

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 372384: 改善文件预读(readahead)
Zhao Yimin 创作于 2019/01/23
请点击 LWN 中文翻译计划,了解更多详情。
原文:Improving readahead 原创:By Jonathan Corbet @ Feb. 3, 2010 翻译:By Tacinight of TinyLab.org 校对:By unicornx of TinyLab.org
Readahead is the process of speculatively reading file data into the page cache in the hope that it will be useful to an application in the near future. When readahead works well, it can significantly improve the performance of I/O bound applications by avoiding the need for those applications to wait for data and by increasing I/O transfer size. On the other hand, readahead risks making performance worse as well: if it guesses wrong, scarce memory and I/O bandwidth will be wasted on data which will never be used. So, as is the case with memory management in general, readahead algorithms are both performance-critical and heavily based on heuristics.
预读机制(Readahead)指的是预测性地读取文件数据到页缓存(page cache)中,寄希望于这些数据能在不久的将来被使用到。当预读发挥作用时,它能显著改善对 I/O 敏感应用的性能,通过提高 I/O 传输的大小来避免应用为了等待数据而产生的阻塞。另一方面,预读也有让性能变糟糕的风险。如果它预测错误,那么稀缺的内存和 I/O 带宽就会被浪费在那些永远也用不上的数据上。所以这同通常的内存管理一样,预读的算法既是性能敏感的,又重度依赖于启发算法。
As is also generally the case with such code, few people dare to wander into the readahead logic; it tends to be subtle and quick to anger. One of those who dare is Wu Fengguang, who has worked on readahead a few times over the years. His latest contribution is this set of patches which tries to improve readahead performance in the general case while also making it more responsive to low-memory situations.
这类代码通常也十分复杂,很少有人敢于挑战对其进行修改,它是如此的喜怒无常,稍不留心就可能造成严重的后果。现在有一个敢于挑战的人出现了,他就是 Wu Fengguang,在过去的几年他专研于预读领域。他最近的一个贡献就是提交了一个补丁集,这些补丁不仅在常规层面改善了预读的性能,同时也兼顾了内存资源较少的情况。
The headline feature of this patch set is an increase in the maximum readahead size from 128KB to 512KB. Given the size of today’s files and storage devices, 512KB may well seem a bit small. But there are costs to readahead, including the amount of memory required to store the data and the amount of I/O bandwidth required to read it. If a larger readahead buffer causes other useful data to be paged out, it could cause a net loss in system performance even if all of the readahead data proves to be useful. Larger readahead operations will occupy the storage device for longer, causing I/O latencies to increase. And one should remember that there can be a readahead buffer associated with every open file descriptor - of which there can be thousands - in the system. Even a small increase in the amount of readahead can have a large impact on the behavior of the system.
这个补丁集的首要特性就是将每次预读窗口大小的最大值从 128KB 增加到了 512KB。考虑到如今的文件和存储设备大小,512KB 似乎显得有点小了。但是预读仍是有代价的,这包括了用于存储数据的内存空间以及所占用的 I/O 带宽。如果一个大的预读缓冲导致了其他有用的数据被换出主存,即使预读的数据都被证明是有用的,那么它也只会导致系统性能的净亏损。更大的预读窗口大小也意味着更长地占有存储设备,导致 I/O 操作的延迟增加。另外,我们应该明白:就是每一个预读的缓冲都和一个打开的的文件描述符相关联,这些文件描述符可能在系统中有上千个。因此预读操作即使小规模增加都可能对系统产生较大的影响。
The 512K number was reached by way of an extensive series of benchmark runs using both rotating and solid-state storage devices. With rotating disks, bumping the maximum readahead size to 512KB nearly tripled I/O throughput with a modest increase in I/O latency; any further increases, while increasing throughput again, caused latency increases that were deemed to be unacceptable. On solid-state devices the throughput increase was less (on a percentage basis) but still significant.
512KB 这个值的由来是基于大量的基准测试,其中同时包括了机械硬盘以及固态硬盘。在机械硬盘中,将预读窗口大小的最大值激增至 512KB 带来了将近 3 倍的 I/O 吞吐量的提升,以及 I/O 延迟中等幅度的增加。往后对预读窗口大小的增加都能带来吞吐量的提升,但随之而来增加的延迟却让人无法接受。在固态硬盘中,吞吐量的提升较少(按百分比计算)但仍然很显著。
These numbers hold for a device with reasonable performance, though. A typical USB thumb drive, not being a device with reasonable performance, can run into real trouble with an increased readahead size. To address this problem, the patch set puts a cap on the readahead window size for small devices. For a 2MB device (assuming such a thing can be found), readahead is limited to 4KB; for a 2GB drive, the limit is 128KB. Only at 32GB does the full 512KB readahead window take effect.
但是这些数据只适用于那些有着理想性能的设备。U 盘就是一个典型的例外,它在增加预读窗口大小时会发生问题。为了解决这个问题,补丁集专为小容量设备添加了一个预读窗口大小的上限。对于一个 2MB 的设备(假设这样的设备存在),预读的大小被限制在了 4KB 以内;而对于一个 2GB 的设备,这个限制就变成了 128KB。只有当设备到达 32GB 时,完整的 512KB 最大值才能生效。
This heuristic is not perfect. Jens Axboe protested that some solid-state devices are relatively small in capacity, but they can be quite fast. Such devices may not perform as well as they could with a larger readahead size.
