

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
天高气爽阅码疾:一日看尽虚拟化(上)
by Chen Jie of TinyLab.org 2020/11/08
前言
近来 @Chengbo 同学分享了一系列的虚拟化实践,广受欢迎。于是,决定蹭一蹭热度,以 ARMv8 为例,将虚拟化的名词概念摆一摆,拼成一个地图方便查阅。
在出发之前,想一想以下几个问题:
- 关于内存虚拟化,ARMv8 为例,Guest 访问了未映射的地址,其异常处理是怎样的 ?
- 关于 CPU 虚拟化,ARMv8 为例,哪些情况下会 trap 到 host ?
- 关于中断,ARMv8 为例,从收到中断,到派发到 Guest OS 中,具体过程是怎样的?
- 对于一个 Guest OS,至少 需要 虚拟化哪些设备?
- 关于设备共享,半虚拟化(Para-Virtualization)技术,Virtio 是什么 ?vhost 又与之是什么关系?
- 关于设备 Pass-through,VFIO 扮演了什么角色?
- 串一串,图形系统是如何虚拟化的?
首先,我们从 Kvmtool 出发,来看一个整体的流程。Kvmtool 定位上类似 qemu(kvm 模式),但非常轻量化,故而阅码体验很清爽。
鸟瞰:虚拟化工作流一览
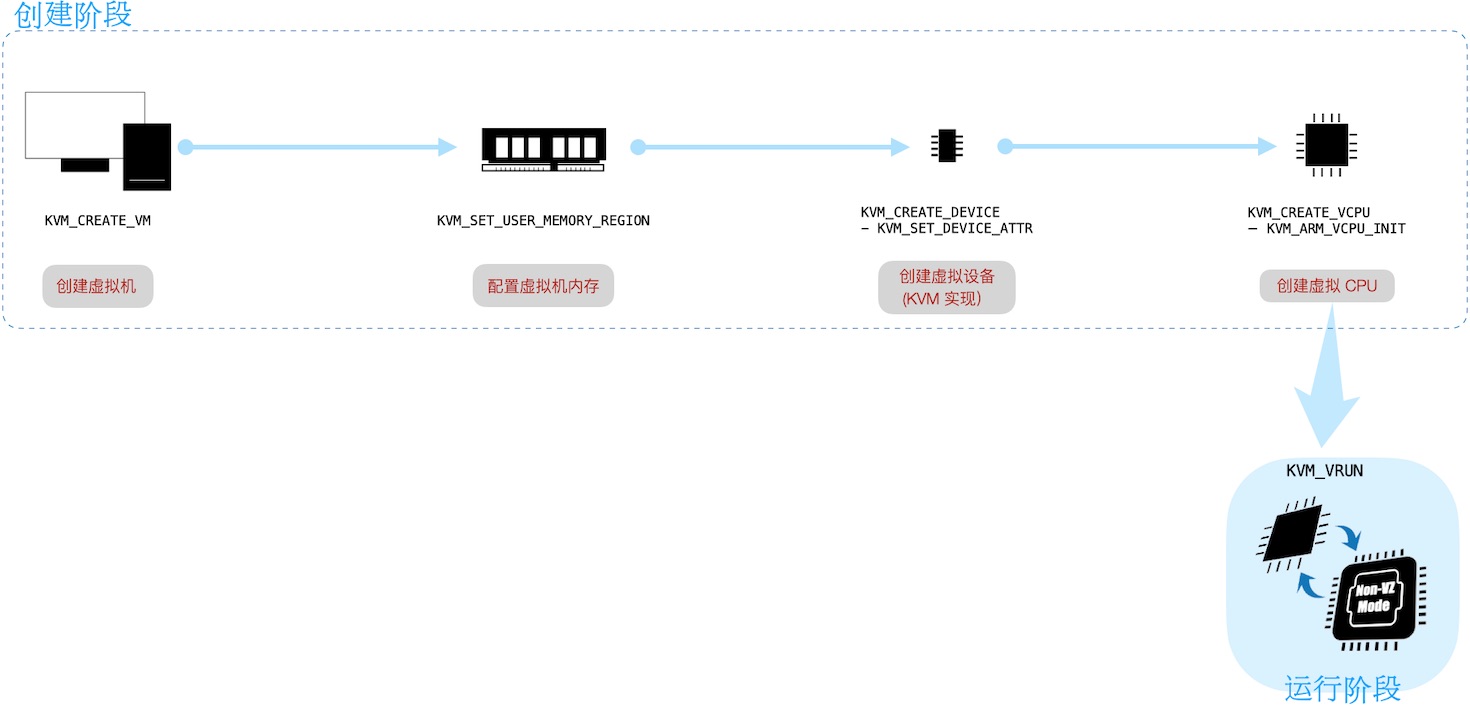
下面从 Kvmtool 中剔出关键行,来一览图中俩阶段。
创建阶段
ctrl_fd = open("/dev/kvm", O_RDWR);
/**
* 1. 创建虚拟机 (kvm.c)
*/
int vm_fd = ioctl(ctrl_fd, KVM_CREATE_VM, KVM_VM_TYPE);
/**
* 2. 添内存 (kvm.c)
*/
struct kvm_userspace_memory_region mem = {
.slot = slot /* count from 0, slot number of "virtual mem" */ ,
.guest_phys_addr = ... ,
.memory_size = ... ,
.userspace_addr = ... /* 用户空间的这段内存,给 VM 用,映射到 GPA */
};
ioctl(vm_fd, KVM_SET_USER_MEMORY_REGION, &mem);
/**
* 3. 创建必要设备:中断控制器 GIC (以 v2 版本为例)(arm/gic.c)
*/
struct kvm_create_device gic_device = {
.flags = 0,
.type = KVM_VGIC_V2_ADDR_TYPE_DIST,
/* output field: .fd */
};
/* ARM GICv2,中断分发路上的俩节点:distributor -> CPU interface */
struct kvm_device_attr cpu_if_attr = { ... };
struct kvm_device_attr dist_attr = { ... };
ioctl(vm_fd, KVM_CREATE_DEVICE, &gic_device);
ioctl(gic_device.fd, KVM_SET_DEVICE_ATTR, &cpu_if_attr);
ioctl(gic_device.fd, KVM_SET_DEVICE_ATTR, &dist_attr);
/**
* 4. 添加、配置、初始化 VCPU (arm/kvm-cpu.c)
*/
int vcpu_fd = ioctl(vm_fd, KVM_CREATE_VCPU, cpu_id /* count from 0 */);
/* mmap 后,用于获得 VM_EXIT 现场 */
struct kvm_run *kvm_run = mmap(NULL, VCPU_MMAP_SIZE, ... vcpu_fd);
ioctl(vcpu_fd, KVM_ARM_VCPU_INIT, &vcpu_init /* struct kvm_vcpu_init, 用于 VCPU 特性配置 */);
运行阶段
- VCPU reset:
- 当前线程调用 ioctl
