

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 456904: 避免磁盘回写(writeback),抑制(throttling)缓存(page cache)写入
请点击 LWN 中文翻译计划,了解更多详情。
原文:No-I/O dirty throttling 原创:By corbet @ Aug. 31, 2011 翻译:By unicornx 校对:By Evan Zhao
“Writeback” is the process of writing dirty pages back to persistent storage, allowing those pages to be reclaimed for other uses. Making writeback work properly has been one of the more challenging problems faced by kernel developers in the last few years; systems can bog down completely (or even lock up) when writeback gets out of control. Various approaches to improving the situation have been discussed; one of those is Fengguang Wu’s I/O-less throttling patch set. These changes have been circulating for some time; they are seen as having potential - if only others could actually understand them. Your editor doesn’t understand them either, but that has never stopped him before.
“回写”(”Writeback”,译者注,下文直接使用不再翻译) 指的是将 “脏” 页写回持久存储(即磁盘)的过程,从而允许这些缓存页可以被回收(reclaim)用于其他用途。在过去几年中,如何使 writeback 更好地工作一直是内核开发人员所面临的最具挑战性的难题之一;特别地当 writeback 失去控制时,系统可能会完全陷入困境(甚至无法运行)。社区已经讨论了多种方法力图改善该问题;其中之一是来自 Fengguang Wu 的 “I/O-less throttling” 补丁集(译者注,这个补丁集的名字来自于补丁集中一个最主要的补丁的描述,其核心思想是:一方面取消在 balance_dirty_pages() 函数(该函数会在 write() 系统调用中被调用)中执行 writeback 的操作,从而避免磁盘 I/O,另一方面根据 “脏” 页的数量动态地抑制(throttling)缓存(page cache)写入的速度,使得 “脏” 页的产生和对 “脏” 页的回写(由后台 flusher 线程异步实现)的速度之比维持在合理的范围内,具体介绍请参考本文第二节和第三节的描述)。这个补丁已经存在了有一段时间了;其算法思想较为复杂难懂,但被认为是最具有解决问题潜力的。说实话我也觉得该补丁不太好理解,但在这里我还是要尽自己最大的努力为大家梳理一下这个补丁集的内容。
One aspect to getting a handle on writeback, clearly, is slowing down processes that are creating more dirty pages than the system can handle. In current kernels, that is done through a call to
balance_dirty_pages(), which sets the offending process to work writing pages back to disk. This “direct reclaim” has the effect of cleaning some pages; it also keeps the process from dirtying more pages while the writeback is happening. Unfortunately, direct reclaim also tends to create terrible I/O patterns, reducing the bandwidth of data going to disk and making the problem worse than it was before. Getting rid of direct reclaim has been on the “to do” list for a while, but it needs to be replaced by another means for throttling producers of dirty pages.
通过执行 writeback ,我们可以减缓由于任务快速产生 “脏” 页而对系统缓存造成的压力。在当前内核代码中(译者注,3.1 及其之前),这是通过(在 write() 系统调用中)调用 balance_dirty_pages() 函数来完成的,该函数内部会暂停写入操作,转而去执行 writeback 的操作,将 “脏” 页写回磁盘。这种 “直接回收”(”direct reclaim”)的操作方式可以起到快速清理一些 “脏” 页的效果;同时还可以防止在 writeback 发生时又有更多的缓存页被弄 “脏”。不幸的是,这么做会引起令人讨厌的磁盘读写操作,挤占了其他读写磁盘操作的带宽,使得问题变得更糟糕。避免 direct reclaim 的工作一直在内核的 “待办事项” 清单上还未彻底解决,但我们这里可以考虑从另一个方向来解决这个问题,就是抑制(throttling)任务产生 “脏” 页的速度。
That is where Fengguang’s patch set comes in. He is attempting to create a control loop capable of determining how many pages each process should be allowed to dirty at any given time. Processes exceeding their limit are simply put to sleep for a while to allow the writeback system to catch up with them. The concept is simple enough, but the implementation is less so. Throttling is easy; performing throttling in a way that keeps the number of dirty pages within reasonable bounds and maximizes backing store utilization while not imposing unreasonable latencies on processes is a bit more difficult.
