

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
文件系统简介:bcachefs(二)
by Chen Jie of TinyLab.org 2023/08/14
前言
文件系统是建立在 block 层之上的、VFS 接口的一个实现。
本系列以新晋的 COW 文件系统 - bcachefs 为例,一探文件系统的如何工作:
首篇 从 block 层视角,介绍了 bcachefs 落盘的序列化格式,以及加载回的反序列化过程。
而本篇将从 VFS 视角,简介读取文件中的一块内容 —— bcachefs 底下是如何工作的。
场景:读取文件内容
下图展示了一个文件中连续的 4 段内容,即 4 个 extents,是如何在 bcachefs 中被索引起来的:
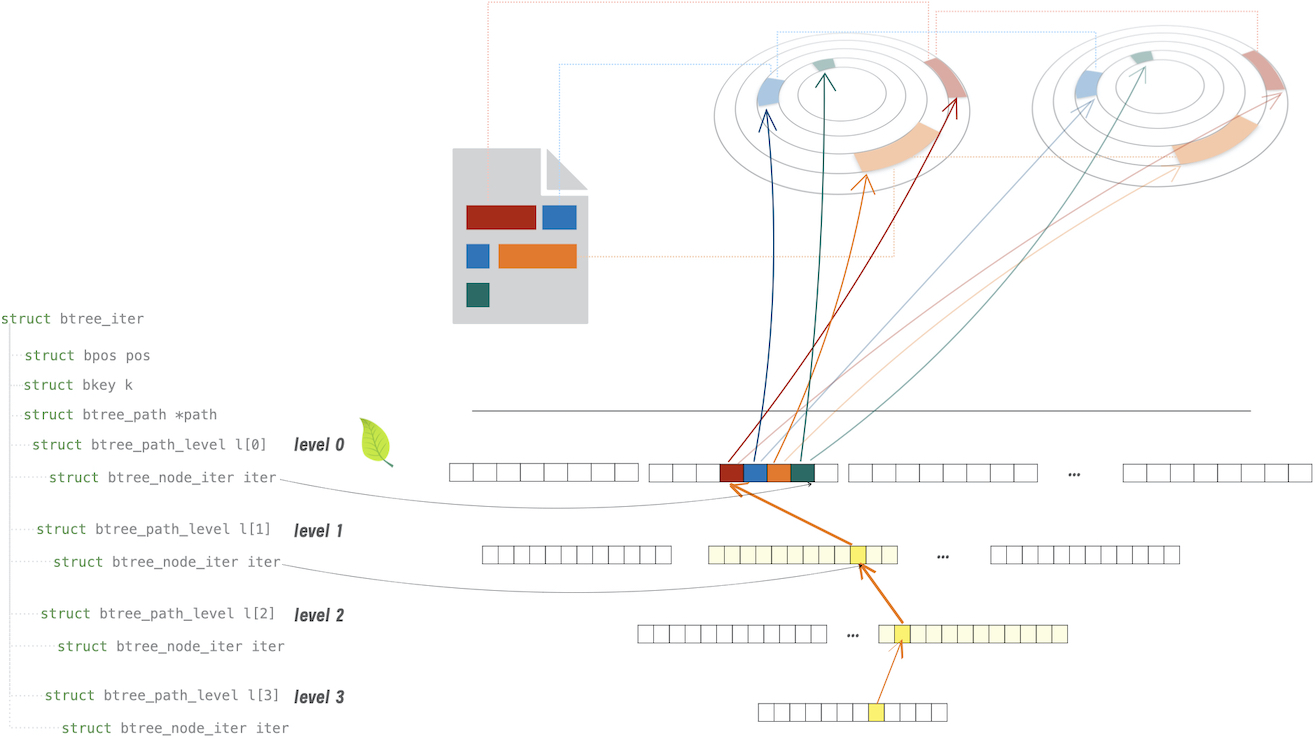
- extents 由
BTREE_ID_extents的 btree 来索引 btree_iter是 btree 的 iter,它包含了一个btree_path,从而指出了从 btree 根节点到叶子节点的路径。- 在叶子节点, 其 bkey 和 value 对,其中 value 包含一个或多个
bch_extent_ptr,指向一个或多个磁盘上的 extents
- 在叶子节点, 其 bkey 和 value 对,其中 value 包含一个或多个
本文接下来部分,将展开描述对文件内容的读取。即从 VFS APIs 到“访问 extents”的 Block IO。
VFS API:read_iter()
// libbcachefs/fs.c
struct file_operations bch_file_operations = {
...
