

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
汇编实战:龙芯处理器之 memcpy 优化
by Chen Jie of TinyLab.org 2015/5/23
前言
@Falcon《Linux 汇编语言快速上手:4大架构一块学》一文中,华丽地拉了四大汇编语言。不过在大部分情形下,鲜有机会或者说动力,去用汇编写点啥 —— 对于程序员而言,遇上某个机缘,得以演练语言或技能,这便是快乐之一 —— 我在龙芯上恰好遇上这样一次经历,便在此分享,以窥汇编之世界。
龙芯处理器属于 MIPS 体系架构,故以下汇编为 MIPS 汇编。顺便说一句,现在绝大多数处理器,其实质是 RISC 核心。而 MIPS 指令被认为代表了最纯粹的 RISC 思想。
搬砖之道
首先来展览下优化结果:
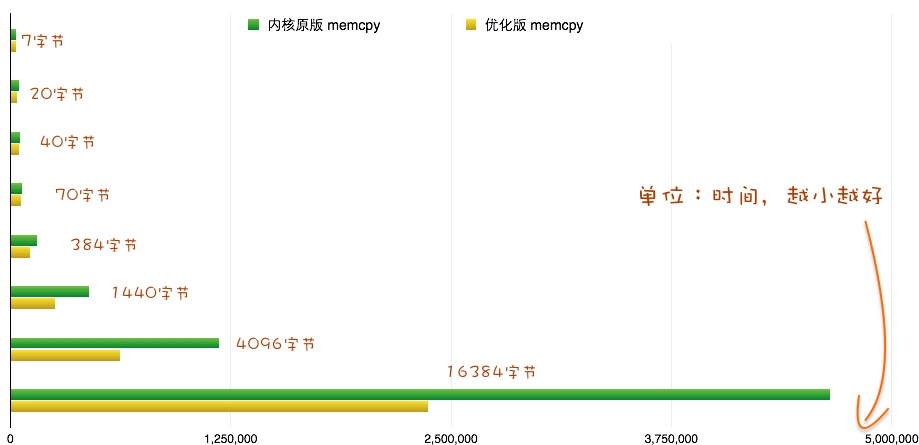
随着拷贝变大,优化效果越明显 —— 至多节省一半的时间。
memcpy 过程实际上与搬砖是类似的,从内存 A 搬到寄存器,再从寄存器搬到内存 B。于是,优化的核心在于一次搬更多砖:

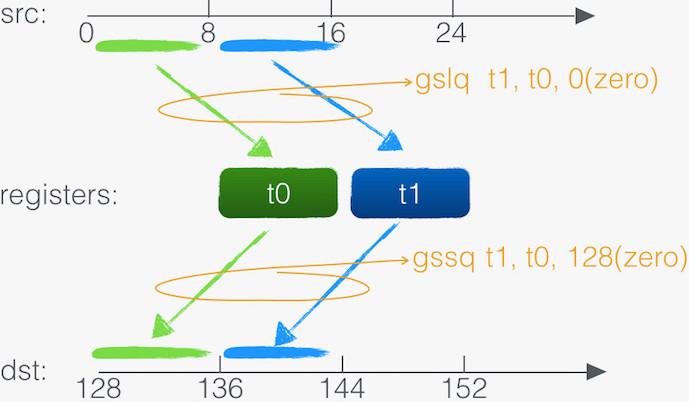
本次优化即使用了 gslq/gssq 128 位装载/存储指令 来 替代 64 位的 ld/sd 指令。
gslq/gssq 指令如下图所示:
对齐之道
然而,提高效率往往意味着更多限制,gslq/gssq 指令有着更高的地址对齐要求,即:
- 对于 gslq 指令而言,要求装载地址是 128 位对齐的(即地址能够整除 16 字节)。
- 对于 gssq 指令而言,要求存储地址是 128 位对齐的。
而现实情况,memcpy 拷贝的源地址 src 和目标地址 dst 可能是任意对齐的。一个自然的想法是,零散拷贝若干字节后,达到一个最佳对齐状态,然后提速拷贝。这个过程有点像汽车行驶过程中的换档:
- memcpy 先低速档拷贝若干字节,达到最佳对齐。
- memcpy 在高速档拷贝,直至剩余字节小于高速档一次拷贝量。
- memcpy 再降回低速档,拷贝余下字节。
通过简单的代数运算,我们可以知道最佳对齐状态为:
src 和 dst 两者任一升到所需最高对齐。一方升到最高对齐后,另一方的对齐由 dst 和 src “余数差”决定:
diff = | dst % N - src % N | # N 为最高对齐,比如 gslq/gssq 例子中,N = 16
若“余数差” diff 含有 M 个 2 因子,则另一方可升级到 2^M 对齐。
晕了?让我们举个例子:若拷贝长度足够,src = 3, dst = 43, 为尽量满足 gslq/gssq 访存对齐,升级后,src 和 dst 之一可至 16 字节对齐,而另一方对齐则取决于余数差:
diff = | 43 % 16 - 3 % 16 | = 8
余数差含有 3 个 2 因子,故另一方可升级到 8 字节对齐。最后对齐效果可以是:src + 13 = 16,dst + 13 = 56;或者 dst + 5 = 48, src + 5 = 8。
在算法的编程实现中,可以进一步近似,来优化/简化实现。比如在“升级对齐算法”的实现中,采用了如下近似:
一律将 dst 对齐。在本例优化中,此近似带来的最坏情形为src 已 16 字节对齐而 dst 不是(需搬运 16 字节来使 dst 对齐),却能减少分支情况,缩减代码块。