KVM_RUN后,成为虚拟机 VCPU 的一个核 - 在此之前,需要配置 VCPU “上电” 时刻,包括 PC 在内的各个寄存器的值
- 当前线程调用 ioctl
/**
* VCPU reset (arm/aarch64/kvm-cpu.c)
*/
struct kvm_one_reg *regs[] = {
&pstate_reg, /* Current Program Status Register: all interrupts masked */
/* linux boot protocol */
&x1_reg, /* 0 */
&x2_reg, /* 0 */
&x3_reg, /* 0 */
&pc_reg, /* start of kernel image
* Note:内存添加后,一份 kernel image 拷贝至对应地址
*/
&x0_reg, /* physical addr of dtb
* Note:内存添加后,一份指定的 dtb 拷贝至对应地址
* dtb 包含:memory / GIC / timer / CPU,以及 virtio-* 的 device node,
* 由 Kvmtool 生成
*/
};
N = vcpu_id == 0 ? N_ELEMS(regs) : \
N_ELEMS(regs) - 2 /* Secondary cores: wait for PSCI wakeup */;
for (i = 0; i < N; i++) {
ioctl(vcpu_fd, KVM_SET_ONE_REG, regs[i]);
}
- VCPU run:
- 因为各种原因,VCPU 会切出,即所谓的 VM_EXIT
- 对各种 “VCPU 切出” 情形进行处理,如伪代码中
switch... case...所示
/**
* VCPU run (kvm-cpu.c)
*/
void vcore_thread() {
while (runing) {
ioctl(vcpu_fd, KVM_RUN, 0);
switch(kvm_run->exit_reason /* kvm_run 是先前 mmap(vcpu_fd, ...) */) {
case KVM_EXIT_UNKNOWN: break;
case KVM_EXIT_DEBUG: /* show regs, code ... */ break;
case KVM_EXIT_MMIO:
/**
* fn = lookup_handler(kvm_run->mmio.phys_addr, kvm_run->mmio.is_write);
* fn(kvm_run->mmio.data, kvm_run->mmio.len);
*/
break;
case KVM_EXIT_SHUWDOWN: return; /* 仅本 core 退出*/
case KVM_EXIT_SYSTEM_EVENT:
/* sub-events: KVM_SYSTEM_EVENT_RESET、KVM_SYSTEM_EVENT_SHUTDOWN */
#define SIGKVMEXIT (SIGRTMIN + 0)
pthread_kill(cpu0->thread, SIGKVMEXIT);
return;
...
}
}
}
问题 1:内存虚拟化后的 Fault 处理
考虑 Guest OS 触发了缺页错误,其处理过程是怎样的?
为解释这个过程,首先交待一些背景,包括:
- 虚拟化之后的 2-Stages 内存映射
- 为修复缺页,需要建立 Stage 2 的映射,这是由异常的 handler 来完成。那么,相关的异常向量表是怎样的 ?
再进一步,通常说,Host OS 负责驱动物理设备,并运行一些用户态的管理程序。
那么 Host OS 和 Hypervisor 是一回事吗?
- 在 ARMv8 的 VHE 模式下,它俩合二为一
- 那么 VHE 模式是啥 呢?
当 Host OS 和 Hypervisor 合二为一后,它的异常处理就有些混淆了,例如:
- 处于 EL1 的 Guest OS 发生缺页,陷入到 EL2 的 Host OS(本节主问题)
- 处于 EL0 的 Host 用户态程序,发生缺页,陷入到 EL2 的 Host OS
