个 Band,使用该 Band 中的对应 Slot。
当内存紧张时,依次扫描每个 Magazine,对每个档位:
- 依据本档位已映射的对象数目(slot_objects_mapped),生成位图 slot_bitarray。注意,这是本档位的用到/过的各 Bands 中,对应 Slots 含有对象总数 之位图。
- 依据 slot_objects_mapped 可知对应的页数,生成位图 page_bitarray。注意,一个 Slot 大小为 128 KB,即本身包含若干个页;这里是所有用到/过的 Slots 对应的页数 之位图。
- 扫描本档位空闲块链表,将空闲的对象标注到 slot_bitarray 中。
- 从规划的起始地址开始,扫描 slot_objects_mapped 个对象,若其非空闲(slot_bitarray 中未有标注,即 已经被分配或 曾经被分配过),则标记到 page_bitarray 中。
- 从规划的起始地址对应页面开始, 扫描目前已实际分配过的页面 (由 slot_bump_addr 指出),不在 page_bitarray ,则 madvise 之,嵌入式环境用 MADV_FREE,其他用 MADV_FREE_REUSABLE。
NanoZone 有点像 jemalloc 的 tcache,目的是为了提供分配/释放的快速路径。当前,其自身容量,及覆盖的分配尺寸是有限的,因此还要借助 Scalable Zone 来处理其他情形。
The Scalable Zone
在 Scalable Zone 的处理中,tiny 和 small 级别的处理非常相似;而 large 级别的处理为页级映射,结合一个链表缓存释放块,相对简单。故我们重点来关注 tiny 级别的几个例程。
一个有代表性的分配代码路径如下图所示:
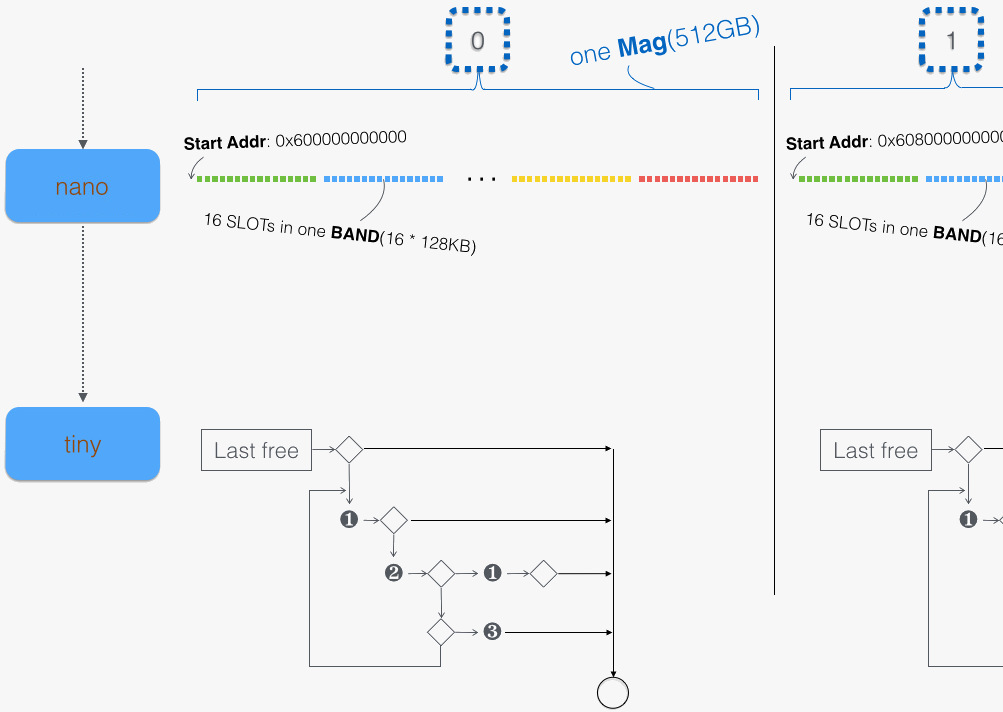
上图中,一次分配请求先经由 NanoZone,再转给 Scalable Zone 中处理 tiny 级别的代码。注意:
- nano: 线中的单个小点代表一个 Slot,而一段彩色的线条代表一个 Band。
- tiny:有 Last free,(1),(2),(3) 三个子例程。下面来详述展开。
首先,我们知道 tiny 中分配的粒度是 16 字节,从页起始分配 16 或 16 字节整数倍的内存块,使得分配的地址总是 16 字节对齐,这意味着其最后 4 位全为 零,换言之,可以存一些额外的信息。Last free 就利用了这个特点:
- 最近一次释放的内存块,以粒度为单位计,其大小为 msize。若 msize 能上述用 4 位空间记录,则将其记录到释放块的指针尾上,并替换前一个 Last free。换言之,这是一个长度为 1,最大容纳 240 (15×16) 字节的缓冲。
- 分配内存时,首先看请求的内存块尺寸是否等于 Last free,如是,则返回之。
通常来讲,运气不会那么好,Last free 的伎俩会失效。这时代码会继续往下走,由图中标记的三个步骤所描述:
- 从对应档位(以及其以上档位)中分配空闲块;最后尝试从 mag_last_region 中分配
- 从后备弹仓(Depot Magazine)补充 Region
- 分配新的 Region,并从中分配
从对应档位(及其以上档位)中分配空闲块(1),如下图所示:
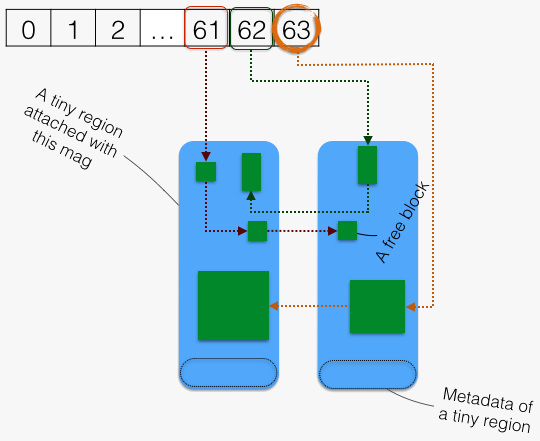
图中有三个对象:
- 0 – 63 个档位,每个档位是一个链表,将本档位尺寸的空闲块链起。注意,最后一档稍有不同,它是将所有大于前一档的空闲块链起 —— 故实际用于分配的档位为 0 – 62 档,其受理尺寸范围 1×16 – 63×16 字节。