“升级对齐后”的情形,只区分三类:“dst 和 src 均 16 字节对齐”、“dst 16 字节对齐,而 src 是 8 字节对齐“、“dst 16 字节对齐,而 src 为其他对齐情况”。注:对 src 再做 8 字节对齐和其他情形的区分,是因为搬运等长内存块,前者所需指令可以更少(ld + sd vs ldr+ldl + sdr+sdl)。
汇编代码如下:
andi t0, dst, 0xf /* dst 地址除 16 的余数 */
andi t1, src, 0xf /* src 地址除 16 的余数 */
beqz t0, 1f /* t0 = dst % 16,t0 == 0,代表 dst 是对齐的,此时跳过升级 */
daddi rem, t0, -0x10 /* 该条指令位于分支指令之后,这个位置叫做延时槽。
* 延时槽中指令无论分支是否成立 均执行 */
ldr t3, 0(src)
sltu t4, t0, 0x8 /* t0 < 8 ? t4 = 1 : t4 = 0 */
ldl t3, 7(src) /* ldr 和 ldl 两条指令,从 src 读取了 8 个字节
* 该指令即为 MIPS 下著名的非对齐访问指令,又被称作左右部装载指令。
* 不过,在最新 MIPS64r6 中,该组指令被废弃(而 ld/sd 等指令开始支持
* 非对齐的地址。尽管如此,ld/sd 等指令非对齐访问时,开销会更大 */
dsubu src, rem /* rem = dst % 16 - 16,此处 src -= rem
* 以下拷贝 -rem 个字节,从而使 dst 升级为 16 字节对齐 */
sdr t3, 0(dst) /* 左部存储指令。写入对应字节到 从 “dst” 开始至“8 字节对齐”的区间。
* 左右部装载指令之含义见下图 */
dsubu dst, rem /* dst 也前进到对齐操作完成后的位置 */
beqz t4, 1f /* 需再拷贝 8 个字节吗?*/
daddu len, rem /* len 长度减去本次拷贝的字节数 */
ldr t3, -8(src) /* 再搬运 8 字节 */
ldl t3, -1(src)
sd t3, -8(dst)
1: /* 升级对齐结束 */
andi t7, src, 0x7 /* 升级后的 src 地址除 8 的余数 */
beq t0, t1, .L_memcpy_16_16 /* 原 dst/src 地址除 16 的余数
* 相等一定能升级成均 16 字节对齐情形
* 此时走“最好出路” */
nop
bnez t7, .L_memcpy_16_4_2_1 /* t7 = src % 8,不等零,走“最坏出路” */
.L_memcpy_16_8: /* 以下开始“不好不坏的出路” */
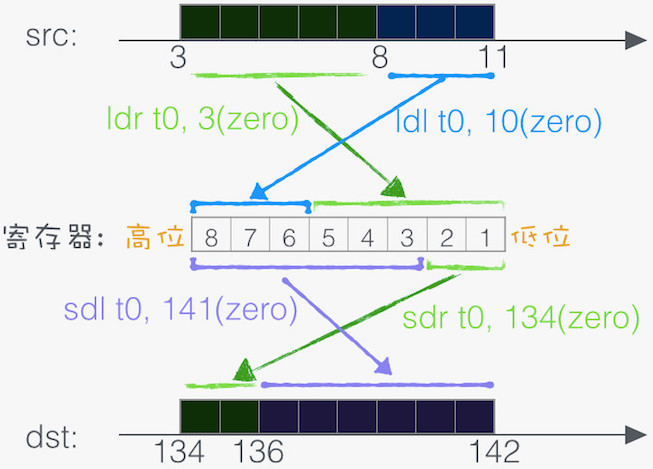
下图为 8 字节左右部访存指令的示意,注意左右部的说法,实际上是指寄存器的左边(高位)或右边(低位),依大小尾端而不同。下图展示的是小尾端的情形:
超标量之道
超标量是指一次执行 1 条以上的指令,即所谓的 N 发射。联想搬砖的比喻,有了以下画面:

要达到超标量的前提是取指必须跟上。已知龙芯是一个 4 发射的处理器,一条指令是 4 字节。于是拷贝循环中的一轮要有 4 条以上的指令才合算,且开头得是 4(发射) * 4(字节一条指令)= 16 字节对齐。
这就是下面代码块中“.align 4”的含义:
/* 循环拷贝、一次拷贝 64 字节的代码块 */
andi rem, len, 0x3f /* 不足 64 字节部分,即本代码块走完后的
* 剩余待拷贝字节数 */