—— 在 KVM 中,对此分别准备了不同的异常向量表,并在 Guest ↔ Host World Switch 中进行切换。
做完上述必要的背景铺垫后,KVM 的 Fault 处理过程就可以展示在一个流程图中。
背景:ARM 特权级与内存虚拟化
虚拟化首先意味着更多的特权级,在常见的 User space、Kernel space 之后,进一步加入了专属于 Hypervisor 的特权级。
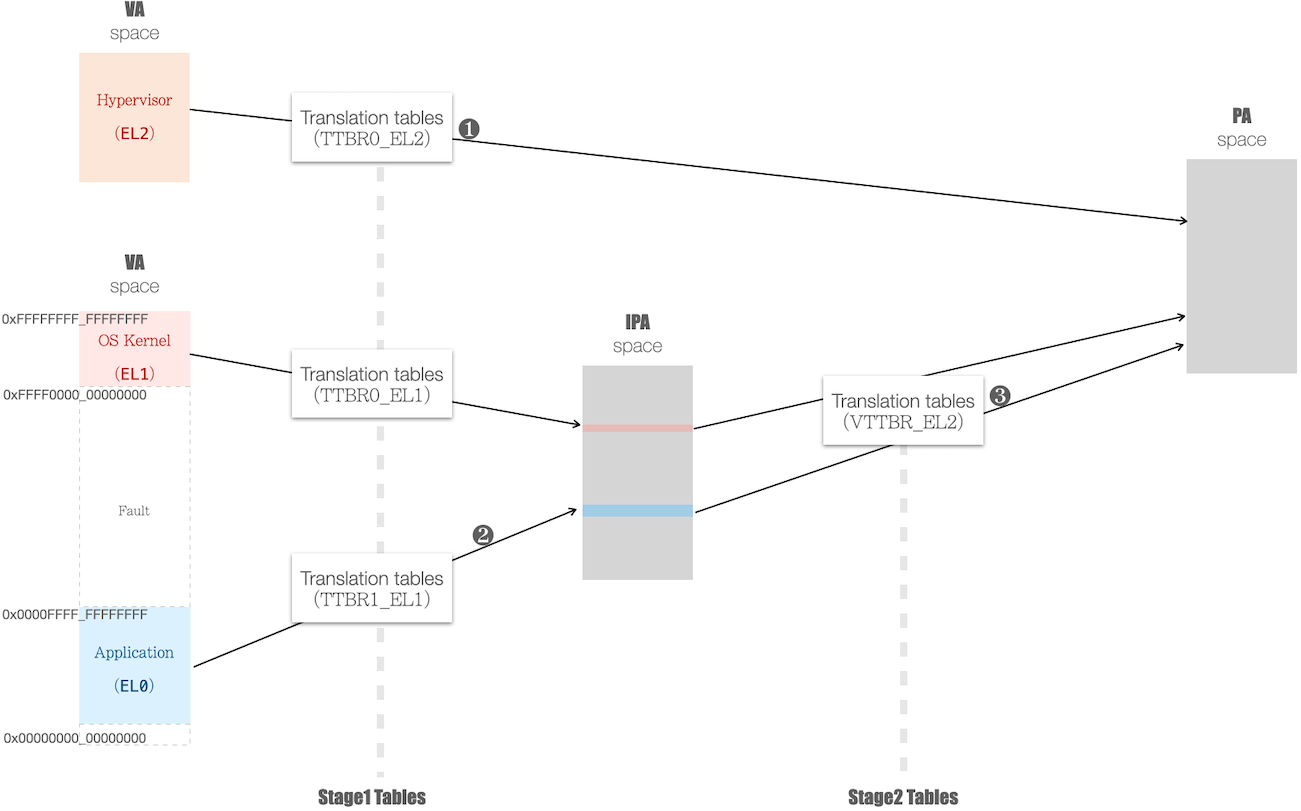
对应到 ARM,User space 运行在 EL0,而 Kernel space 运行在 EL1,而 Hypervisor 运行在 EL2,如下图所示:

为兼容现代 OS Kernel 的 Memory Management 子系统,处理器的 mmu 单元增加了额外的一次映射,如下图中:
- Guest OS (EL1 Kernel space + EL0 的 User space),开启了 2-Stages 映射
- VA(Virtual Address) 先映射成 IPA(Intermediate Physical Address),再最终映射成 PA(Physical Address)
- 作为对比,对于 Hypervisor 自身,仍是 1-Stage 映射
- 其顶级页表(PGD)的物理地址,由
TBBR0_EL2寄存器所指向
- 其顶级页表(PGD)的物理地址,由
本小节余下部分,展开下 ARMv8 MMU 相关配置细节,为阅读流畅可自行跳过。
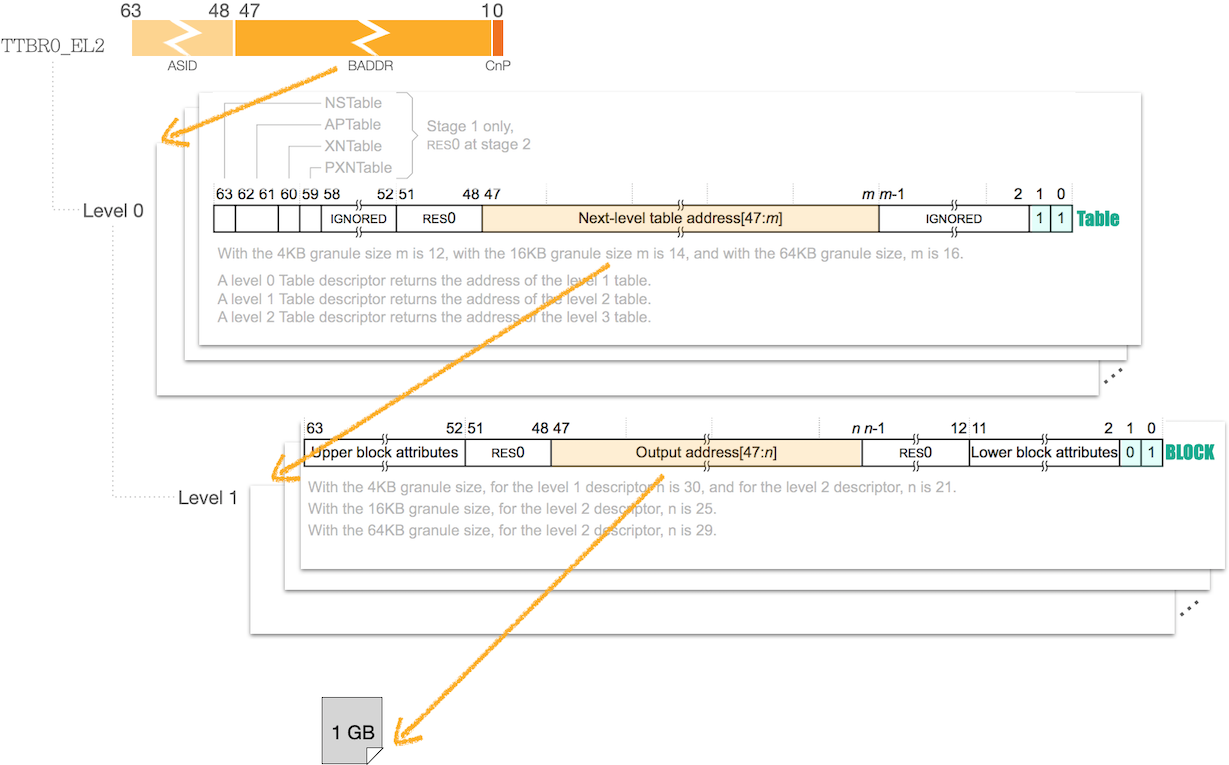
首先展开下 Hypervisor 的虚拟内存映射(即图中标注的 ❶):
- 如下图的一个虚拟地址:
- 对它的翻译只启用了两级页表,页大小为 1GB
- 大页减少了页数,从而减少了 TLB missing 频率,有益于性能
相应的层级 地址空间,如下图:
需要说明的是,
TTBR0_EL2存在一些关联的寄存器。例如控制具体映射的TCR_EL2,它的TG0field决定了页的最小粒度(4KB、16KB 还是 64KB)图中 Lower block attributes 用于指定页的 cache 一致性行为、cache 策略、以及总线缓冲策略,关联寄存器为
MAIR_EL2。

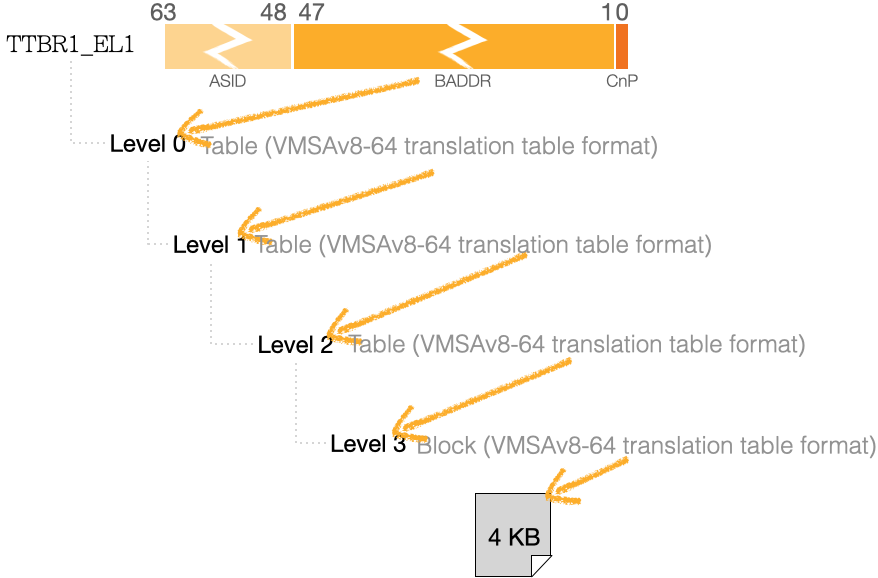
进一步展示 Guest OS 中虚拟内存映射(图中标注的 ❷ 和 ❸):
其中 ❷ 是由 OS Kernel 来配置,其目的是 VA → IPA
- 如下图示 VA,是最经典的四级页表,页大小为 4KB
- 相应的层级 地址空间,如下图:
- VA 高位
[63:47]选择了TTBR1_EL1寄存器;其关联寄存器有TCR_EL1和MAIR_EL1
而 ❸ 是由 Hypervisor 来配置,其目的是 IPA → PA
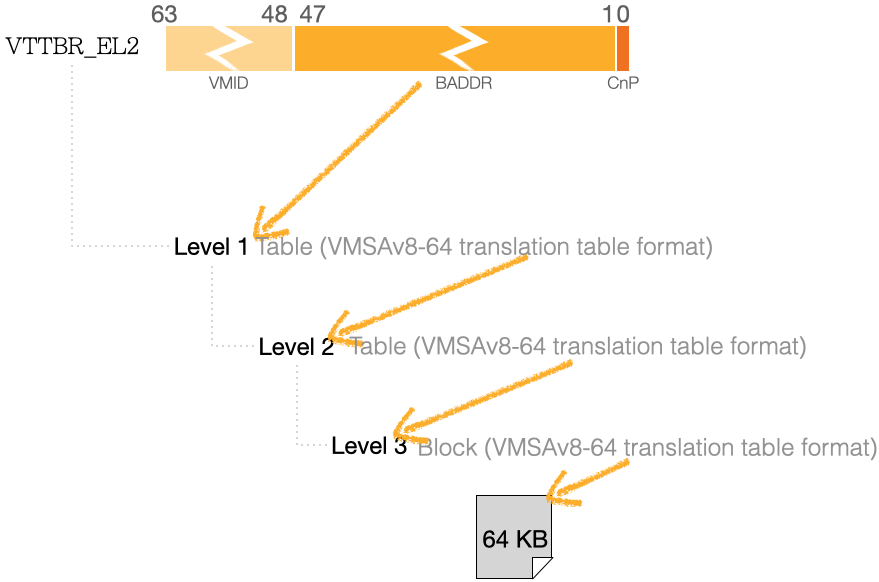
- 如下图示 VA,对应较不常见的 64KB 页,留意地址编码中留给 Level 0 “零个位”。
- 相应的层级 地址空间,如下图:
- 留意
VTTBR_EL2寄存器,其高位由 ASID 变成了 VMID;其关联寄存器有VTCR_EL2


背景:ARMv8 的 VHE 模式
从上一节开篇图示可见,开启虚拟化模式之后,传统的 OS Kernel Space 之下多出一个特权级,封装了虚拟化相关的特权操作。
KVM 一部分逻辑,即是此类特权操作封装与抽象。另一方面,KVM 巧妙复用了 Linux kernel 代码,例如
- VCPU 是一组运行在 Host OS 中 threads —— 复用 scheduler
- 复用中断控制器驱动、时钟服务,及其他设备驱动
此处 KVM 复用 Linux kernel,可视作一个 delegation model —— 存在接口以及相应开销。而 ARMv8-A 的 VHE 扩展,则是将 Host OS Kernel 与 Hypervisor 同置于 EL2 级,从而移除相应开销,两者区别如下图所示:
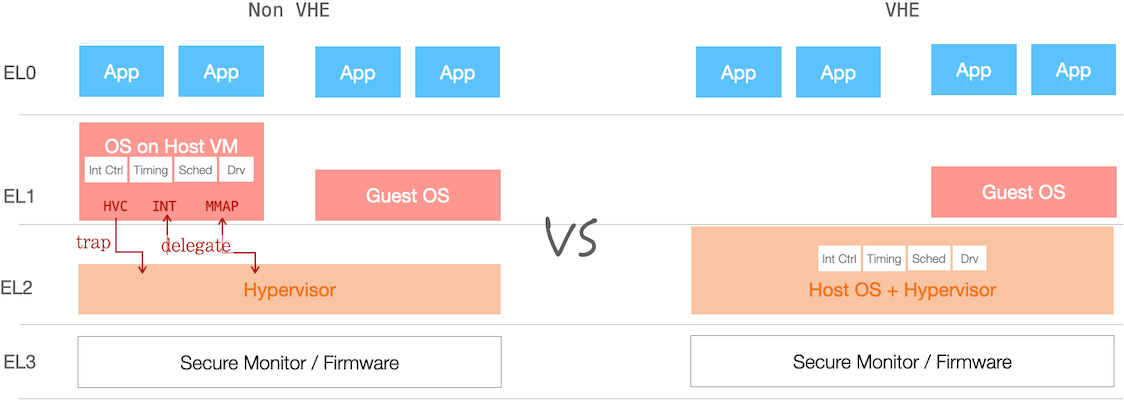
进一步从 Userspace 视角对比 non-VHE 与 VHE:
- Host OS 中的 App (EL0),它只有一个 1 Stage 的映射(Level 0 页表基址由
TTBR1_EL2所指) - 而 Guest OS 中的 App (EL0),则经历 2 Stages 的映射
由于 Kvmtool (以及 qemu)运行于 Host OS 的 Userspace,VHE 开启后,伴随映射的 Stage 减少,性能得到提升。
在 ARMv8 中,通过设置
HCR(Hyp Configuration Register)寄存器的E2H位,来开启 VHE 模式进一步补充两个问题:
- VHE 开启后,PE 如何区分 EL0 是 Host App,还是 Guest App呢?
答案摘录自 ARMv8 官方文档「Virtualization Host Extensions」:
Executing in HCR_EL2.E2H HCR_EL2.TGE Guest Kernel (EL1) 1 0 Guest Application (EL0) 1 0 Host Kernel (EL2) 1 1* Host Application (EL0) 1 1 * 注:当 VM_EXIT 到 Hypervisor 时,TGE 为 0。需在 Trap handler 中先将其设置为 1,再来运行 Hypervisor 后续代码。
- 如何让 Linux kernel 快速兼容 VHE 模式?
答案是 VHE 开启后,将寄存器进行兼容性映射 —— 处于 LE2 代码,访问 EL1 系列寄存器,实际访问 “对应的 EL2 寄存器”。
例如,访问 TTBR0_EL1 实际访问的是 TTBR0_EL2。
后文以 VHE 开启为前提进行情景分析。
Fault 处理过程
交待完背景,正式开始 Memory Fault 的情景分析。
当 涉及 Stage 2 映射的 Fault 发生时,处理器核直接跳转到异常向量表的某项;而异常向量表的 虚拟地址,则是由 VBAR_EL2 寄存器所指向。
Note + 严肃脸:
- 留意 ARM 文档中的 “异常” 不仅指异常(同步),还包括了中断(异步)。故而严格说,“异常向量表” 应该叫做 “异常中断向量表”
- 下文从俗:提及异常时,混指异常和中断
这个异常向量表可分成 4 “段”,每段包含 4 个入口,如下:
| “段” | “段” 简介 | 异常项(每项 128B) |
|---|---|---|
| 0 | 异常会陷入 EL2,且 a) 异常发生时处于 EL2 b) SPSel 设置 SP 映射为 SP_EL0 (EL2t)Linux Kernel 不使用 | [0] sync:处理 “(严格定义下)异常” 的入口 |
| [1] irq:处理中断的入口 | ||
| [2] fiq:处理快中断入口 | ||
| [3] SError:例如异步访存 —— 延迟出结果(或错误) | ||
| 1 | 异常会陷入 EL2,且 a) 异常发生时处于 EL2 b) SPSel 设置 SP 映射为 SP_EL2 (EL2h) | [0] sync |
| [1] irq | ||
| [2] fiq: Linux kernel 不使用 | ||
| [3] SError | ||
| 2 | 异常会陷入 EL2,且 a) 异常发生时处于 EL0 或 EL1 b) EL0 或 EL1 为 64bits 环境 | [0] sync |
| [1] irq | ||
| [2] fiq: Linux kernel 不使用 | ||
| [3] SError | ||
| 3 | 异常会陷入 EL2,且 a) 异常发生时处于 EL0 或 EL1 b) EL0 或 EL1 为 32bits 环境 | [0] sync |
| [1] irq | ||
| [2] fiq: Linux kernel 不使用 | ||
| [3] SError |
对应到 Linux kernel 代码,上述异常向量表为 SYM_CODE_START(__kvm_hyp_vector)(arch/arm64/kvm/hyp/hyp-entry.S),它是在 arch/arm64/kvm/hyp/switch.c中设置的:
static void activate_traps_vhe(struct kvm_vcpu *vcpu) {
...
