

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
量子化的 UI
By Chen Jie of TinyLab.org 2016-01-19 21:07:18
引言
在目下大数据时代,海量数据与机器学习,通过理解语境、甚至于用户喜好,人机交互愈来愈 “灵犀相通”。而在具体的人机交互界面上,像 小冰 和 Siri 这样的语音助手,所提供功能也越来越丰富。于是,人机交互也从图形化界面技术,继续迈步向前。
在 2015.11 第三期的泰晓资讯中,提到了 LWN 转载文章「No UI is some UI」。同时,本站「移动终端 UI 设计新思路:从图形界面回归“命令行”?」 提出了聊天风格主导的手机系统界面。用户通过 简单格式的语句,或甚至是自然语言,来完成交互。而「大开脑洞,做一个比表屏大,比 phone 便携的移动设备」一文, 展示了 输入法协助用户生成指令 ,来方便聊天风格的交互。(如何用聊天风格 UI 来满足业务交互?贩一个“私货”:Logging and Tickets。通过交互逐步确定具体的目标,交互过程叫做“Logging”,确定下来的目标叫做“Tickets”。比如,准备出国游去移动营业厅开通“全球漫游服务”,与服务窗口 mm 交谈为 Logging;最后开通具体业务,落款的合同为 Ticket。通过 “Logging”,可回溯细节,并智能化推荐和协助。而 Tickets 则按不同线归档 /Ticket Book/,例如按时间线、位置线归档,从而智能化呈现)
那么,UI 技术再发展中,会有哪些新的挑战?或者说有哪些已有的技术可以复用?或者说 UI 泛化以后还留下什么?或者说 —— 到底什么是 UI?
Definition: A User Interface (UI) is a system for assisting a user in selecting a function and providing a valid set of parameters to the function.
Definition: A Graphical User Interface (GUI) is a visual and interactive UI.
Sean Parent, 「Adobe Source Libraries Overview & Philosophy」, p49
在 GUI 时代,用户通过与可视元素交互,来选择一组命令及其参数。其中传给程序核心(Core)的命令参数,需确保符合特定的模型(Model),从而是合法的。
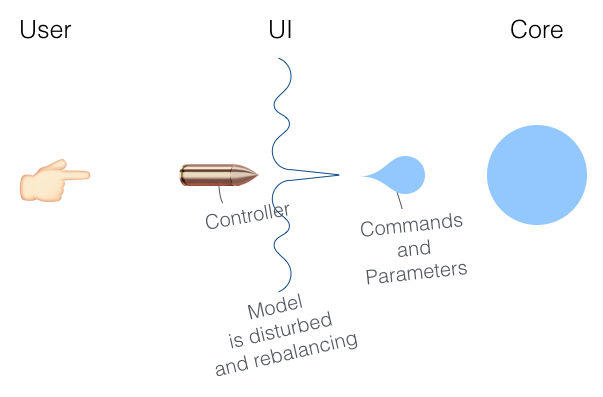
在文初的例子中,用户通过整合语音语义识别的输入法,或者符合某种格式的输入法,来输入命令和参数,参数同样需符合特定的模型(Model),来确保合法。换言之,不同的 UI 技术,有不同的方式来协助用户选择 命令和参数。但在参数合法性检查上,是共享的。
在量子理论中,从 A 传递能量给 B,是整数个量子,视作其完整性约束。而在 UI 定义中,UI 传递给程序核心(Core)是完整的一组参数,符合模型(Model)是其完整性约束。该种特点,本文特别称之为 量子化的 UI —— 在下文中,将介绍 Adobe Source Libraries 提出“量子化方案” —— 属性模型(Property Model)及其描述语言 Adam。
Adam ∙ 例子
由一个 “缩放图片的对话框” 说起:
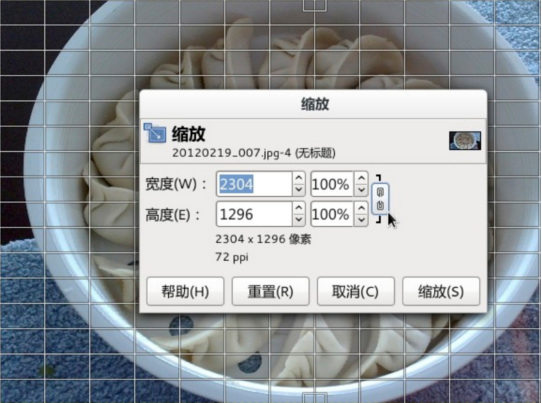
其中有缩放后宽度 combo 输入框两枚(单位分别是 像素,以及相对原始尺寸的 百分比),同样,缩放后高度也是 combo 输入框两枚。还有一钮,按下后会保持当前的宽高比。
该 UI 的模型(Model),由 Adam 如下描述:
sheet scale_image {
input:
ratio : 0.0;
original_width : 2304;
original_height : 1296;
interface:
width_pixels : original_width <== round(width_pixels);
width_percent;
height_pixels : original_height <== round(height_pixels);
height_percent;
logic:
relate {
width_pixels <== round(width_percent * original_width / 100);
width_percent <== width_pixels * 100 / original_width;
}
relate {
height_pixels <== round(height_percent * original_height / 100);