.read_iter = bch2_read_iter,
...
}
读取文件内容涉及的 VFS 接口 read_iter(),实现为 bch2_read_iter():
ssize_t bch2_read_iter(struct kiocb *iocb, struct iov_iter *iter) {
...
// 为了单刀直入相关代码,跳过常见的 Page Cache 路径,来到了 direct IO
if (iocb->ki_flags & IOCB_DIRECT) {
struct blk_plug plug;
...
blk_start_plug(&plug);
ret = bch2_direct_IO_read(iocb, iter);
blk_finish_plug(&plug)
...
int bch2_direct_IO_read(struct kiocb *req, struct iov_iter *iter) {
struct file *file = req->ki_filp;
struct bch_inode_info *inode = file_bch_inode(file);
struct bio *bio;
loff_t offset = req->ki_pos;
size_t shorten;
ssize_t ret;
// 根据从 offset 开始,文件还有多少内容
// 提及 iter 中有多少空间存读出内容
// 算出读多长的内容
ret = min_t(loff_t, iter->count,
max_t(loff_t, 0,
i_size_read(&inode->v) /* 读取 struct inode::i_size */ - offset));
shorten = iter->count - round_up(ret, block_bytes(c) /* 磁盘的 block size */);
iter->count -= shorten;
// ↑↑ 代数化简:iter->count == round_up(ret, block_bytes(c)
// 即本次读文件,需要访问的数据量
bio = bio_alloc_bioset(...);
...
goto start;
while (iter->count) {
...
start:
...
bio->bi_iter.bi_sector = offset >> 9;
...
// 下面函数,会调用到 __iov_iter_get_pages_alloc() 函数,会减少 iter->count
ret = bio_iov_iter_get_pages(bio, iter);
...
offset += bio->bi_iter.bi_size;
...
bch2_read(c, rbio_init(bio, opts), inode_inum(inode));
}
iter->count += shorten;
...
沿着调用栈,关注到 bch2_read()。后者进一步调用到了 __bch2_read()
读文件实现:__bch2_read()
void __bch2_read(struct bch_fs *c, struct bch_read_bio *rbio,
struct bvec_iter bvec_iter, subvol_inum inum,
..., unsigned flags) {
struct btree_trans trans; // 本文暂时忽略 btree_trans
struct btree_iter iter;
struct bkey_s_c k;
...
while (1) {
...