write_sysreg(kvm_get_hyp_vector(), vbar_el1);
// ^^^^^^^^ 回顾 VHE 模式,VBAR_EL1 实际映射到 VBAR_EL2
}
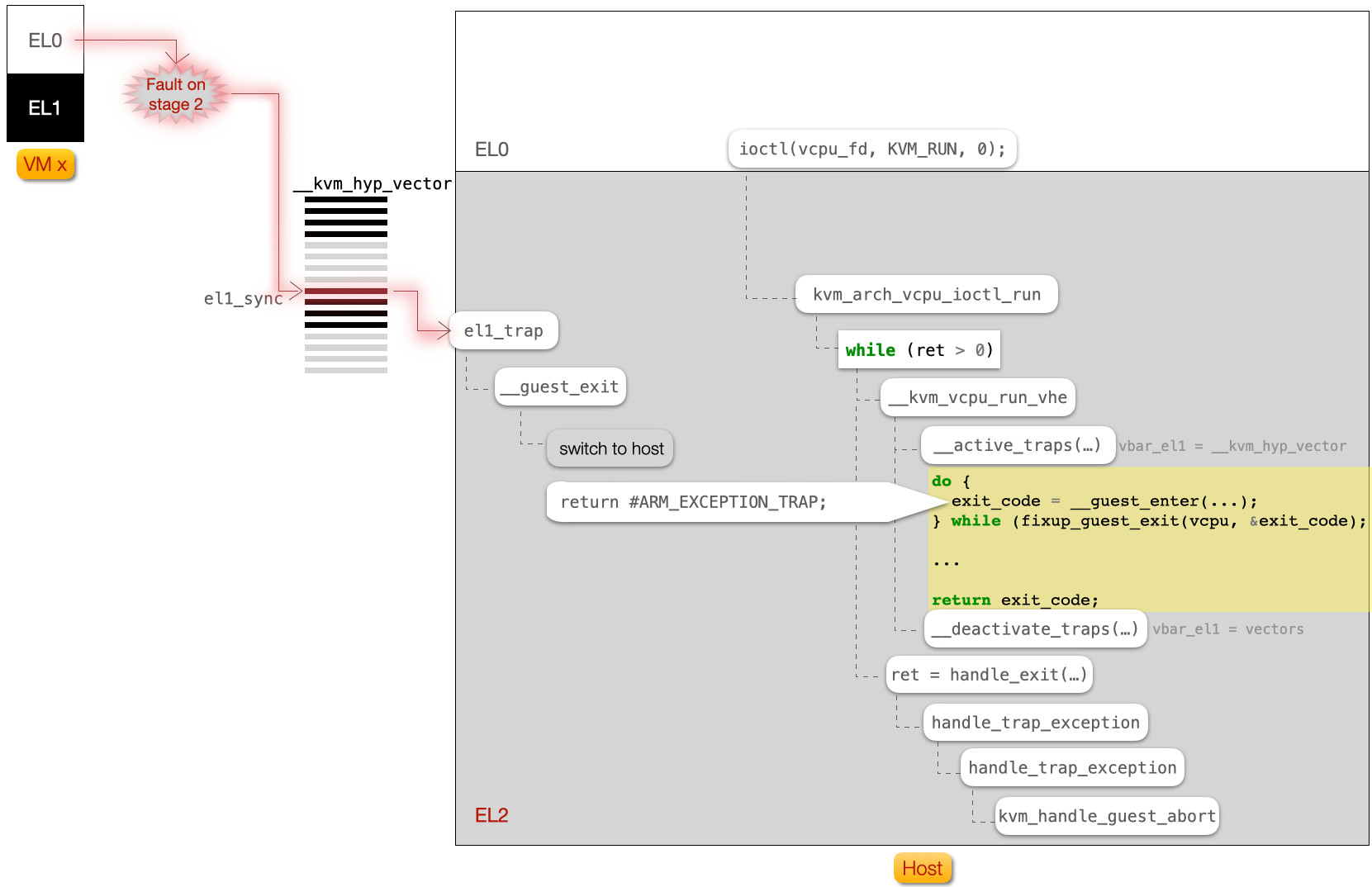
回到本节标题, Memory Fault 的处理流如下图所示:
- 某个 VM 中的进程触发了 缺页异常
- 最后在
kvm_handle_guest_abort(arch/arm64/kvm/mmu.c) 中,分配了物理页面,并建立起 Stage 2 的映射 - 留意异常向量表切换,例如离开 Guest 时,函数
__deactivate_traps()将异常向量表切换成了vectors(arch/arm64/kernel/entry.S)
问题 2:哪些情况可以 trap 到 EL2?
上一节中提及函数 handle_exit(), (arch/arm64/kvm/handle_exit.c) ,从中一窥究竟:
int handle_exit() {
switch (exception_index) {
case ARM_EXCEPTION_IRQ:
/**
* 设置 HCR_EL2.IMO 位后,中断经由 EL2 来中转
* 下节进一步展开
*/
...
case ARM_EXCEPTION_EL1_SERROR:
...
case ARM_EXCEPTION_TRAP:
/**
* 处理 “(严格定义下)异常”
* - 具体处理,分发给 arm_exit_handlers 某一条处理
* - 哪些过程可以产生“异常”?
