

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
文件系统简介:bcachefs(一)
by Chen Jie of TinyLab.org 2023/05/09
前言
文件系统是建立在 block 层之上的,VFS 接口的一个实现。而文件系统中,最近的潮流莫过于由 ZFS 所引发的 COW(Copy-On-Write)的实现了,例如:
- Linux 的 Btrfs
- DragonFly BSD 的 HAMMER2
- Apple 的 APFS
本文要介绍的 bcachefs 也是一种基于 COW 的文件系统,作者 Kent Overstreet,也是 bcache 的创立者。
bcache 基于较快的 SSD 介质,在 Linux block 层提供了一种 cache 机制。作者认为实现 bcache 中引入的 B+ 树等结构,同样可以实现一个 COW 的文件系统,于是有了 bcachefs。
bcachefs 补丁,LWN 这篇文章 进行了简介:
Core-kernel changes:引入了 SIX lock 机制。即区别于“读者共享,写者互斥”的读者写者锁,要求写者首先获得一个 Intent lock,Intent lock 与读者(Shared lock)不互斥,但相互之间互斥。随后再升级成 eXclusive lock。
Core-kernel changes:引入一个闭包的机制(closure)
以上两个变更,均被 bcachefs 的代码用到。
至于 bcachefs 文件系统本身的设计特点,本文将作简单展开。
一些 bcachefs 的动态以及背景知识参考:
11/04 2021, bcachefs status update - current and future work
02/22 2023,[LSF/MM/BPF TOPIC] bcachefs](https://lore.kernel.org/linux-bcachefs/Y%2FZxFwCasnmPLUP6@moria.home.lan/),将在 05/08 - 05/10 的 Linux Storage Filesystem / MM / BPF 峰会上进行介绍
bcachefs 的 git 仓库有两个。
bcachefs-tools 是移植到用户态的 bcachefs 库,以及对应命令行工具,它比较小,但包含了 bcachefs 文件系统逻辑,建议代码阅读首选 clone 这个:
git clone https://evilpiepirate.org/git/bcachefs-tools.git
bcachefs 是带上 bcachefs 的内核代码,比较大:
git clone https://evilpiepirate.org/git/bcachefs.git
bcachefs:数据结构
磁盘上的数据结构
bcachefs 磁盘上主要的数据结构有:
- superblock
- journal,bcachefs 将日志文件系统与 COW 机制做了结合
- btree
| 数据结构 | 相关结构体 | 说明 |
|---|---|---|
| super block | bch_sb | 包含: 1. location of journal 2. list of devces 3. other metadata in order to start a file system prior to reading the journal/btree roots 参见: bcachefs_format.h |
bch_sb_layout | 用于定位 backup super blocks,并重复存于每个 super block 中。 | |
| 在一次 clean shutdown 中,将 btree roots 和 current journal sequence number 存在 super block 中。 | ||
| journal | 按序记录对 btree 的更新 其中,Updates to interior nodes still happen synchronously and without the journal(for simplicity),参见 journal.h | |
| journal 由一组 keys 组成。Replay 就是遍历 open journal entries 中 所有的 keys,并重新插入到 btrees 中 | ||
jset jset_entry | 代表 a journal entry,它有一个 unique sequence number, 且是单调增加的 | |
| journal header 同时包含了一些逻辑上应该放在 super block 的东东。 因它们更新太频繁,所以挪到了 journal header 中。 (未来,superblock 将仅包含定位 main journal 的信息) | ||
| btree | bset btree_node btree_node_entry | btree 是最主要的结构体,用于存取元数据,其类型有: - BTREE_ID_extents、BTREE_ID_inodes- BTREE_ID_dirents、BTREE_ID_xattrs- BTREE_ID_alloc、BTREE_ID_quotas- BTREE_ID_stripes、BTREE_ID_reflink- BTREE_ID_subvolumes、BTREE_ID_snapshots- BTREE_ID_lru、BTREE_ID_freespace- BTREE_ID_need_discard、BTREE_ID_backpointers - BTREE_ID_bucket_gens |
| btree 节点很大,例如 256KB,且是 log structured 这个大概是 bcachefs 特点之一,接下来将重点关注 btree |
btree:磁盘上长啥样?