// 将 POS(...) 设置到 btree_iter::k(注:其类型为 bkey)
bch2_btree_iter_set_pos(&iter, POS(inum.inum, bvec_iter.bi_sector));
// 定位 k
struct bkey_s_c k = bch2_btree_iter_peek_slot(&iter);
宏 POS(...) 相当于 struct bpos 的构造函数,其中:
bpos::inode被赋值为inum.inumbpos::offset被赋值为bvec_iter.bi_sectorbpos::snapshot被赋值为 0
可见,在本场景中,文件偏移被编码到 bpos::offset。随后以此为 bkey,来搜索 BTREE_ID_extents 的 btree,找到对应的 value:
- value 即为指向 extent 的指针
- 如下图所示
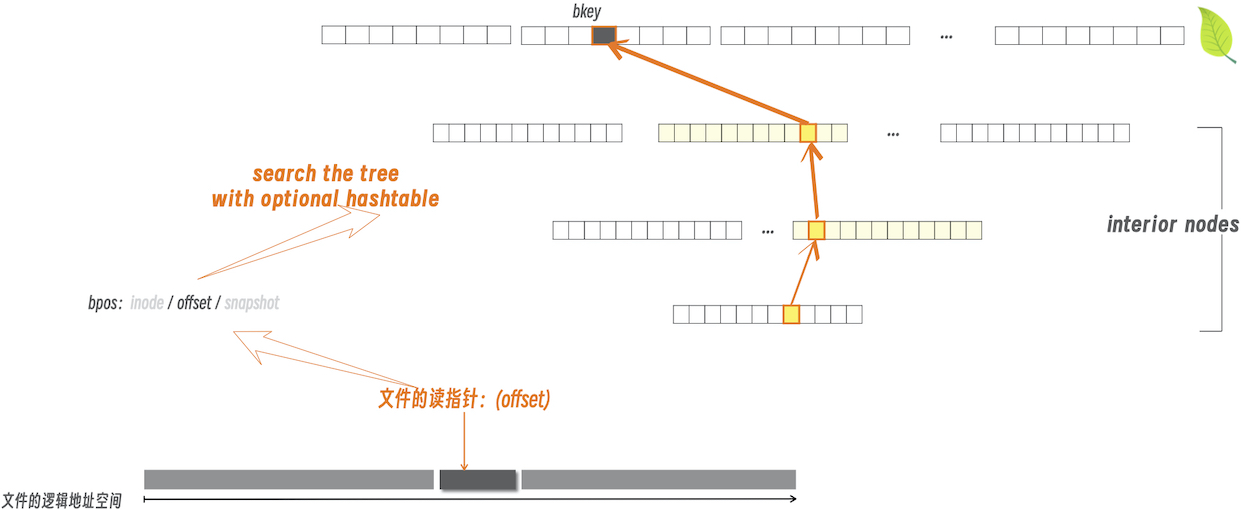
找到 k 之后,准备相应的 block IO,需要起始偏移,以及长度。
其中,文件内 offset,即 logical offset,映射到 Block IO 的起始偏移,可以类比虚拟内存中的“地址映射”:
logical offset 可类比为 logical address(或叫 virtual address)
- 如同 virtual address 在映射中,分为虚拟页映射到物理页,随后加上页内偏移
- logical offset 可分为 “extent 起始地址的映射”,随后加上 “extent 内偏移”
- 如同页表是为了虚拟页到物理页的映射,
BTREE_ID_extents的 btree 是为了将一个 logical offset,映射到某个 extent 上去- (严格地说,也可能映射到多个互为副本的 extents 上)
- 这个映射是怎么发生的呢? 首先是在
bch2_btree_iter_peek_slot(),返回一个struct bkey_s_c k,它就好比是一个“页表项” - 对“页表项”的解析,是发生在
__bch2_read_extent()函数中(参见下面的代码摘要) - 解析的结果,由
struct extent_ptr_decoded表示。其中extent_ptr_decoded::ptr::offset指向了 extent 在磁盘的起始偏移,以 sector 计
- extent 内偏移的计算,即下面代码摘要中的
offset_into_extent变量- 特别指出的是
bkey_start_offset(...)这个函数,它是k->p.offset - k->size - 因为 extent 的
bkey::p::offset是取 “EOE” (End of extent)
- 特别指出的是
...
// ----logical offset: (offset into file)----·
// |
// extent's logical |
// start offset |
// | |
// V V
// --------------------------------------------
// | extent |
// --------------------------------------------
unsigned offset_into_extent = iter.pos.offset - bkey_start_offset(k.k)
unsigned sectors = k.k->size - offset_into_extent; // 本 extent 内需要读的部分
...
unsigned bytes = min(sectors, bvec_iter_sectors(bvec_iter)) << 9;
swap(bvec_iter.bi_size, bytes);
if (bvec_iter.bi_size == bytes)
flags |= BCH_READ_LAST_FRAGMENT;
__bch2_read_extent(&trans, rbio, bvec_iter, iter.pos, BTREE_ID_extents,
k, offset_into_extent, ...);
...