* - 由 HCR_EL2 寄存器来配置
* - 如下 arm_exit_handlers 所枚举
*/
handle_trap_exceptions(...);
}
static exit_handle_fn arm_exit_handlers[] = {
[0 ... ESR_ELx_EC_MAX] = kvm_handle_unknown_ec,
[ESR_ELx_EC_WFx] = kvm_handle_wfx,
// ^^^^^^^^^^^^^^ Wait for interrupts/events
// 例如在 idle thread 中
[ESR_ELx_EC_CP15_32] = kvm_handle_cp15_32,
[ESR_ELx_EC_CP15_64] = kvm_handle_cp15_64,
[ESR_ELx_EC_CP14_MR] = kvm_handle_cp14_32,
[ESR_ELx_EC_CP14_LS] = kvm_handle_cp14_load_store,
[ESR_ELx_EC_CP14_64] = kvm_handle_cp14_64,
[ESR_ELx_EC_HVC32] = handle_hvc,
[ESR_ELx_EC_SMC32] = handle_smc,
[ESR_ELx_EC_HVC64] = handle_hvc,
// ^^^^^^^^^^ EL1 发起的 hvc 调用,陷入到 EL2
[ESR_ELx_EC_SMC64] = handle_smc,
// ^^^^^^^^^^ EL1 发起的 smc 调用,试图陷入 EL3
[ESR_ELx_EC_SYS64] = kvm_handle_sys_reg,
// ^^^^^^^^^^^^^^^^^^ 系统寄存器的 trap
[ESR_ELx_EC_SVE] = handle_sve,
[ESR_ELx_EC_IABT_LOW] = kvm_handle_guest_abort,
// ^^^^^^^^^^^^^^^^^^^^^^ 取指时发生的异常
[ESR_ELx_EC_DABT_LOW] = kvm_handle_guest_abort,
// ^^^^^^^^^^^^^^^^^^^^^^ 访问物理地址时异常
[ESR_ELx_EC_SOFTSTP_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_WATCHPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BREAKPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BKPT32] = kvm_handle_guest_debug,
[ESR_ELx_EC_BRK64] = kvm_handle_guest_debug,
[ESR_ELx_EC_FP_ASIMD] = handle_no_fpsimd,
[ESR_ELx_EC_PAC] = kvm_handle_ptrauth,
};
问题 3:虚拟化的中断处理过程
下图展示了中断的处理过程,含虚拟中断在内。
留意图中将 三个视角 的中断处理流程 “合三为一”,所以也可算(大)是(误) “立体派” 风格的插图了。
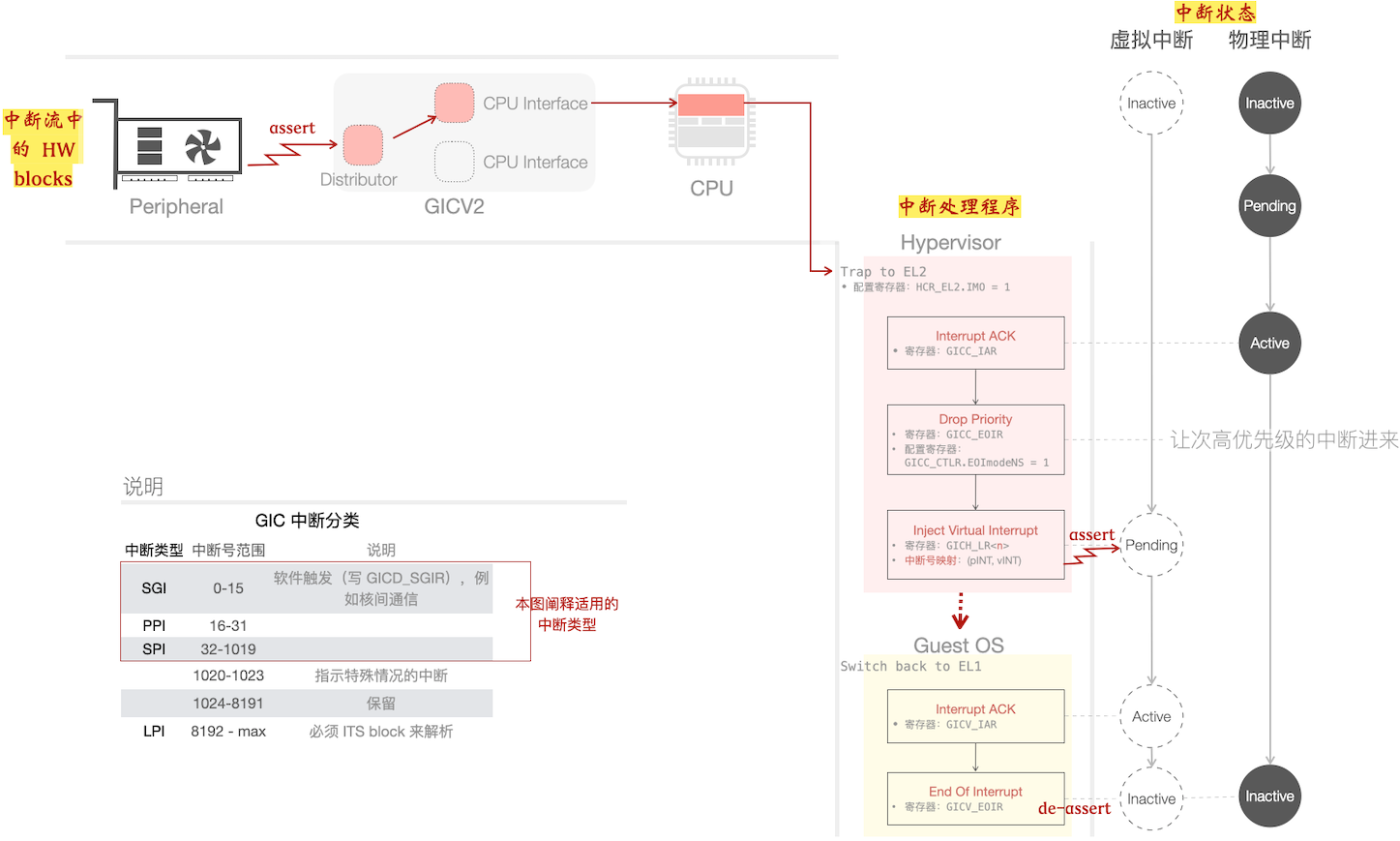
外设触发中断(assert),经过 GIC(Generic Interrupt Controller,图示为 v2 版本)派发到某个核上 (PE)。
图中展示的中断处理程序:Hypervisor 决定进一步注入给 Guest OS,意图让 Guest OS 来全权处理这些中断:
通过写入 List Registers (
GICH_LR<n>)来注入虚拟中断- 写入时,将虚拟与物理中断号 写成一对 —— 在 Guest EOI 时,GIC 会 连带 清物理中断