下图示意了 btree 在磁盘上的存储,即它们之间的联系:
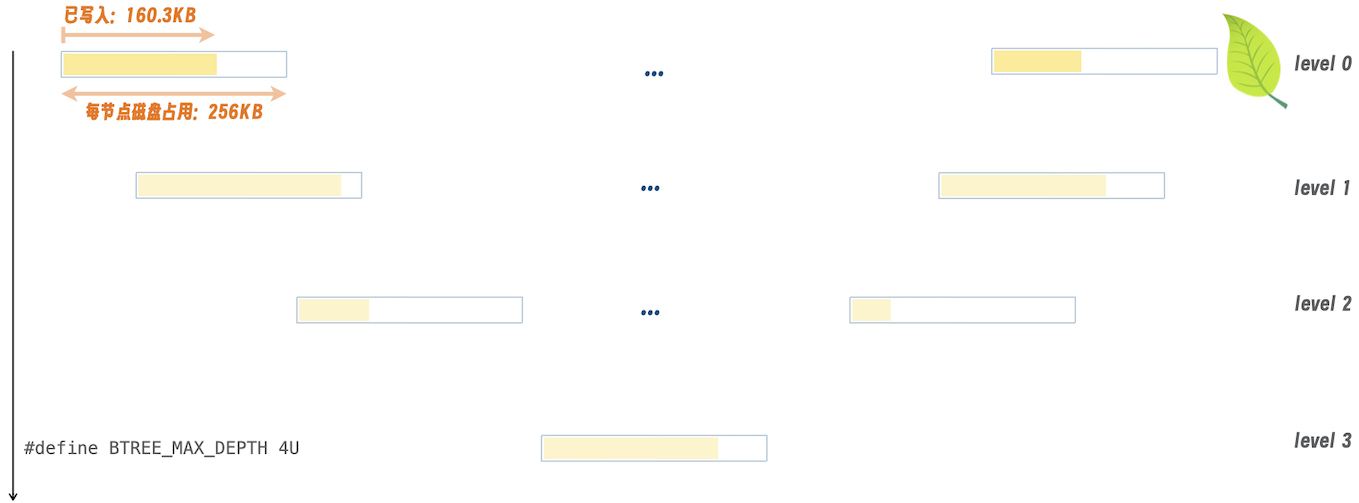
其中,对于每一个节点,会固定分配 256KB (bch_opts::btree_node_size)连续的磁盘空间。该空间分成俩部分:
- 已写入磁盘部分(written)
- 剩余未使用的空间
对于写入磁盘的部分,它是由一个 btree_node 打头,尾随若干个 btree_node_entry。
struct btree_node { | struct btree_node_entry {
struct bch_sum csum; | struct bch_csum csum;
__le64 magic; |
__le64 flags; |
|
struct bpos min_key; |
struct bpos max_key; |
|
/* NOT USED ANYTMORE */ |
struct bch_extent_ptr _ptr; |
|
struct bkey_format format; |
|
union { | union {
struct bset keys; | struct bset keys;
struct { | struct {
__u8 pad[22]; | __u8 pad[22];
__le16 u64s; | __le16 u64s;
__u64 _data[0]; | __u64 _data[0];
}; | };
}; | };
} __packed __aligned(8); | } __packed __aligned(8);
首先看到 [ btree_node::min_key, btree_node::max_key ] 指出了本节点所涵盖的范围。
- 这个逻辑上真正作用叫做 “key” 的东西,它的数据结构是
bpos:
struct bpos { __u64 inode; __u64 offset; __u32 snapshot; }
在 bpos 上,包裹更多的成员,就成了 bkey:
struct bkey { __u8 u64s; __u8 format:7, needs_whiteout:1;
__u8 type __u8 pad[1]; struct bversion version;
__u32 size; struct bpos p;
// ^^^^^^^^^^^^^
} __packed __aligned(8);
几个值得一提的域:
bkey::u64s,是指包含 key 和 value 在内的尺寸,以 u64(8 Bytes) 为单位计value 通常是个指针,它指向的 extent 的尺寸,以 sector(512 Bytes)为单位计,存在
bkey::size- 另,存储时,value 是紧跟在 key 之后的
接下来,bset 它是一组 bkey 的集合,或者确切地说:
本 btree 节点上,同一趟写入到磁盘的
bkey集合后续写入磁盘的
bkey在新的bset中同一个
bkey被覆写,意味着在后续的bset有“同名” bkey,value 不同“同名”,即指 bpos 相同
这就是所谓的 log structured。
同一个
bkey被删除,意味着在后续的bset有“同名” bkey,它是一个 whiteout。
下图展示了 bset:
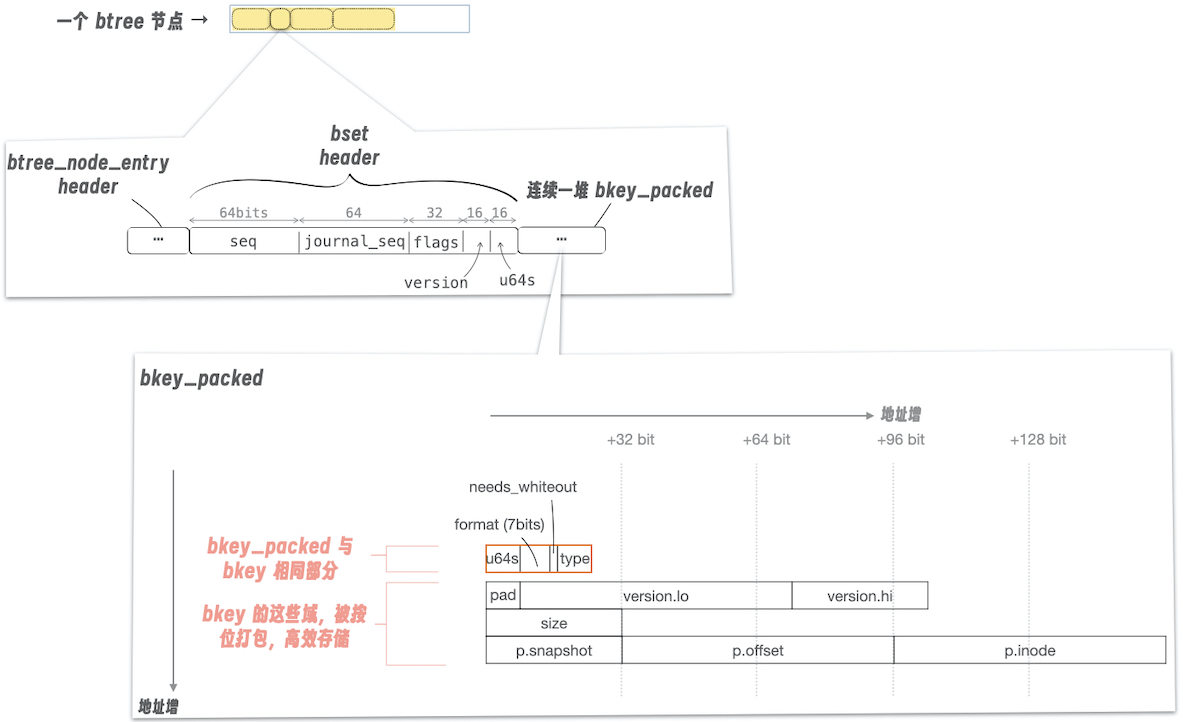
它前面套了一个
btree_node/btree_node_entry它自己的头结构,有一个