// 一次对文件的读,例如通过 read(fd, buf, size)
// 可能涉及对多个 extents 的访问
// 当最后一个 extent 被访问后,设置 flags BCH_READ_LAST_FRAGMENT
// 此处:检测到此 flag,则退出
if (flags & BCH_READ_LAST_FRAGMENT)
break;
swap(bvec_iter.bi_size, bytes);
bio_advance_iter(&rbio->bio, &bvec_iter, bytes);
...
} // while(1)
...
} // __bch2_read()
我们可以看到,关键的“页表查询”是发生在 bch2_btree_iter_peek_slot() 函数中。
bch2_btree_iter_peek_slot(struct btree_iter *iter) - 类比“页表查询”
如前述代码可知,iter.pos 已经被设置成了 logical offset,随后:
// 对 BTREE_ITER_IS_EXTENTS,对 iter.pos 再前进一步
struct bpos search_key = btree_iter_search_key(iter);
// 这是因为,如下的情形,刚好指向 extent 在 btree 中的 “key”
// 但这个“key” 位置,因为是 start-of-extent + size-of-extent
// ----iter.pos(offset into file)----· 其实不属于 extent
// |
// V
// ---------------------------
// | extent |
// ---------------------------
iter->path = bch2_btree_path_set_pos(trans, iter->path, search_key ...);
至此,出现了新数据结构 btree_path:
它代表了从树根到叶子结点的路径
它的 ownership 属于
btree_trans- 在一个 transaction 中的,用过的 path 被缓存起来
- 需要 path 时,用过的 path 会被捡起来复用
它被
btree_iter::path所引用
关于
bch2_btree_iter_peek_slot()的更多细节,参见附录 5。
...iter_peek_slot()/bch2_btree_path_set_pos()
如前述,path 是“循环利用”的,它之前指向的叶子结点,并非 search_key 所对应的叶子结点。
于是需要向树根方向回溯,直到找到共同的“父结点”,这个过程发生在函数 btree_path_up_util_good_node(...):
- 通过比较
search_key和b->data->min_key和b->data->max_key,判断search_key是否在struct btree *b名下的叶子结点中。