- List Registers 有多个,而 GIC 每次只送优先级最高的中断到 PE
- 通过 Drop Priority 操作,让 排在后面的 物理中断进来,充实更多的 List Registers
下面从两方面来进一步考察:
- 一方面只看物理中断的处理:中断状态的迁移,一头是 HW blocks,另一头是操作寄存器
- 另一方面,从编程视角,套入 KVM 模型来看虚拟中断处理的四个阶段
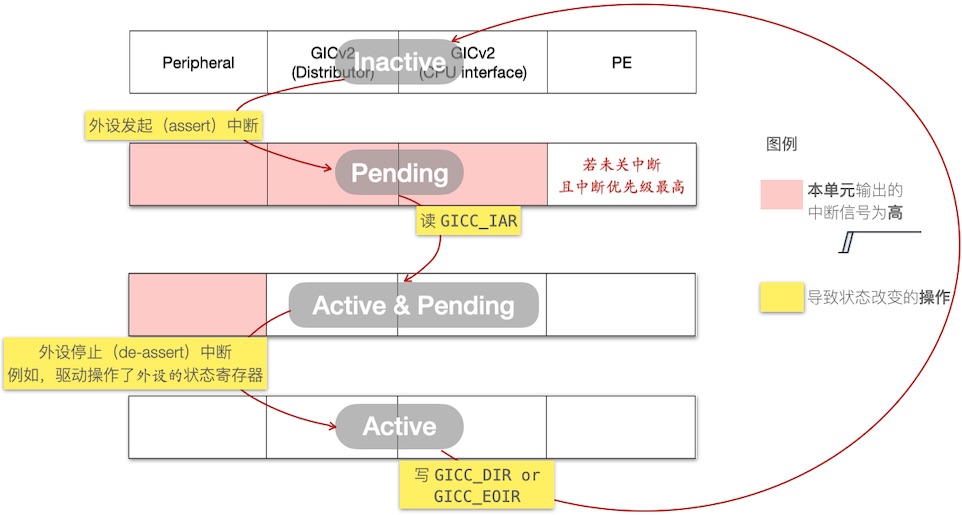
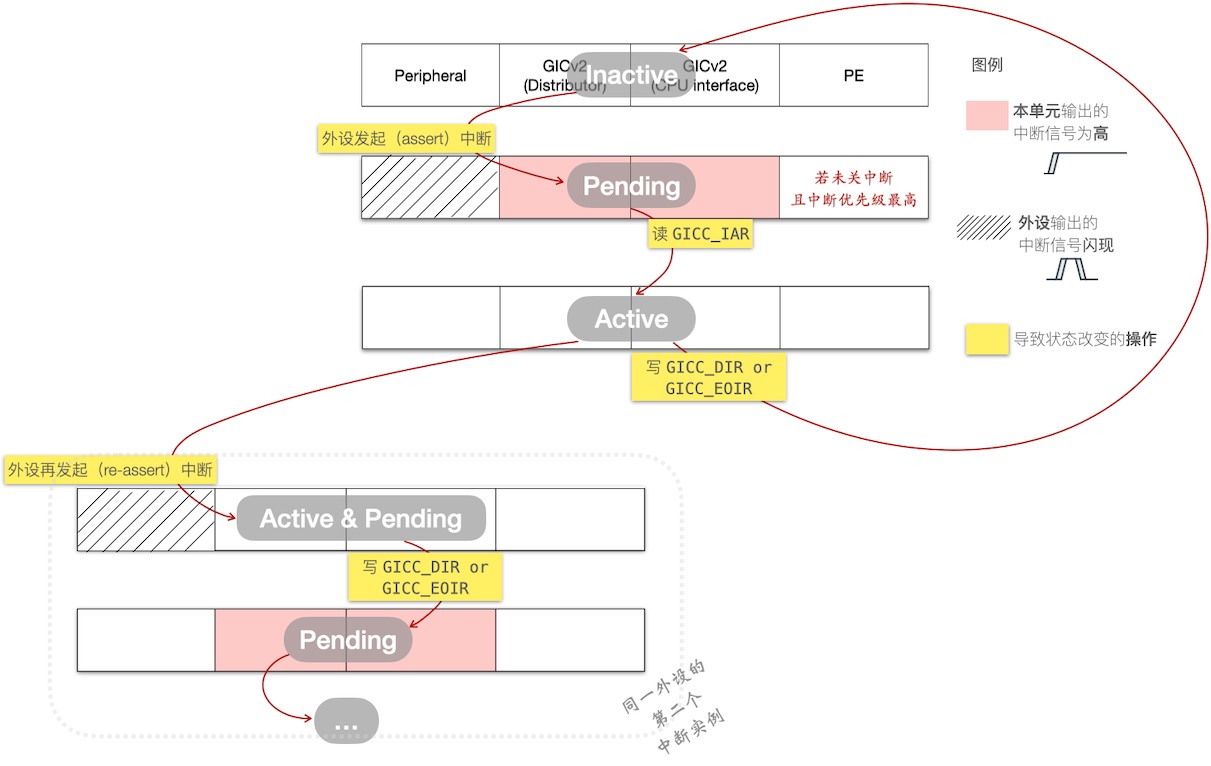
Level-triggered vs Edge-triggered
下面俩图围绕中断状态迁移(Inactive → Pending → … ),分别展开 位触发 和 边沿触发 。相关方包含 “HW blocks(及其中断信号)”、“操作寄存器”:
Level-triggered
Edge-triggered
Kvmtool:编程视角来看虚拟中断处理
从虚拟中断的使用场景来看,可分成两类情形:
设备共享:设备由 Host 来直接驱动,并向 Guest 导出成虚拟设备
代表性框架: Virtio
需要注入虚拟中断,模拟虚拟设备产生的中断
设备专用(Pass-through):设备透传给 Guest 专用,由 Guest OS 来驱动
可复用 Host Linux 的 VFIO 框架,可将设备透传给 Guest OS
需要注入对应设备 “物理中断” 的 “虚拟中断”
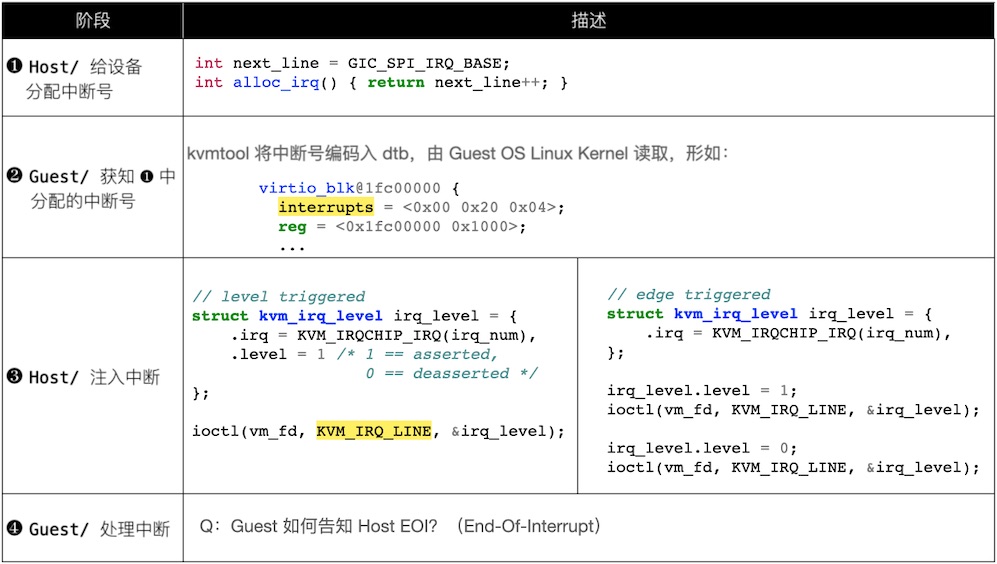
不管是共享还是专用,虚拟中断的编程可分为 4 个阶段:
- Host:虚拟中断的分配
- Guest:获知分配的虚拟中断
- Host:注入虚拟中断。在 Pass-through 情形,需要注入对应物理中断的虚拟中断
- Guest:处理虚拟中断 —— EOI 要通知到 Host,以便:
- 填入空出来的 List Registers,注入更多的虚拟中断
- 对于建立在 VFIO 之上的设备透传,需要清对应的物理中断
下表摘录了上述 4 个阶段,Kvmtool 中对应的代码:
Kvmtool:VFIO 编程视角的虚拟中断处理
Kvmtool 通过 VFIO 框架,来实现设备透传(Pass-through)。VFIO 是一个实现用户态驱动的框架,借助这个框架,也可以实现设备透传,如下图所展示:
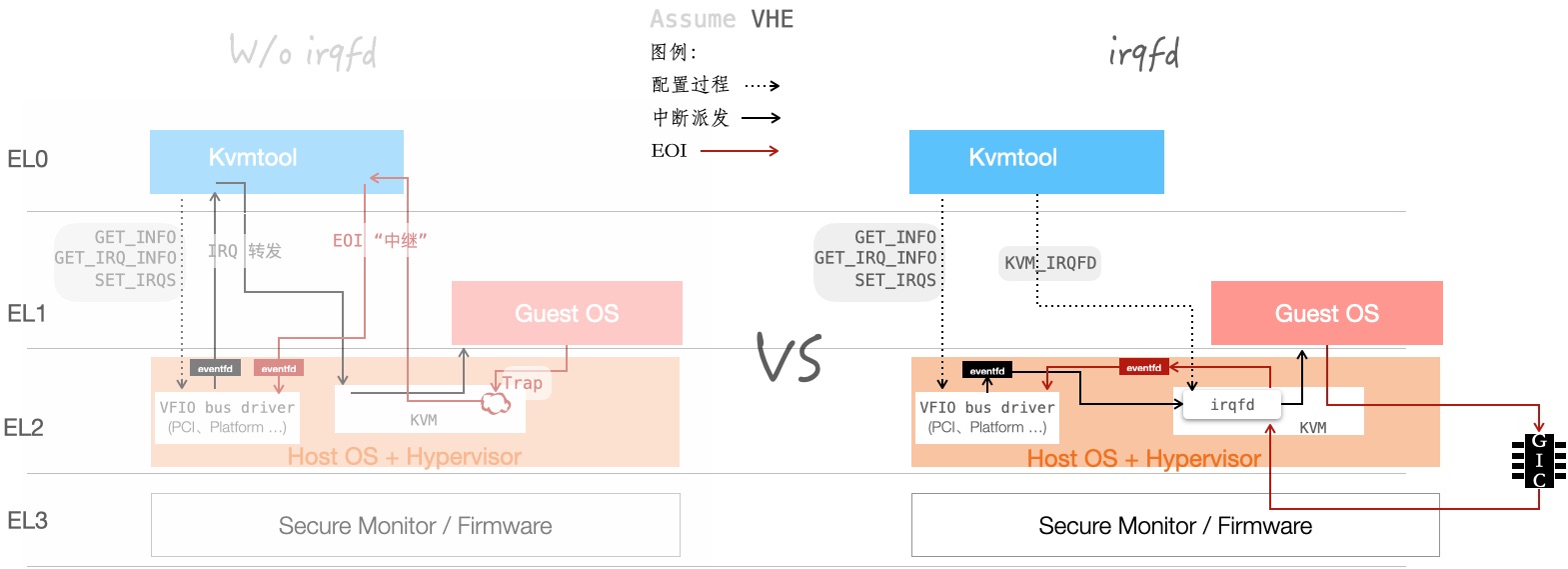
| 左侧:不使用 irqfd | 右侧 :使用 “irqfd 捷径” | |
|---|---|---|
| 物理中断转发 | 用户态的 Kvmtool 来进行转发(使用 ioctl KVM_IRQ_LINE 注入虚拟中断) | Host Kernel 内的两个模块间通信,完成中断转发 |
| EOI 物理中断 | (假设 Guest OS 中的驱动访问本设备 MMIO 空间,当作中断处理结束) - 于是预先配置 MMIO Trap,借此获知 EOI - 这更像是一种 workaround | 借助 GIC 的 Maintenance interrupt - 清虚拟中断时,Host Kernel 会收到 Maintenance interrupt(中断号 PPI 25),从而得到通知- Maintenance interrupt 的配置寄存器为 ICH_MISR_EL2 |
伪代码展开下 图例中的配置过程
- VFIO 相关的配置:
/**
* 首先:查询设备的 IRQ 信息 (以下代码以 VFIO Platform 为例)
*/
struct vfio_device_info dev_info = { .argsz = sizeof(dev_info) };