Fengguang 所带来的 补丁集 的目的即在于此。他试图采用的方法是,首先确定每个任务在任何给定时间点上允许写(弄 “脏”)缓存的个数。超过限制的任务只需被暂停(休眠)一段时间以便负责 writeback 的后台任务有时间及时对 “脏” 页进行清理。这个想法很简单,但实现起来却有一定的难度。简单地抑制写缓存的速度很容易(译者注,指通过休眠任务);但是,在限制 “脏” 页数目保持在一个合理的范围内的同时,还要考虑在最大化磁盘吞吐率、和避免任务处理上不合理的延迟之间达到一个平衡,这着实会有点困难。
If all pages in the system are dirty, the system is probably dead, so that is a good situation to avoid. Zero dirty pages is almost as bad; performance in that situation will be exceedingly poor. The virtual memory subsystem thus aims for a spot in the middle where the ratio of dirty to clean pages is deemed to be optimal; that “setpoint” varies, but comes down to tunable parameters in the end. Current code sets a simple threshold, with throttling happening when the number of dirty pages exceeds that threshold; Fengguang is trying to do something more subtle.
对于一个系统来说,如果所有的缓存都是 “脏” 页,那系统是无法运行的,这也是我们要竭力避免的。从另一个极端来说,一个 “脏” 页也没有也不见得是什么好事,可以想象在这种条件下系统的性能表现一定会很糟糕。因此,虚拟存储子系统的目标就是要找到一个平衡,使得 “脏” 页数与非 “脏” 页数之间的比例最佳;这个 “平衡点” (”setpoint”,译者注,下文直接使用不再翻译)随运行的实际条件变化而变化,内核上最终实现为一个可调的参数。当前代码中实现抑制(throttling)处理的算法十分简单,仅仅定义了一个简单的阈值,当 “脏” 页数超过该阈值时就执行抑制;而 Fengguang 则试图改进抑制(throttling)算法,采用更精细化的方法对写入速度进行控制。
Since developers have complained that his work is hard to understand, Fengguang has filled out the code with lots of documentation and diagrams. This is how he depicts the goal of the patch set:
鉴于大家抱怨他的代码很难理解,Fengguang 在代码之外还提供了大量的文档说明和图表。下图描述了他的设计意图(译者注,更详细的描述请参考 “commit: writeback: dirty position control” 中 bdi_position_ratio() 函数前的注释。):
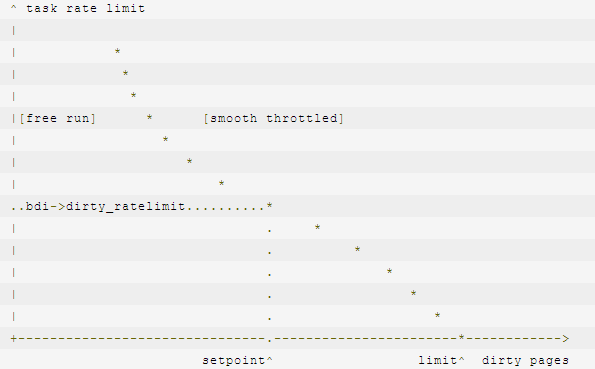
The goal of the system is to keep the number of dirty pages at the setpoint; if things get out of line, increasing amounts of force will be applied to bring things back to where they should be. So the first order of business is to figure out the current status; that is done in two steps. The first is to look at the global situation: how many dirty pages are there in the system relative to the setpoint and to the hard limit that we never want to exceed? Using a cubic polynomial function (see the code for the grungy details), Fengguang calculates a global “pos_ratio” to describe how strongly the system needs to adjust the number of dirty pages.
系统的目标是将 “脏” 页数维持在 setpoint;随着 “脏” 页变多,对任务写操作的抑制将会增强,最终使得 “脏” 页的数量回落到应有的位置。因此,首先要确定当前 “脏” 页的数量;这部分工作分两步完成。第一步是查看全局的情况:即整个系统中当前 “脏” 页数相对于 setpoint 和最大限制(图上的 limit)还差多少。Fengguang 的算法中使用一个三次多项式函数来计算一个全局的 “pos_ratio” 值,该值用于描述系统调整 “脏” 页写入的强度(晦涩的细节可以参考代码,译者注,原文的代码链接已失效,这里参考内核合入该补丁的 “commit: writeback: dirty position control”)。
This ratio cannot really be calculated, though, without taking the backing device (BDI) into account. A process may be dirtying pages stored on a given BDI, and the system may have a surfeit of dirty pages at the moment, but the wisdom of throttling that process depends also on how many dirty pages exist for that BDI. If a given BDI is swamped with dirty pages, it may make sense to throttle a dirtying process even if the system as a whole is doing OK. On the other hand, a BDI with few dirty pages can clear its backlog quickly, so it can probably afford to have a few more, even if the system is somewhat more dirty than one might like. So the patch set tweaks the calculated pos_ratio for a specific BDI using a complicated formula looking at how far that specific BDI is from its own setpoint and its observed bandwidth. The end result is a modified pos_ratio describing whether the system should be dirtying more or fewer pages backed by the given BDI, and by how much.