height_percent <== height_pixels * 100 / original_height;
}
when (ratio) relate {
width_percent <== height_percent * ratio;
height_percent <== width_percent / ratio;
}
output:
result <== { height: height_pixels, width: width_pixels };
}
这个名为 scale_image 的 sheet,含有若干个 cells(单元)。比如待缩放的图片宽度,由 input cell original_width 描述,为 2304;而 缩放后的宽度由 interface cell width_pixels 描述,其初值为 original_width。而 缩放后宽度 width_pixels 和 宽度缩放比例 width_percent 之关系由 relation cell 给出:
relate {
width_pixels <== round(width_percent * original_width / 100);
width_percent <== width_pixels * 100 / original_width;
}
可见,relation cell 像是一个 n 元方程式,n 个元的解式。来看看几个情形下,sheet scale_image 中的 relations 怎起的作用:
- 用户填入缩放后宽度(width_pixels)⟶ width_percent 重新计算。
- 用户点击锁定宽高比:
 (set ratio = width_percent / height_percent)。用户再更新 width_pixels ⟶ width_percent ⟶ height_percent ⟶ height_pixels 依次重新计算。
(set ratio = width_percent / height_percent)。用户再更新 width_pixels ⟶ width_percent ⟶ height_percent ⟶ height_pixels 依次重新计算。
最后,output cell result 是最终输出的结果,上例中其值是个字典{ height: height_pixels, width: width_pixels }。
除了上面出场 cell 类型外,还有 invariant cell,其作用相当于断言 —— 若布尔值为假,则所有参与计算的 cells 标记为有毒的(poison)。
cell 的类型参见附录。
Adam ∙ 内流透视
在前述例子中,一个 interface cell 有多个计算式,例如 width_pixels,有初值 :original_width,interface cell 中表达式 <== round(width_pixels) 和 relation cell 中的表达式 <== round(width_percent * original_width / 100);
那么 width_pixels 取值到底为多少?计算的步骤是怎样的??
再者,例中的 sheet 是怎样被解析的?比如 width_pixels: original_width <== round(width_pixels) 如何解析为 cell_t 结构体的?还有表达式的数据结构是什么?其值是怎样计算的?
下面先来看如何从 Adam 语言解析生成对应的数据结构,再来看看 cell 的值是如何计算的。对应代码位于:github。
解析(Parsing)
先来看看 interface cell width_pixels 是如何解析的?如下图:
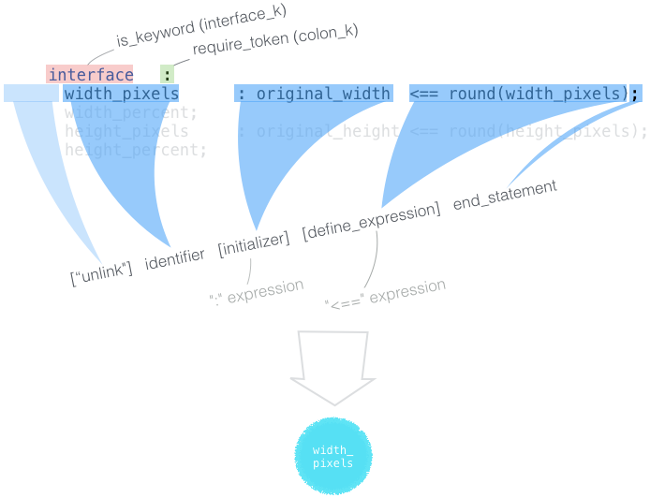
大体上是词法分析器(lexer)将输入流分割成一个个词素(如 keyword、identifier、iteral),然后再进行解析。其次需说明的是,一个 interface cell 实际上被解成了 两个 cell_t,分别是“input” 和 “out” 两部分。
而表达式的解析是按照运算符的优先级,按由弱到强的顺序:
is_or_expression // and_expression { "||" and_expression }
^^^^^^^^^^^^^^
is_and_expression // bitwise_or_expression { "&&" bitwise_or_expression }
^^^^^^^^^^^^^^^^^^^^^
is_bitwise_or_expression // bitwise_xor_expression { "|" bitwise_xor_expression }
...