ioctl(device_fd, VFIO_DEVICE_GET_INFO, &dev_info); // dev_info.num_irqs
for (i = 0; i < dev_info.num_irqs; i++) {
struct vfio_irq_info irq_info = { .argsz = sizeof(irq_info),
.index = i
};
ioctl(device_fd, VFIO_DEVICE_GET_IRQ_INFO, &irq_info); // irq_info.{flags}
/**
* 其次:通过查询到的 irq_info{.index, .flags}
*/
// ① 绑定 eventfd —— 借助「读 eventfd」 获知物理中断到来
struct {
struct vfio_irq_set hdr;
int evt_fd;
} irq_set;
irq_set.hdr.argsz = sizeof(irq_set);
irq_set.flags = VFIO_IRQ_SET_DATA_EVENTFD | VFIO_IRQ_SET_ACTION_TRIGGER;
irq_set.index = irq_info.index; // irq_info.index
irq_set.start = 0;
irq_set.count = 1;
irq_set.evt_fd = eventfd(...);
ioctl(device_fd, VFIO_DEVICE_SET_IRQS, &irq_set);
if (irq_info.flags & VFIO_IRQ_INFO_AUTOMASKED) // irq_info.flags
// set resample eventfd
// ...
// ② 绑定另一 eventfd —— 借助「写 eventfd」来清物理中断
struct {
struct vfio_irq_set hdr;
int evt_fd;
} irq_reset;
irq_reset.argsz = sizeof(irq_reset);
irq_reset.flags = VFIO_IRQ_SET_DATA_EVENTFD | VFIO_IRQ_SET_ACTION_UNMASK;
irq_reset.index = irq_info.index; // irq_info.index
irq_reset.start = 0;
irq_reset.count = 1;
irq_reset.evt_fd = eventfd(...);
ioctl(device_fd, VFIO_DEVICE_SET_IRQS, &irq_reset);
}
- irqfd 相关的配置
struct kvm_irqfd irqfd = {
.fd = trigger_fd, /* 告知物理中断到来的 eventfd */
.gsi = vint, /* 虚拟中断号 */
.flags = KVM_IRQFD_FLAG_RESAMPLE,
.resamplefd = resample_fd, /* 清物理中断的 eventfd */
};
ioctl(vm_fd, KVM_IRQFD, &irqfd);
问题 4:有哪些设备必须要虚拟化?
首先是 GIC,需要拦截 VM 对 Distributor 的访问。
其次是 Timer,确切而言,是与 “现实时间” 相关的 —— Arm 中的 Physical Timer 提供了 Wall-time。
- 与之相对的,Monotonic time 来自 Virtual Timer,虚拟化由硬件支持,故而不需要软件处理。Virtual Timer 会在 VCPU 切出时暂停计时。
其他,例如某些设备需要的 Power 相关配置。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