bset::u64s描述了本 bset 中,全部 payload 长度,以 u64 为单位计。随后,是一组
bkey_packed,图示中:橙色框出部,
bkey_packed和bkey是相同的。bkey_packed对bkey剩余部分,进行了“位打包”,存储效率更高一些对“位打包后”的格式,借助
bkey_format来解读。参见BKEY_FORMAT_CURRENTinbcachefs_format.h
认识 bkey
如前述,一组 bkey 首先会被打包成 bkey_packed,随后添加一个 bset 的头,即放在 bset 结构中,再存磁盘。
对应 value,是跟在 key 之后,一起序列化打包的:
value 的结构体是
bch_val:struct bch_val { __u64 __nothing[0] };value 除内容以外,没有任何的头了。定义这个结构体,仅仅是代码 meaningful 的需要。
我们假设打开了一个文件,文件内容 —— 即开始和结束的 bpos 所囊括的区间,由一个 BTREE_ID_extents 类型 btree 所定位
假设这个 btree 目前只有两层,顶层是 level 1 节点
level 1 是一个中间节点(interior node),它某个 bkey 的 value 指向了一个 level 0 的节点(叶子节点)
换言之,指向的还是 btree 节点。其 bkey 类型为
BKEY_TYPE_btree(参见btree_types.h,通过宏组合名称,定义的 bkey 类型)下表展示了 value 序列化后的结构
| 序号 | 内容 | 说明 |
|---|---|---|
| 0 | bch_btree_ptr_v2 | 相当于一个 header,其中bch_btree_ptr_v2::sectors_written,留意和 bkey::size 区别。前者指向叶子节点的已用空间;后者是总空间 |
| 1 | bch_extent_ptr | 其中 bch_extent_ptr::offset 指向了叶子节点的磁盘起始位置,以 sectors 计 |
| 2 | bch_extent_ptr | 这是指向另一磁盘上副本的指针 |
| 3 | bch_extent_ptr | 同上 |
| 4 | bch_extent_ptr | 同上,总计最多有四个副本 |
我们再假设,上述文件内容被一个叶子节点中的某个 bkey 的 value 指向
换言之,指向的是一块 extent,而非 btree 节点。其 bkey 类型为
BKEY_TYPE_extents下表展示了 value 序列化后的结构(参见
bch_extent_entry)
| 内容 | 说明 |
|---|---|
bch_extent_ptr | 指向 extent |
bch_extent_crc32 | crc 和 stripe 不在本文展开 |
bch_extent_crc64 | |
bch_extent_crc128 | |
bch_extent_stripe_ptr |
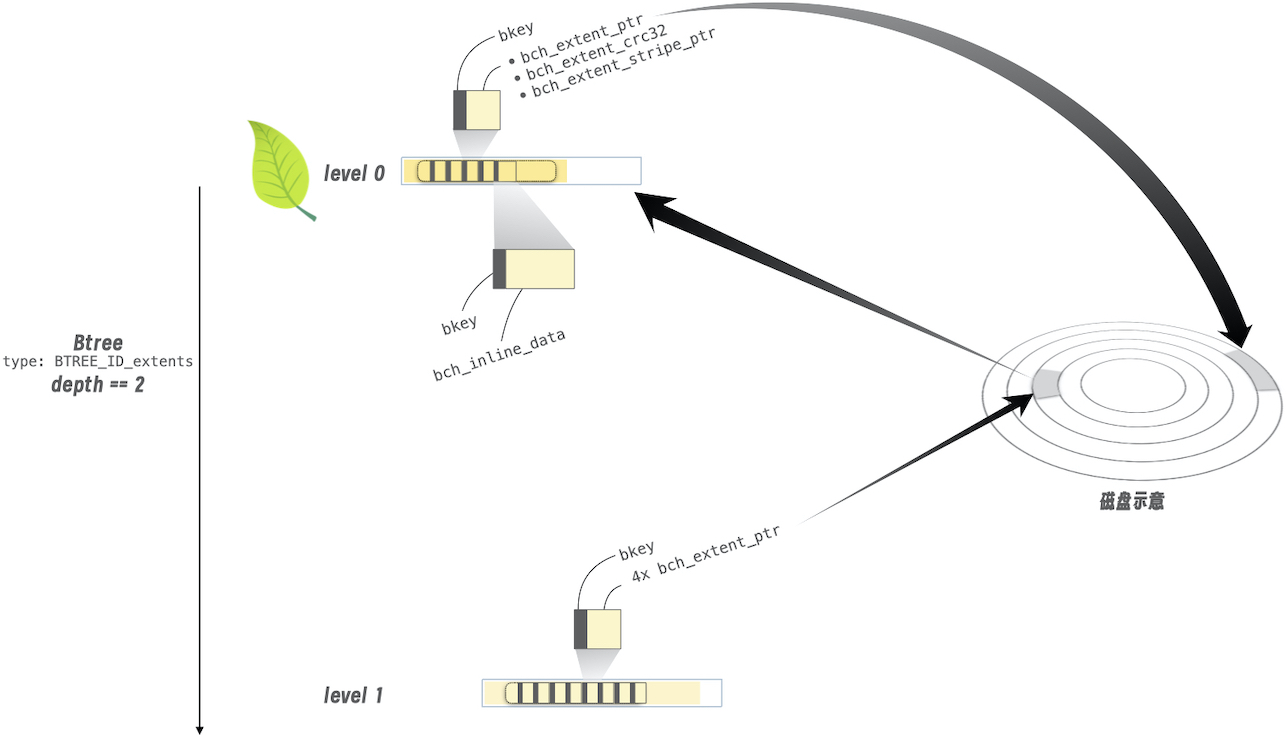
下图展示了上述两种 bkey:
level 1 中的一个 bset 中的一个 bkey,指向了磁盘某个 256KB 块
- 它就是 level 0 的内容序列化
level 0 中的一个 bset 中的一个 bkey,指向了磁盘某个块,内容即上述例中的文件内容
- 图中还展示了另一种形式,即当文件内容很小时,可以直接变成
bch_inline_data嵌在 bkey 中。