但是,如果只考虑系统级别的状态,而不考虑每个磁盘(即 backing device,简称 BDI)的处理情况,是无法真正计算得到最终的 ratio (即 pos_ratio )值的。一个任务所写入(弄 “脏”)的缓存所对应的数据最终存放的对象是磁盘,对整个系统来说有可能当前的总 “脏” 页量是超标的,但对于一个更精细化的算法来说,是否要抑制该任务,则还要考虑其操作的磁盘所关联的 “脏” 页量是否也超标。所以,如果某个磁盘所对应的 “脏” 页量是超标的,即使整个系统的 “脏” 页状态正常,也可能有必要抑制该任务。反之,具有少量 “脏” 页的磁盘因为其 “脏” 页可以被快速清除,因此即使系统整体上 “脏” 的标准超过了我们的要求,我们也没有必要抑制针对该磁盘的缓存写入。总而言之,补丁集参考了每个磁盘对应的缓存 “脏” 页与其自身的 setpoint (译者注,bdi_setpoint)值之间的差额以及磁盘的读写带宽状态,使用了一个复杂的公式对系统级别的 pos_ratio 值进行修正,从而最终决定对缓存的写入控制当前是该放松还是收紧,以及具体控制的数量值。
In an ideal world, throttling would match the rate at which pages are being dirtied to the rate that each device can write those pages back; a process dirtying pages backed by a fast SSD would be able to dirty more pages more quickly than a process writing to pages backed by a cheap thumb drive. The idea is simple: if N processes are dirtying pages on a BDI with a given bandwidth, each process should be throttled to the extent that it dirties 1/N of that bandwidth. The problem is that processes do not register with the kernel and declare that they intend to dirty lots of pages on a given BDI, so the kernel does not really know the value of N. That is handled by carrying a running estimate of N. An initial per-task bandwidth limit is established; after a period of time, the kernel looks at the number of pages actually dirtied for a given BDI and divides it by that bandwidth limit to come up with the number of active processes. From that estimate, a new rate limit can be applied; this calculation is repeated over time.
理想状态下,抑制(throttling)的目标是使得缓存被弄 “脏” 的速度与将这些 “脏” 页写回磁盘的速度持平;如果一个任务所写入的设备对应的是快速的 SSD,则其产生 “脏” 页的速度比起对应的设备是一个廉价的 U 盘的情况下要快得多。比较简单的考虑是:假设磁盘的读写带宽一定(即 writeback 的速度一定),如果存在 N 个任务对该磁盘执行写操作,则每个任务写入缓存(弄 “脏” 缓存)的速度应该被限制为总读写带宽的 N 分之一。但问题是当任务对某个磁盘执行写入操作时并不会通知内核,所以内核无法真正知道 N 的值。补丁采取的处理方法是在运行过程中对 N 值进行动态估算。首先设定一个初始状态下每个任务执行写操作的速度限制(译者注,参考补丁描述中的 task_ratelimit_0);一段时间后,内核查看给定磁盘上实际被弄 “脏” 的页数,并将其除以该速度限制,从而得出对该磁盘执行写操作的活动任务的数量。然后根据该估计的 N 值,可以得到一个新的速度限制(译者注,即补丁描述中的 bdi->dirty_ratelimit);每隔一个周期就采用同样的方法估算一次。(译者注,本段描述涉及的相关补丁参考 “commit: writeback: dirty rate control”)
That rate limit is fine if the system wants to keep the number of dirty pages on that BDI at its current level. If the number of dirty pages (for the BDI or for the system as a whole) is out of line, though, the per-BDI rate limit will be tweaked accordingly. That is done through a simple multiplication by the pos_ratio calculated above. So if the number of dirty pages is low, the applied rate limit will be a bit higher than what the BDI can handle; if there are too many dirty pages, the per-BDI limit will be lower. There is some additional logic to keep the per-BDI limit from changing too quickly.