下图展示的例子中,假设“用过的 path“,它先前指示的路径为 “A -> B -> C -> D -> {extent}”;而本次需要读取的数据,其路径为 “A -> B’ -> M -> N -> {another-extent}”
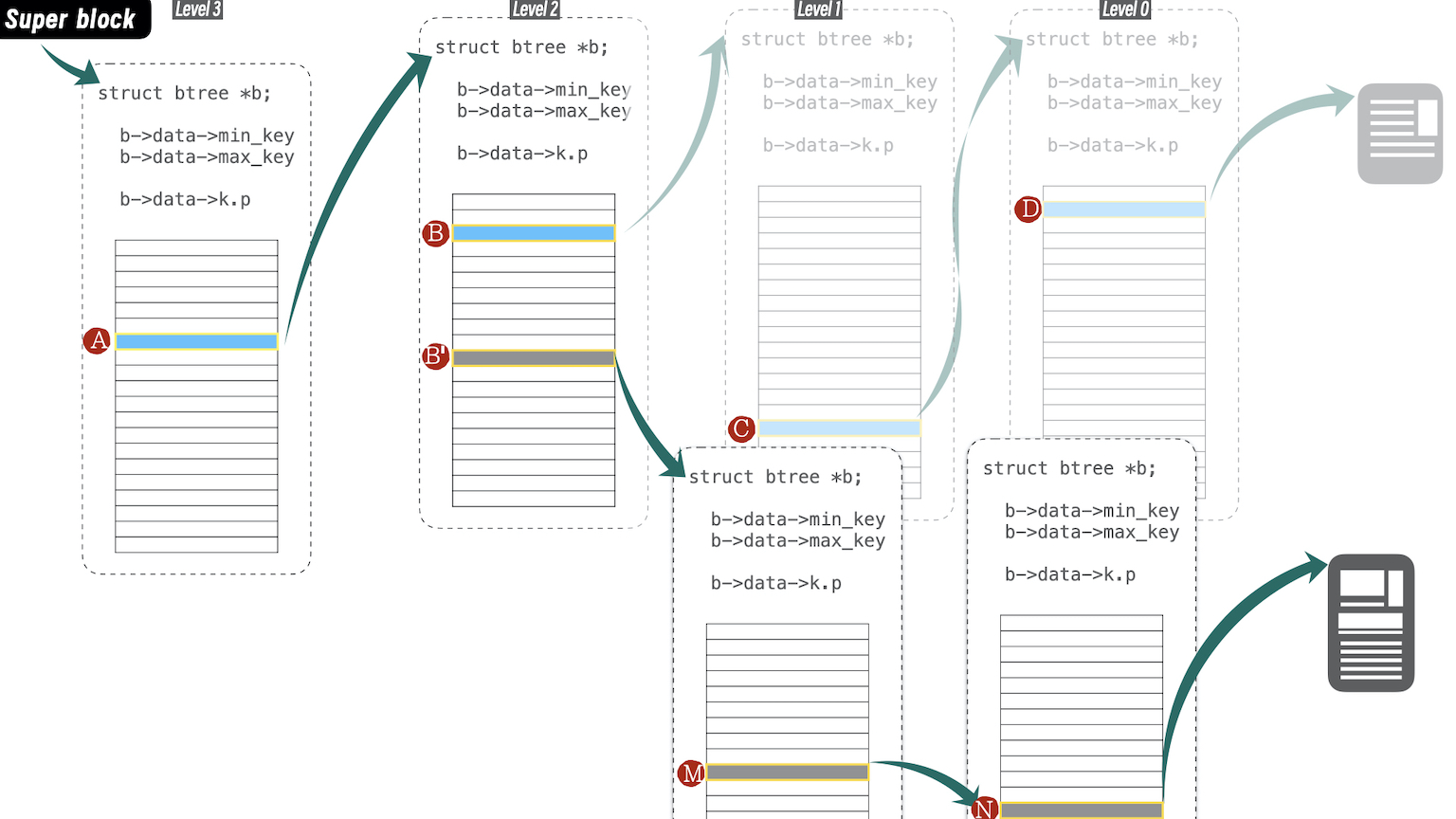
图中示例,借助下表,来理解 bch2_btree_path_set_pos() 函数逻辑:
- 表:阶段 1,指经
btree_path_up_until_good_node()函数 - 表:阶段 2,指
bch2_btree_path_set_pos()中余下的逻辑
| 变量 | 变量类型 | 阶段 1 | 阶段 2 |
|---|---|---|---|
btree_path::level | 3-bit | 0 (未变) | 同左 |
| level 临时变量 | unsigned | 被赋值为 2 | 未变 |
btree::uptodate | 2-bit | (未变) 假设前次值为 BTREE_ITER_UPTODATE | 变为BTREE_ITER_NEED_TRAVERSE |
btree_path::l[0]::b | btree | 变为 ERR_PTR(-BCH_ERR_no_btree_node_up) | 未变 |
btree_path::l[0]::iter | btree_node_iter | 未变(图示:D) | 同左 |
btree_path::l[1]::b | btree | 变为 ERR_PTR(-BCH_ERR_no_btree_node_up) | 未变 |
btree_path::l[1]::iter | btree_node_iter | 未变(图示:C) | 同左 |
btree_path::l[2]::b | btree | 变为 ERR_PTR(-BCH_ERR_no_btree_node_up) | 未变 |
btree_path::l[2]::iter | btree_node_iter | 未变(图示:B) | 变为图示 B’,这是通过函数 btree_path_advance_to_pos() 和/或 bch2_btree_node_iter_init() 完成的 |
btree_path::l[3]::b | btree | 未变 | 未变 |
btree_path::l[3]::iter | btree_node_iter | 未变(图示:A) | 未变 |
关于
bch2_btree_path_set_pos()更多细节,参见附录 6。
...iter_peek_slot()/bch2_btree_path_traverse()
实际函数为 bch2_btree_path_traverse_one(),其主要的逻辑如下:
unsigned depth_want = path->level;
...