- 图中还展示了另一种形式,即当文件内容很小时,可以直接变成
bkey 在编程技巧中的变种
如下表,这些结构体,仅仅是为了对同一块内存作不同层次的解读。
| 变种 | 说明 |
|---|---|
bkey_i | value inline 在 bkey 中的形式。 如前述,无论磁盘还是内存布局,value 是跟在 bkey 之后的。 |
bkey_s | bkey with split value |
bkey_s_c | bkey with split value,conststruct bkey_s_c { const struct bkey *k; const struct bch_val *v; } |
bkey_s_xxx | 例如,bkey_s_btree_ptr_v2,它是在 bkey.h 中,通过宏来一并定义的相对于 bkey_s::v,bkey_s_btree_ptr::v 现在直接是 struct bch_btree_ptr_v2 * 类型而非原来笼统的 struct bch_val * |
bkey_s_c_xxx | const 版本 |
btree 节点:序列化存盘与读入并反序列化
背景:btree 结构体简介
首先介绍 btree 结构体,它代表了一个在内存的 btree 节点。
本文讨论中会涉及的域:
btree::nsets:在内存中,当前有多少 bsets内存中的最多有
MAX_BSETS个 bsetsbtree::set[0],已写入磁盘全部 bsets 合并在内存的一个 bsetbtree::set[1],未写入磁盘的 bkeys 的 bsetbtree::set[2],如果btree::set[1]过大(>4KB,参见bch2_btree_node_prep_for_write()),则另建一个
btree::set:类型为bset_tree[MAX_BSETS]struct bset_tree { ... u16 data_offset; ... u16 end_offset };data_offset和end_offset指出了一个 bset 在btree::data中的开始和结束偏移。
btree::data,虽然其类型为btree_node,但实际上就是一整个 256KB btree 节点。- 其布局如下:
***代表未写入磁盘部分
- 其布局如下:
<---------- 256KB ----------->
------------------------------
||||||||||||**** ***
------------------------------
^ ^
| b->whiteout_u64s
b->written
btree::whiteout_u64s:未写入磁盘的 whiteouts 计数,单位是 u64删除已经写入磁盘的 bkeys,只能通过 whiteout 方式
“这些被 whiteout 掉 bkeys” 写入 “从
btree::data末尾起、反向生长的空间”它们逻辑上也是一个 bkeys 的 set
只是没有 bset 的头罢了
btree::written:已写入磁盘计数,单位是 sectorbtree::aux_data:类型为void *,二叉搜索树,每个 bset 一个对于 RO 类型(
BSET_RO_AUX_TREE)的 bset由已写入磁盘的一个或多个 bsets 合并而来
二叉树的“key”的定义,参见
bset.h(形似 floating point 格式的描述)二叉树定位到一个
BSET_CACHELINE(256 Bytes)随后再在
BSET_CACHELINE中进行线性搜索搜索过程参见:
bset_search_tree()
对于 RW 类型(
BSET_RW_AUX_TREE) 的 bset,即还未写入到磁盘的 bset二叉树的“key”,为
bpos搜索过程参见:
bset_search_write_set()(标准二叉树搜索)
btree::key,类型为bkey_i。即本 btree 节点的 key 和 value- (换言之,在父节点中的 key 和 value 的一个拷贝)
背景:一个 bpos 被 whiteout
// btree_update_interior.h
static inline void push_whiteout(struct bch_fs *c, struct btree *b,
struct bpos pos) {
// ^^^
// 依据 bpos 构造一个 bkey_packed,变量名叫 k
// k.type = KEY_TYPE_deleted;
// k.p = pos;
// k.needs_whiteout = true;
...
b->whiteout_u64s = k.u64s;
bkey_copy( ((u64 *)((void *)b->data + 256 * 1024)) - b->whiteout_u64s,
&k );
}
情景一:对 btree 节点更新,存入磁盘
对应代码位于btree_io.c,函数 __bch2_btree_node_write()。以下摘出部分逻辑,并进行大幅调整来便于说明:
void __bch2_btree_node_write(struct bch_fs *c, struct btree *b, unsigned flags) {
struct bset_tree *t;
struct sort_iter sort_iter;
unsigned bytes = !b->written ? sizeof(struct btree_node)
: sizeof(struct btree_node_entry);
for (t = b->set; t < b->set + b->nsets; t++) {
struct bset *i = (u64 *) b->data + 1 + t->data_offset;
if ((void *) i < (void *) b->data + (b->written * 512))
continue; // 已写入磁盘,跳过
bytes += le16_to_cpu(i->u64s) * sizeof(u64);
// bset 内的 bkey 本身是排序
// 几个 bset 的 bkey 统一排序,需通过 sort_iter 的移动
// 此处:先加入到 sort_iter 中
sort_iter_add(&sort_iter,
i->start, // 当前 bset 所指向的第一个 bkey
(u64 *) i->start + i->u64s);
}
// bch2_varint_decode may read up to 7 bytes past the end of the buffer:
bytes += 8
bch2_sort_whiteouts(c, b); // 对 “被 whiteout 掉 bkeys” 进行排序
sort_iter_add(&sort_iter,
(u64 *)((void *) b->data + 256 * 1024) - b->whiteout_u64s,
(void *) b->data + 256 * 1024);