is_postfix_expression // primary_expression { ("[" expression "]") | ("." identifier) }
^^^^^^^^^^^^^^^^^^
is_primary_expression // name | number | boolean | string | "empty" |
// array | dictionary | variable_or_fuction |
// ( "(" expression ")" )
表达式解析成数组 array_t,按照后缀表示法添入数组,操作数在前,操作符在后。
函数calculate_expression() / ... / virtual_machine_t::implementation_t::evaluate()来计算表达式的值:遇到操作数压栈value_stack_m,遇到操作符,从栈取出值,并将计算结果放回。
再来看看一个 relation cell 如何解析?例如下图:
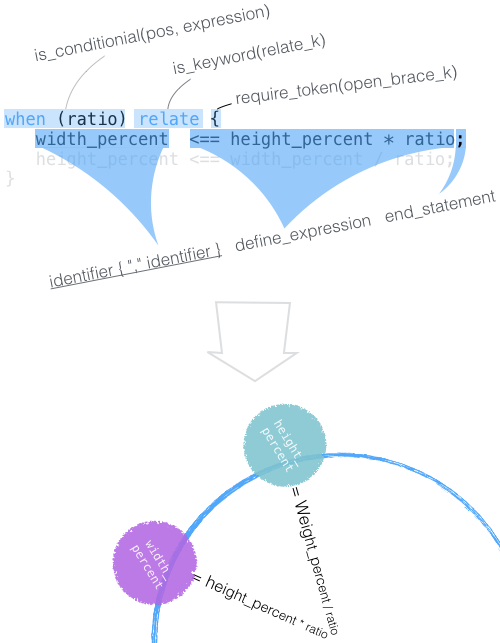
这里将保持“宽高比(ratio)”时 宽度缩放比 和 高度缩放比的关系(relation),画作一个圈:interface cell height_percent(宽度缩放比) 和 width_percent(高度缩放比)都在这个圈上。
计算 cell 之值
站在 width_pixels 角度,其计算式有 初始化表达式、interface 和 relation cell 中定义的表达式,其值是怎么计算出来的?
对于 interface cell 而言,解析后生成 input 和 output 两 cells:
- 对于 input 部分的 cell,其值存于成员变量 state_m,或由 sheet_t::implementation_t::set() 来设置;或由构造时,初始化表达式计算而来(函数路径:add_interface()/initialize_one())。该值可能参与:
- ouput 部分的值计算(见下点)。
- 其他 interface cell 的初值计算。例如,若存在 interface cell
width_dpi: width_pixels * 48 / SCREEN_DPI,计算初始化表达式时,width_pixels 取初值 “original_width,即 2304”。
- 对于 output 部分的 cell,其值存于成员变量 state_m,在 sheet_t::implementation_t::get() 中计算得:
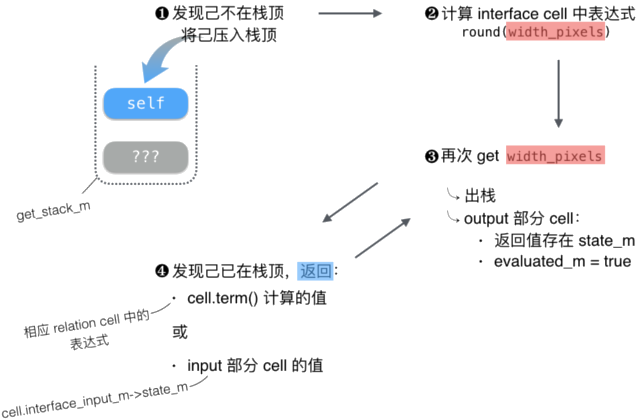
- 通常而言,当 output 部分 cell 值更新后,input 部分 cell 值也会同步成该值,除非指定了 “unlink” 关键字。
更新 sheet
当用户输入缩放后宽度,函数 sheet_t::implementation_t::set() 被调用,width_pixels 的值和优先级(priority)被更新。接着,调用函数sheet_t::implementation_t::update()同步 sheet 中的全部 cells:
处理“有条件的 relation cell(s)”,即 “when(p) relate { … }”。计算条件中的表达式 p,将前提条件不成立的 relation cell(s),全部标记为已解决(resolved_m = true)。
flow() ,前述
get()示意中步骤 ❹ 中的 term_m 在此阶段确立。遍历
output_index_m,对于表达式未被计算的 cells(!evaluated_m),计算之(计算出的值存于 state_m,evaluated_m 置为 true),对于 interface cell(s),还会同步 input 和 ouput 部分 cell 的值。遍历
invariant_index_m,同上进行表达式计算。当算出的布尔值为假,所有参与计算的 cells 被标记为有毒(poison)。- 再次遍历