// 再次调用了下述函数,留意这次 path->level 得到了更新
path->level = btree_path_up_until_good_node(trans, path, 0);
while (path->level > depth_want) { // 代入例子,path->level 为 2, depth_want 为 0
ret = btree_path_node(path, path->level) ?
btree_path_down(trans, path, ...) : ...;
if (ret) { /* 出错处理 */ }
}
path->uptodate = BTREE_ITER_UPTODATE;
...
代入例子进行理解,当前路径为 “A -> B’” ,在 while(...) 循环中,经历两次次迭代,即两次 btree_path_down(...),展开新路径 “A -> B’ -> M -> N” 中的 “M 和 N” 节点。
随后通过 __bch2_read_extent() 来取得 “N” 所指向的 bkey_packed 的 value 所指向的数据。
更具体的,接续前述表格,btree_path_down(...) 会:
- 赋值
btree_path::l[2]::b,即取得 “B’” 所指向的节点;并初始化btree_path::l[1]::iter指向 “M”btree_path::level变为 1
- 赋值
btree_path::l[1]::b,即取得 “M ” 所指向的节点;并初始化btree_path::l[0]::iter指向 “N”btree_path::level变为 0
path_traverse_one()/btree_path_down()
该函数的主要逻辑,如下述伪代码所示:
int btree_path_down(struct btree_trans *trans, struct btree_path *path, ...) {
struct bkey_buf tmp; /* bch2_bkey_buf_init(&tmp); */
struct btree_path_level *l = path->l + path->level;
...
bch2_bkey_buf_unpack(&tmp, trans->c /* struct bch_fs* */, l->b,
bch2_btree_node_iter_peek(&l->iter, l->b) /* struct bkey_packed* */ );
...
struct btree *b = bch2_btree_node_get(trans, path, tmp.k,
path->level - 1 /* 点题:“path_down” */, ...);
...
path->level = level;
bch2_btree_path_level_init(trans, path, b);
...
}
重点关注两个函数 bch2_btree_node_get(...) 以及 bch2_btree_path_level_init(...)。
前者用于取得节点,后者则初始化 btree_path::l[?]::iter 的指向。
bch2_btree_node_get(...)
类比虚拟内存中,TLB 是对页表查询的缓冲。bch2_btree_node_get(...) 函数取得节点的过程中,也有一系列的缓冲机制。
缓冲机制始于 tmp.k —— 其 value 中的 ::mem_ptr 域:
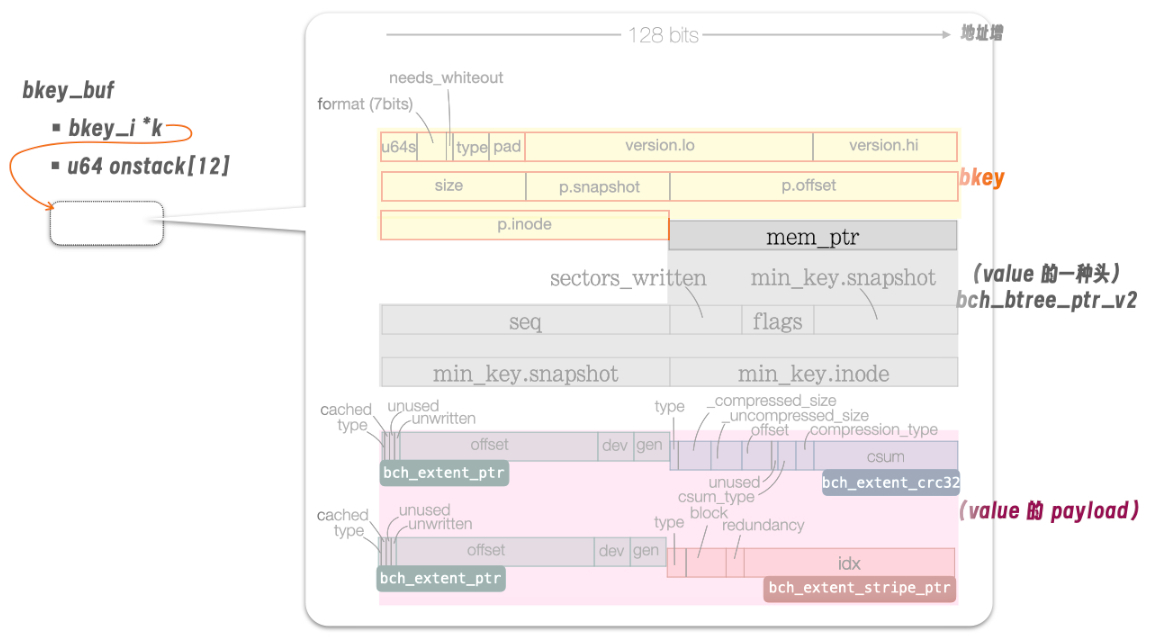
struct btree *b = btree_node_mem_ptr(k);
if (b->hash_val == btree_ptr_hash_val(k))
// hit !