.align 4 /* 1 << 4 字节对齐 */
1:
gslq t7, t4, (16 * 0)(src)
gslq t3, t2, (16 * 1)(src)
gslq t1, t0, (16 * 2)(src)
daddi len, -16 * 4
gssq t7, t4, (16 * 0)(dst)
gslq t7, t4, (16 * 3)(src)
daddi src, 16 * 4
daddi dst, 16 * 4
gssq t3, t2, (-16 * 3)(dst)
gssq t1, t0, (-16 * 2)(dst)
gssq t7, t4, (-16 * 1)(dst)
bne len, rem, 1b
nop
收官之道
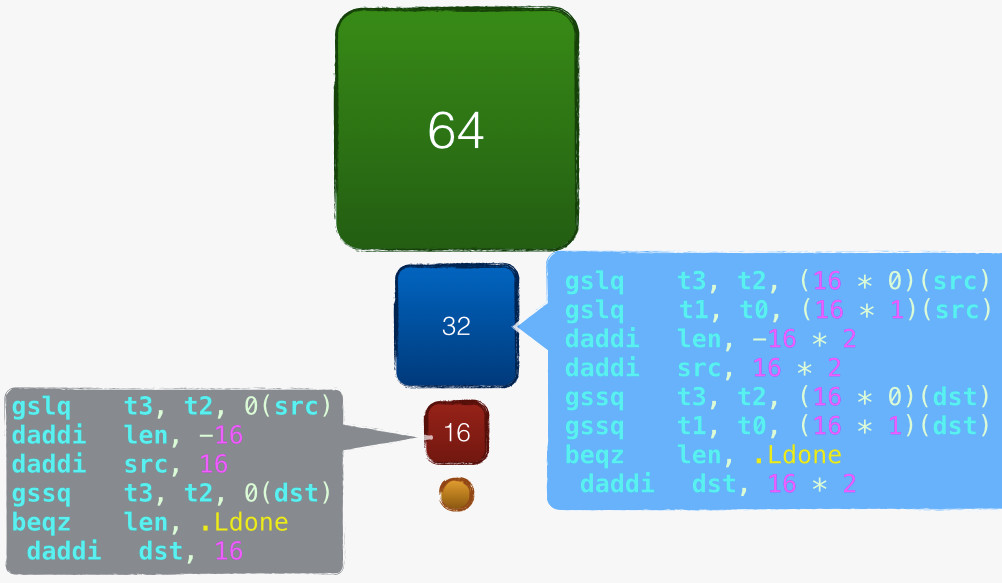
如前文所述,拷贝主体是 64 字节一轮的循环,不足 64 字节尝试一次 32 字节的拷贝,而后尝试一次 16 字节的拷贝,最后处理剩余字节,:下图是 .L_memcpy_16_16 拷贝的简单示意:
特别拿出拷贝最后剩余字节的代码:
sltu t0, len, 0x9 /* t0 = len < 9 ? 1 : 0 */
bnez t0, 1f
nop
ld t1, (src) /* 拷贝 8 字节 */
sd t1, (dst)
1: /* 以下拷贝:
* 自“结尾前一个 8 字节对齐处”,到“结尾”的字节 */
daddu src, len
daddu dst, len
ldl t1, -1(src)
sdl t1, -1(dst)
最后的最后,上面所述的都是足够多字节的拷贝,对于拷贝长度较小(比如,甚至小于“升级对齐”所需拷贝字节数),需直接收官,该过程又分作仨分支来处理:
- 拷贝长度在 8 字节 - 阀值
- 拷贝长度在 4 – 8 字节
- 拷贝长度小于 4 字节
下面贴出较有特点的“8 字节 - 阀值”的拷贝图示:

其特点在于写出全部 8 字节拷贝指令块,再根据具体拷贝长度,来计算跳转到何处开始拷贝:
andi t0, len, 0x7 /* t0 = len % 8 */
beq t0, len, 2f /* 小于 8 字节,去其他分支滴干活 */
andi t4, len, 0x3 /* 利用延时槽干点私活(其他分支用到) */
.set reorder /* 喂,汇编器,看着优化下(指令重排) */
dsubu t1, len, t0 /* t1 = len - len % 8 */
daddu dst, t1
daddu src, t1
.set at=t2 /* 下面指令是条伪指令,需辅助寄存器。指定之,避免捣乱 */
dla t3, 1f /* 1f 的位置,参见上图 */
.set noat
dsll t2, t1, 0x1 /* 左移一位,因为 4 条指令(16字节)
* 搬运 8 字节 */
dsubu t3, t2
jr t3
.set noreorder /* 喂,汇编器,别动我的代码了 */
上面拷贝完还剩下的不足 8 字节的部分,使用 从最后位置向前拷贝 8 字节 的方法处理。可能会重复拷贝,但可以很帅气地无视之,因为这样省了不少指令噻。
小结
最后再啰嗦两点,一是本 memcpy 核心在于“升级对齐”,该思路适于任何有两内存地址的操作,比如 memcmp。二是 memcpy 拷贝的实现,其实不是一字节一字节地搬运(特别是还存在重复拷贝),因此需要慎对 IO Memory 的拷贝。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