bytes += b->whiteout_u64s * sizeof(u64);
bytes = round_up(bytes, block_bytes(c) /* 磁盘的 block size */);
data = btree_bounce_alloc(..., bytes, ...);
至此,分配出了一个新的空间,用于处理待写入磁盘的内容。由于我们假设对节点追加更新,于是:
// 接续上文
struct btree_node_entry *bne = data;
struct bset *i = &bne->keys;
// 初始化 bset 头信息,例如:
// bne->keys = b->data->keys;
// i->journal_seq = cpu_to_le64(seq);
// i->u64s = 0;
// 通过 sort_iter 进行排序,并将排序结果写入到 i->start(实际上就是前述
// data 指向的新分配空间中)
// 排序中,使用了 sort_keys_cmp 这个函数来定义排序规则
unsigned u64s = bch2_sort_keys(i->start, &sort_iter, false);
i->u64s += u64s;
// 排序后,多个相同键值的 bkey 将被排序靠后的 bkey 合并
// 特别指出的是:deleted key 排序靠后
接下来,准备写入到磁盘:
// 续接上文
unsigned bytes_to_write = (void *) ((u64 *) i->start + i->u64s) - data;
unsigned sectors_to_write = round_up(bytes_to_write,
block_bytes(c) /* 磁盘的 block size */)
sectors_to_write /= 512;
struct bio *bio = bio_alloc_bioset(NULL,
buf_pages(data, sectors_to_write * 512),
REQ_OP_WRITE|REQ_META,
GFP_NIO, &c->btree_bio);
struct btree_write_bio *wbio = container_of(bio, struct btree_write_bio, wbio.bio);
// 在下面函数中,bio->bi_iter.bi_size = sectors_to_write * 512;
bch2_bio_map(bio, data, sectors_to_write * 512);
wbio->sector_offset = b->written;
bkey_copy(&wbio->key, bkey);
b->written += sectors_to_write;
if (wbio->key.k.type == KEY_TYPE_btree_ptr_v2)
bkey_i_to_btree_ptr_v2(&wbio->key)->v.sectors_written = cpu_to_le16(b->written);
INIT_WORK(&wbio->work, btree_write_submit);
queue_work(c->io_complete_wq, &wbio->work);
最后,提交到磁盘的发生在函数 btree_write_submit() 中:
void btree_write_submit(struct work_struct *work) {