output_index_m,对有变化的 cell(s) 调用通知函数:- 无效状态发生变化的:例如,原值有效,现参与值计算的某个 cell 有毒,于是变为无效。
- 原值 与 现值 不相等。
- 参与计算的 cell(s) 与上次不同(TODO)。
- 通过 sheet_t::implementation_t::monitor_enabled 监视的 “input”/“interface (input)” cell,其启用状态发生变化,调用通知函数。以下条件认为 cell 启用:
- 在第二步 flow() 中,访问过其优先级(priority)。
- 或参与计算 output cell 的值(对于 interface cell,注意须是 input 部分参与)。
- 参与计算其他 cell 的值,且参数指定的一组 cell(s) 之优先级被访问过。
flow()
在 flow 过程中,从最近更新的 interface cell(s) 起,将更新传到 relations 中的各个 cells。可以说,少数几个刚刚更新的 cell(s),决定了 sheet 的输出结果 —— output cell。
前文图示如何解析生成 relation cell,将 relation cell 画作一个圈,圈入若干个涉及该 relation 的 interface cells。对应到代码:这些 interface cells 都记录在 relation_cell_t 之成员变量 edges_m。
继续我们的“画风”,那么前文 scale_image sheet 中的 relations 可以画成下面酱紫:
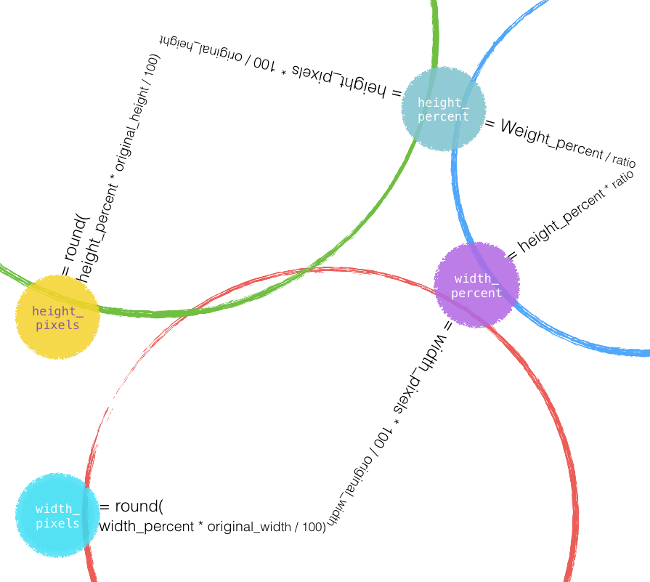
从图中可见 interface cell width_percent 在两个 relations 的圈上。对应到代码:就是说这两个 relation cells 都记录在 width_percent.relation_index_m,且 width_percent.initial_relation_count_m == 2。当这个两个 relations 都被满足时,有:
- 对两个 relation cells,有
resolved_m == true。 width_percent.relation_count_m == 0
再回首前文例子,假设用户锁定当前宽高比(set ratio = width_percent / height_percent),并输入了 width_pixels ,于是开始 sheet.update() ⟶ flow():
- 首先由尚未 resolved relation cells,“收集圈上的 interface cells”,并按照优先级排序:width_pixels > height_percent > height_pixels > width_percent。
-
按照优先级遍历上述诸 interface cells:
- 标记 width_pixels.resolved_m = true,表示在 flow 中,本 cell 自身事务已了。
- width_pixels 所在 relation:
--width_pixels.relation_count_m,代表 width_pixels 不再“阻碍”此 relation 的解决,故 “阻碍 relations 们计数”减少。- 这是一个两元关系,width_pixels 已知(resolved),于是 width_percent.term_m 被确定下来,为 “width_pixels * 100 / original_width”。
- 同时
--width_percent.relation_count_m、本 relation 也被解决(标记 relsoved_m = true)。
- 标记 width_percent.resolved_m = true。注:这是 width_pixels 更新引起的“涟漪”,故动态调整了优先排序 —— 这种优先级因输入输出而产生动态流动传递,是否对调度器也有所启发呢?