如果系统想要将一个该磁盘上的 “脏” 页数保持在当前水平(译者注,即上节所说的 “持平” 状态),则利用上节所述方法计算得到的速度限制(rate limit)就可以了。但是,如果 “脏” 页数(对于单个磁盘或整个系统)超标了,则需要进一步调整该磁盘的写入速度限制。这是通过和上面计算得到的 pos_ratio 进行简单的乘法来完成。这么做的结果是,当 “脏” 页数较少时,则实际应用的速度限制将略高于磁盘可以处理的速度限制;如果 “脏” 页太多,则对磁盘的写入抑制将更严格。除此之外代码还采取了一些其他的措施避免针对单个磁盘的抑制变化太快。(参考 “commit: writeback: stabilize bdi->dirty_ratelimit”)
Once all that machinery is in place, fixing up
balance_dirty_pages()is mostly a matter of deleting the old direct reclaim code. If neither the global nor the per-BDI dirty limits have been exceeded, there is nothing to be done. Otherwise the code calculates a pause time based on the current rate limit, the pos_ratio, and number of pages recently dirtied by the current task and sleeps for that long. The maximum sleep time is currently set to 200ms. A final tweak tries to account for “think time” to even out the pauses seen by any given process. The end result is said to be a system which operates much more smoothly when lots of pages are being dirtied.
以上机制具备后,剩下的就是修改 balance_dirty_pages() 函数了,主要是删除旧的直接回写代码(译者注,原文是 direct recliam,但实际删除的代码是 writeback_inodes_wb(),所以还是翻译为 “回写”)。如果对于全局和单个磁盘来说写入的速度都还没有超过限制,则无需做任何事情。否则,代码根据当前的速度限制(rate limit),pos_ratio 和最近被当前任务弄 “脏” 的页框数量来计算当前任务的暂停(pause)时间,并按照该时间让该任务执行睡眠。睡眠时间的最大限制目前设置为 200ms (以上参考 “commit: writeback: IO-less balance_dirty_pages()”)。最后采用所谓 “思考时间” (”think time”)的方式来平衡任务的暂停时间(译者注,有关 “think time” 的概念在最终提交到主线的代码中已不存在,但对 rate limit 的调整仍然存在,可以参考 “commit: writeback: limit max dirty pause time” 和 “commit: writeback: control dirty pause time”)。最终达到的效果是,当存在大量缓存页被 “弄脏” 时,该系统仍然可以流畅地运行。
(译者注,考虑到 Fengguang 算法的复杂性,这里简单总结一下本文的介绍思路,希望能够帮助读者理解。参考 “commit: writeback: IO-less balance_dirty_pages()”,balance_dirty_pages() 函数中有如下逻辑:
task_ratelimit = (u64)dirty_ratelimit * pos_ratio >> RATELIMIT_CALC_SHIFT;
pause = (HZ * pages_dirtied) / (task_ratelimit | 1);
其中 pause 是我们最终希望得到的用于抑制写入任务的休眠时间,该时间和 task_ratelimit 有关,而 task_ratelimit 与 pos_ratio 和 dirty_ratelimit 这两个参数有关。其中本文的第 5、6 小节介绍的是 pos_ratio 的计算,对应代码 “commit: writeback: dirty position control”;第 7、8 和 9 小节介绍了 dirty_ratelimit 的计算,对应代码 “commit: writeback: dirty rate control” 和 “commit: writeback: stabilize bdi->dirty_ratelimit”。上一节,也就是第 10 节介绍了最终对 balance_dirty_pages() 函数的改造,包括避免磁盘回写(writeback)和抑制(throttling)的最终实现。)
Fengguang has been working on these patches for some time and would doubtless like to see them merged. That may yet happen, but adding core memory management code is never an easy thing to do, even when others can easily understand the work. Introducing regressions in obscure workloads is just too easy to do. That suggests that, among other things, a lot of testing will be required before confidence in these changes will be up to the required level. But, with any luck, this work will eventually result in better-performing systems for us all.
Fengguang 开发这个补丁已经有一段时间了,无疑非常期望将其合入内核主线。这是很有可能的,但要知道,即使其他人已经可以轻松地理解这个补丁,想给核心的内存管理代码添加功能也绝不是一件容易的事情。稍不注意。内核的性能就可能在某些意想不到的工作负载下出现倒退。总之,为了让大家有信心接受这个补丁,除了开发工作和解释之外,还需要运行大量的测试。但是,如果不出意外的话,该补丁最终应该会被内核接纳并让我们的系统性能变得更好(译者注,该补丁 随 3.2 版本合入内核主线)。
请点击 LWN 中文翻译计划,了解更多详情。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