- 链起的空闲块。
- Tiny Region。Tiny Region 是一个约 1 MB 左右的区域。Tiny Region 通过其 trailer (拖车?)关联某个 Magazine。
仔细看下空闲块的布局,如下图:
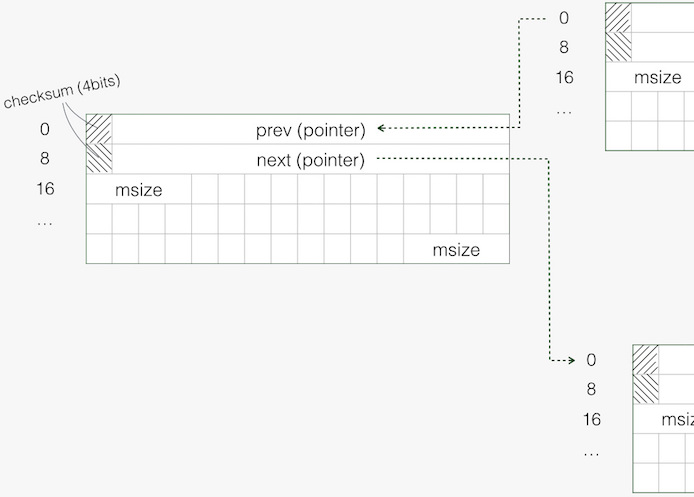
空闲块头部是两指针,从而将其链入一个双向链表。其中,为了防止指针遭意外破坏,进行了“防呆设计”:高 4 位存哈希码,为指针 60 位有效值的哈希值,用于检测指针是否遭篡改。
由于某些需要(例如将连续空闲块合并成大块,放入更高档位),需知道相邻前后块:1)是否空闲;2)若空闲其大小为多少?这由 Tiny Region 的 Metadata 中的 pairs 位图,以及空闲块中的 msize (若有)所指出。
- 按照粒度来分,一个 Tiny Region 共有 64520 个 tiny blocks,由 pairs 位图来标注。
- 若一个 tiny block 是某个空闲块的开头,则 pairs 中对应偏移的 header 置 1,对应偏移的 inuse 置 0。
- 对于尺寸超过 16 字节的空闲块,还会将本块的 msize 存入。注意,存两处,便于和前、后相邻空闲块进行合并时方便使用。
- 若尺寸为 16 字节,那没有空间放下 msize 了。这时看 pairs 位图中,下一个 tiny block 是否 header 置1,此时证明本空闲块为 16 字节。
来说说 Magazine,每个物理的 CPU 核对应一个 Magazine,除此之外,非嵌入式环境 以及 非单核处理器环境中,还有一个“隐藏”的 Depot Magazine(在 Magazine 数组中偏移为 -1): 
当步骤(1)失败时,会从 Depot Magazine 中将一个 Region 移交给当前 Magazine,并将其中空闲块链入各档位。而当数次释放之后,若当前 Magazine 整体用量较低,则会选择 其某个低用量的 Region,将其移入 Depot Magazine,同时进行 madvise。
当步骤(2)失败时,只得分配新的 Region,将 Region 的拖车拖进当前 Magazine,并从中分配空闲块。注意,一开始,Region 只有头上分配出去一点,余下空间都是空闲的,这些剩余空间由 mag_last_region 指示 —— 这也意味对 mag_last_region 前次指向的 Region,需将其尾部的空闲空间链入档位中,该过程由函数 tiny_finalize_region 来完成。
感想
苹果代码的变量和函数命名,清晰达意,且突出区别,对比下 jemalloc 代码这种感触会更深。苹果的代码还做了一些防呆设计,例如:
- 只读区域用 mprotect 来保护,及早侦测意外窜改。
- 内核传入的熵,来生成空闲块的标记,防止例如 “double free”。
- 内核传入的熵,进行地址区间的随机偏移,一定程度的内存分配地址随机化。
- 空闲块指针的哈希校验,从而及早发现指针的覆写。
几个有槽点:元数据放入空闲块,使得 madvise 时受限 – 想象一下,一页头偏偏多了几个空闲块的链接指针,使得该页就不能被 madvise 了。
另外,内存紧张时的响应过程 —— 调用复杂函数,函数中甚至存在内存分配 —— 使得缓解本身有加重内存负载的嫌疑。相比来说,通过 madvise 通知内核哪些区域未使用,在内存紧张时可以释放其的物理内存,似乎更加适合。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