struct btree_write_bio *wbio = container_of(work, struct btree_write_bio, work);
struct bch_extent_ptr *ptr;
bkey_copy(&tmp.k, &wbio->key); // 拷贝出一个 tmp 的 key
bkey_for_each_prt(bch2_bkey_ptrs(bkey_i_to_s(&tmp.k)), ptr)
ptr->offset += wbio->sector_offset;
//^^^^^^^^^^^
bch2_submit_wbio_replicas(&wbio->wbio, ..., &tmp.k, false);
}
最终,在 bch2_submit_wbio_replicas() 函数中,bio.bi_iter.bi_sector = ptr->offset。
至此,写磁盘的起点(bio.bi_iter.bi_sector),以及长度(bio.bi_iter.bi_size)都已配置好,调用submit_bio(),将写磁盘 IO 提交到 block 层。
情景二:从磁盘读入一个 btree 节点并反序列化
对应代码位于btree_io.c,函数 bch2_btree_node_read(),以下摘出部分逻辑,并进行大幅调整来便于说明:
void bch2_btree_node_read(struct bch_fs *c, struct btree *b, bool sync) {
struct extent_ptr_decoded pick;
// 对 b->key 的 value 进行解析,解析结果保存在类型为 struct extent_ptr_decoded
// 的变量中
// value 可能包含多个 struct bch_extent_ptr,对应不同磁盘上的副本
// 筛选出一个较佳的磁盘,随后访问该磁盘上的副本
int ret = bch2_bkey_pick_read_device(c, bkey_i_to_s_c(&b->key),
NULL, &pick);
接下来,准备读取磁盘:
// 续接上文
struct bio *bio = bio_alloc_bioset(NULL,
buf_pages(b->data, 256 * 1024),
REQ_OP_READ|REQ_SYNC|REQ_META,
GFP_NOIO,
&c->btree_io);
struct btree_read_bio *rb = container_of(bio, struct btree_read_bio, bio);
INIT_WORK(&rb->work, btree_node_read_work);
bio->bi_iter.bi_sector = pick.ptr.offset; // bch_extent_ptr::offset
bio->bi_end_io = btree_node_read_endio;
bch2_bio_map(bio, b->data, 256 * 1024); // bio->bi_iter.bi_size = 256 * 1024;
submit_bio(bio);
}
读磁盘 IO 被提交到 block 层。当 IO 完成后,btree_node_read_endio() 函数被调用:
void btree_node_read_endio(struct bio *bio) {
struct btree_read_bio *rb = container_of(bio, struct btree_read_bio, bio);
...