当上述路径未命中时,进入 __bch2_btree_node_get(...) 函数,通过 btree_cache_find(btree_cache *bc, k) 来查询超级块代码(super.c)所建立的、文件系统中的缓冲(struct bch_fs::btree_cache)。
如果还未命中,则进入 bch2_btree_node_fill(..) 函数,进一步调用到 bch2_btree_node_read() 老老实实去取。
关于
bch2_btree_node_get()更多细节,参见附录 8。
bch2_btree_path_level_init(trans, path, b)
限于篇幅,这里只提一下 bch2_btree_node_iter_init() 这个函数,即初始化 btree_node_iter 指向:
如本系列第一篇所述,节点加载在内存,再经历一些文件系统操作,最多会有 3 个 bsets。
换言之,一个
bkey_packed,可能出现在 3 个 bsets,需要通过排序来确认”覆盖关系“。所以,
struct btree_node_iter会指向多个bkey_packed。- 下图展示了指向两个 bset 中的两个
bkey_packed的情形:
- 下图展示了指向两个 bset 中的两个
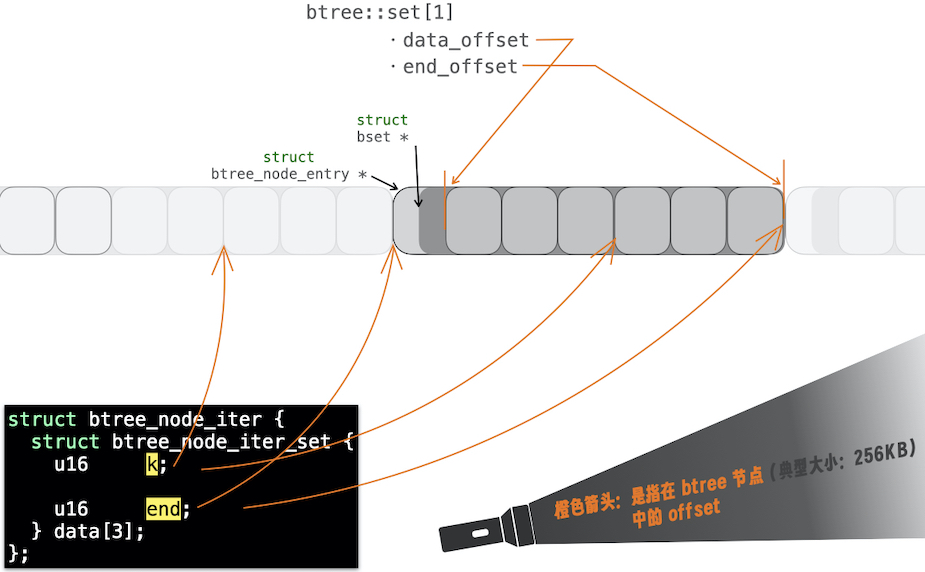
再回到 bch2_btree_node_iter_init():
void bch2_btree_node_iter_init(struct btree_node_iter *iter,
struct btree *b, struct bpos *search) {
...