这样的启发式并不完美。Jens Axboe 反对道,对于一些固态设备,它们容量相对而言比较小,但是它们确实非常快。这些设备因为预读最大值的设置而不能完美地发挥他们的性能。
Another part of this patch set is the “context readahead” code which tries to prevent the system from performing more readahead than its memory can handle. For a typical file stream with no memory contention, the contents of the page cache can be visualized (within your editor’s poor drawing skills) like this:
这个补丁集的另一部分就是 “上下文预读(context readahead)”,它能阻止系统去预读超出他内存容量之外的部分。对于一个典型的没有内存竞争的文件流,它的页缓冲大致可以画成这样(作者:请原谅我糟糕的作图)。
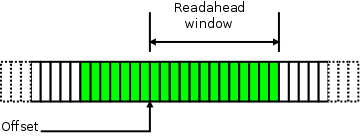
Here, we are looking at a representation of a stream of pages containing the file’s data; the green pages are those which are in the page cache at the moment. Several recently-consumed pages behind the offset have not yet been evicted, and the full readahead window is waiting for the application to get around to consuming it.
这里,我们看到的是包含文件数据的连续页框数组,绿色的页表示它们正处在页缓冲之中,多个刚被使用完的页还没有清理出去,而整个预读的窗口正在等待应用程序前来使用它们。
If memory is tight, though, we could find a situation more like this:
如果内存很紧张,我们就可能发现这样一种情形:
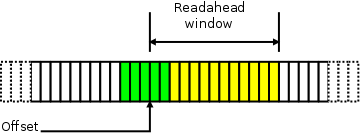
Because the system is scrambling for memory, it has been much more aggressive about evicting this file’s pages from the page cache. There is much less history there, but, more importantly, a number of pages which were brought in via readahead have been pushed back out before the application was able to actually make use of them. This sort of thrashing behavior is harmful to system performance; the readahead occupied memory when it was needed elsewhere, and that data will have to be read a second time in the near future. Clearly, when this sort of behavior is seen, the system should be doing less readahead.
现在系统正在争用内存,它会非常积极地将文件数据写回,从而把空间让出来。历史上发生的次数不多,但要命的是,那些通过预读进来的页,在应用还没来得及使用他们之前就被赶出去了。这样抖动(thrashing)的行为对系统的性能非常有害。预读在内存吃紧的情况下占据的宝贵的空间。显然,当出现这样的情形时,系统应该减少预读行为的发生。
Thrashing behavior is easily detected; if pages which have already been read in via readahead are missing when the application tries to actually read them, things are going amiss. When that happens, the code will get an estimate of the amount of memory it can safely use by counting the number of history pages (those which have already been consumed by the application) which remain in the page cache. If some history remains, the number of history pages is taken as a guess for what the size of the readahead window should be.
抖动现象很容易被检查出来,如果通过预读读进来的文件数据在应用程序想要真正使用时却不见了,那么事情就有点不对劲了。当这样的情况发生时,代码将通过计算保留在页缓冲中的历史页面(history pages, 那些已经被应用程序使用的历史页面)的数量来估计它可以安全使用的内存量,如果一些历史页面仍然存在于内存中,那么这些历史页面的数量可被看作下次对预读窗口大小的一个估算。
If, instead, there’s no history at all, the readahead size is halved. In this case, the readahead code will also carefully shift any readahead pages which are still in memory to the head of the LRU list, making it less likely that they will be evicted immediately prior to their use. The file descriptor will be marked as “thrashed,” causing the kernel to continue to use the history size as a guide for the readahead window size in the future. That, in turn, will cause the window to expand and contract as memory conditions warrant.
如果并没有预读历史,那么预读的窗口大小会减半。这样的话,预读的代码仍会小心的移动内存中的页到一个 LRU 列表的头部。这样能在考虑它使用频率的情况下减少它被换出内存的可能。文件描述符也会被标记为抖动的,致使内核会继续使用他的历史大小作为预读窗口大小的参考值。这反过来又会导致窗口在内存条件允许的情况下进行扩展和收缩。
Readahead changes can be hard to get into the mainline. The heuristics can be tricky, and, as Linus has noted, it can be easy to optimize the system for a subset of workloads:
The problem is, it's often easier to test/debug the "good" cases, ie the cases where we _want_ read-ahead to trigger. So that probably means that we have a tendency to read-ahead too aggressively, because those cases are the ones where people can most easily look at it and say "yeah, this improves throughput of a 'dd bs=8192'".
对预读机制的改动很难被并入主线。启发式算法非常地棘手,正如 Linus 提到的,根据一个特定的负载来优化系统是一件非常容易的事情。
真正的问题是,我们通常很容易根据一个“好”的例子来进行测试或者调试,例如那些我们想要预读机制去触发的情况。它也意味着我们倾向于读取更多的东西,偏偏那些例子是我们最容易看到的,像是“你看,这样就改善了命令`dd bs=8192`结果的吞吐量。”
The stated goal of this patch set is to make readahead more aggressive by increasing the maximum size of the readahead window. But, in truth, much of the work goes in the other direction, constraining the readahead mechanism in situations where too much readahead can do harm. Whether these new heuristics reliably improve performance will not be known until a considerable amount of benchmarking has been done.
这个补丁集既定目标就是通过增加预读窗口的最大值,从而使得预读行为更加激进。但是,实际上,很多工作都是朝着相反的方向进行的,这限制了读取机制,因为在这种情况下,提前读取太多会对系统性能造成损害。新启发式是否能可靠地改善性能?在大量的基准测试完成之前我们还不得而知。
请点击 LWN 中文翻译计划,了解更多详情。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