- width_percent 所在(未解决)relation:
--width_percent.relation_count_m- 同样是一个两元关系,width_percent 已知(resolved),于是 height_percent.term_m 被确定,为 “width_percent / ratio”。
- 同时
--height_percent.relation_count_m、本 relation 也被解决(标记 relsoved_m = true)。
- 标记 height_percent.resolved_m = true。
- height_percent 所在(未解决)relation:
--height_percent.relation_count_m- 同样是一个两元关系,height_percent 已知(resolved),于是 height_pixels.term_m 被确定,为 “round(height_percent * original_height / 100)”。
- 同时
--height_pixels.relation_count_m、本 relation 也被解决(标记 relsoved_m = true)。
后记:C++ 是一种什么样的语言?
Adam 使用 C++ 实现,例如其中一个重要的数据结构sheet_t::implementation_t::index_t:
typedef hash_index<cell_t, std::hash<name_t>, equal_to, mem_data_t<cell_t, const name_t>> index_t;
// 从 hash_index 构造函数来看
template <typename F> // F is convertible to key_function_type
hash_index(hasher hf, key_equal eq, F kf)
: index_m(0, hf, eq, compose(key_function_type(kf), indirect<value_type>())) {}
// hash_index::index_m 是甚结构?
typedef closed_hash_set<pointer, indirect_key_function_type, hasher, key_equal> index_type;
index_type index_m;
// hash_index 是个外壳,index_m 才是内在,如
iterator find(const key_type& x) { return iterator(index_m.find(x)); }
iterator insert(iterator i, value_type& x) { return iterator(index_m.insert(i, &x)); }
...
由内而外来看:
- closed_hash_set,是个用 closed hashing 实现的 set:
- set 保证元素无重复,此处借内在实现为哈希表来达到的:查询时输入元素本身,返回元素在 set 中的位置(iterator)。
- closed hash 表示哈希表的容量是固定的(closed):哈希碰撞时 不 用链表共享同一位桶的方案(不然哈希容量是无限的)。
- 将 pointer 指向的元素本身作为 产生 key 的原料;key 借助 hasher 生成哈希码,借助 key_equal 排除哈希码“撞衫”情形,确保为真相等。
- indirect_key_function_type:输入元素本身,返回元素某个成员来作为 key。
// key_function_type 实际上就是 hash_index 中传入的 mem_data_t
// 后者返回 cell_t::name_m
typedef unary_compose<key_function_type, indirect<value_type>> indirect_key_function_type;
// indirect 是一个对指位器进行 '*' 取值操作,并将引用返回
// 由于返回引用,故称为 indirect
template <typename T>
struct indirect {
template <typename P> // models TrivialIterator where value_type(P) == T
T& operator()(P x) const { return *x; }
};
- hash_index 包装出一种风格,让 name_t 和 cell_t 混着用:
- name_t 是 cell 名字。是字符串(一一)对应到一数字,类似 glib 中的 GQuark。
- find 时,可以用 name_t 来找到 iterator。
- insert 时,又从 cell_t::name_m 获得 name_t 来作为 key。
由此是不是隐隐觉得,原汁原味的 C++ 编程,需先存着实现和逻辑上的概念,接着织一张类型上的交通网,有了上层的风格,然后开始自由构筑?
或者说,C++ 编程是否分两段式:先元编程,构筑风格、甚至在某种程度上 —— 语言;然后再用这种风格或者说语言来编程?
打个比方,目下创业潮,有人打算创业,他采取了 “C++” 的思维方式:新的公司到底划分几个层次,几个部门好呢?怎么为上市做财务方面的制度安排呢?... 如果没想好,今写好的一切,明儿就得重写。
再打个比方,有没有学外语时,说话先思念着语法的赶脚?有人出来把 C++ 两段式编程,第一段泛化、抽象出 ... 一种语言,猿们编程时就可直接上第二段??
在可编译语言界,Swift 也许就是这样一语言?
附录: cell 类型列表
| Cell Type | 图示 | 示例 | 备注 |
| input |  | input: ratio: 0.0 | input_index_m (has prioriry) |
| interface |  | interface: w: orig_w <== round(w); | input_index_m (has prioriry), output_index_m |
| logic |  | logic: a = b + c | 表达式 缩记 / 运算结果复用 |
| relation | 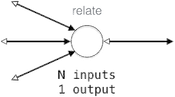 | logic: relate { w = w_percent * orig_w / 100; w_percent = w * 100 / orig_w; } | |
| when…relation |  | logic: when (ratio) relate { w_percent = h_percent * ratio; h_percent = w_percent / ratio; } | |
| output | 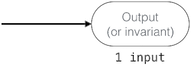 | output: result <== { width: w, height: h }; | output_index_m |
| invariant | invariant: check <== a < b; | invariant_index_m |
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