memset(iter, 0, sizeof(*iter));
...
struct bkey_packed *k[MAX_BSETS];
for (i = 0; i < b->nsets; i++) {
// 二叉树查找,定位到一个所谓的 cacheline
k[i] = bch2_bset_search_linear(b, b->set + i, search, ...);
prefetch_four_cachelines(k[i]);
}
struct btree_node_iter_set *pos = iter->data;
for (i = 0; i < b->nsets; i++) {
// 通过 end_offset,换算成指针
// Note:实际上,指针指向本 bset 的结尾
// 参见:set_btree_bset_end() 函数
struct bkey_packed *end = btree_bkey_last(b, b->set + i);
// 在 cacheline 中定位出 bkey_packed
k[i] = bch2_bset_search_linear(..., search, ..., k[i]);
if (k[i] != end)
*pos++ = (struct btree_node_iter_set) {
__btree_node_key_to_offset(b, k[i]),
__btree_node_key_to_offset(b, end)
};
}
bch2_btree_node_iter_sort(iter, b);
}
留意函数 bch2_btree_node_iter_sort(),指向多个 bkey_packed 时,它通过排序来决定覆盖关系:
排序规则参见函数
bkey_iter_cmp排序结果体现在
btree_node_iter::data中,即data[0]匹配度最高,覆盖其余。
...iter_peek_slot()/bch2_btree_iter_peek_upto()
聚焦在本文示例场景,并忽略出错检查逻辑,bch2_btree_iter_peek_slot() 函数的“终点站”为 bch2_btree_iter_peek_upto()
走到此处,btree_path 路径上的各 level 应该已经初始化到位。那么,bch2_btree_iter_peek_upto() 做了什么呢?
它的主要逻辑包括了__bch2_btree_iter_peek(...) 以及收尾逻辑。在本文场景中,它似乎没有特别逻辑值得一提,此处不做进一步展开。
关于
bch2_btree_node_iter_init()更多细节,参见附录 9。
__bch2_read_extent() - 实际文件内容的读取
int __bch2_read_extent(... struct bch_read_bio *orig,
... struct bvec_iter iter,
... struct bkey_s_c k,
... unsigned offset_into_extent,
...) {
if (bkey_extent_is_inline_data(k.k)) {
// value 直接是 data,而不是一个指向 data 的“指针”
// 拷贝到 iter 下
goto out_read_done;
}
struct extent_ptr_decoded pick;
// 这个函数其实仅仅是从 k 中解析出 bch_extent_ptr
int pick_ret = bch2_bkey_pick_read_device(..., k, &pick);
pick.ptr.offset += pick.crc.offset /* 推测起来:extent 开头有个 crc */
+ offset_into_extent;
orig->bio.bi_iter = iter;
orig->bio.bi_iter.bi_sector = pick.ptr.offset;
// 本次 IO 的 size 为 bvec_iter_sectors(iter);
submit_bio(&orig->bio);
...
}
附录:相关资料
bcachefs 源代码:
# bcachefs 命令行工具,包含一个移植到用户态的 bcachefs 库
# 代码阅读推荐使用本仓库
git clone https://evilpiepirate.org/git/bcachefs-tools.git
# 包含 bcachefs 的整个内核源代码,体积较大
git clone https://evilpiepirate.org/git/bcachefs.git
最后,本文撰写时的代码阅读笔记如下,以进一步补充细节:
- bcachefs 的 SIX 锁机制的实现
- 独文件入口,
bch2_read()函数 - 解析
bch_btree_ptr_v2,即解析各个bch_extent_entry - bcachefs 内建的缓冲机制:
btree_cache和btree_key_cache bch2_btree_iter_peek_slot()- 以及包含的
bch2_btree_iter_peek_upto() ...iter_peek_slot()调用到的__bch2_btree_iter_peek()
- 以及包含的
bch2_btree_path_set_pos()- 跟在
...path_set_pos()之后的bch2_btree_path_traverse() - 取节点函数
bch2_btree_node_get() bch2_btree_node_iter_init
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