queue_work(c->io_complete_wq, &rb->work);
}
work 对应的函数 btree_node_read_work(),该函数调用了 bch2_btree_node_read_done() 对读取的内容进行反序列化:
int bch2_btree_node_read_done(struct bch_fs *c, struct bch_dev *ca, struct btree *b,
bool have_retry, bool *saw_error) {
// 参见 super.c:bch2_fs_alloc() 函数,关于 fill_iter 这个 mempool_t
// 分配的 iter 大小为 sizeof(struct sort_iter)
// + (256 * 1024 / block_bytes(c) + 1) * 2 * sizeof(struct sort_iter_set)
struct sort_iter *iter = mempool_alloc(&c->fill_iter, GFP_NOIO);
sort_iter_init(iter, b);
iter->size = (256 * 1024 / block_bytes(c) + 1) * 2;
// 即 bch_btree_ptr_v2::sectors_written
unsigned ptr_written = btree_ptr_sectors_written(&b->key);
b->written = 0;
while (b->written < ptr_written) {
struct bset *i;
unsigned sectors;
bool first = !b->written;
// 读取 bset
if (first) {
i = &b->data->keys;
sectors = /* 包括 btree_node 头、bset 头
* 以及 bset::u64s,向上对齐到磁盘的 block size */ ;
} else {
struct btree_node_entry *bne = (void *) b->data + b->written * 512;
i = &bne->keys;
sectors = /* 包括 btree_node 头、bset 头
* 以及 bset::u64s,向上对齐到磁盘的 block size */ ;
}
b->written += sectors;
sort_iter_add(iter, i->start, (u64 *) i->start + i->u64s);
}
至此,待反序列化的 bset 都已经纳入到了 sort_iter 中了,接下来:
// 续接上文
struct btree_node *sorted = btree_bounce_alloc(c, 256 * 1024, ...);
sorted->keys.u64s = 0;
// 将全部磁盘上读取的 bset,其 bkey 进行排序
// 留意,排序中,使用了 key_sort_fix_overlapping_cmp 这个函数来定义排序规则
// - 对于 key 值相同的,序列化中偏移大的,序号大
// - 实际上是写磁盘晚的,序号大,最终生效
//
// 并将排序结果存到 sorted->keys
b->nr = bch2_key_sort_fix_overlapping(c, &sorted->keys, iter);
unsigned u64s = le16_to_cpu(sorted->keys.u64s);
*sorted = *b->data;
sorted->keys.u64s = u64s;
// sorted 指向内存区域,成为 b->data 所指向
swap(sorted, b->data);
b->set[0].data_offset = (u64 *) i - 1 - (u64 *) b->data;
b->set[0].end_offset = (u64 *) i->start + i->u64s;
// 反序列化后,多个 bsets 合并成在内存中的一个 bset
b->nsets = 1;
// 在内存中,建立二叉搜索树
bch2_bset_build_aux_btree(b, &b->set[0], false);
}
小结
bcachefs 是 Linux 下,另一个 COW 文件系统。它基于 bcache 的 btree 实现演化而来。
bcachefs 的主要数据结构,其 btree 节点的更新序列化存盘,与读取反序列化场景,是本文简介的三个主要方面。
本系列的下一篇中,将从 VFS 出发, 以读取文件的一部分内容进行情景分析,展示在 bcachefs 上是怎样工作的。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
