

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
天高气爽阅码疾:一日看尽虚拟化(下)
by Chen Jie of TinyLab.org 2020/12/28
回顾
在上一篇中,首先从 Linux Kvm 的编程模型视角,总览了虚拟化工作流。其中,在 VCPU 运行阶段,会因为各种原因,离开虚拟化环境,即 VM_EXIT。
这个过程,就好像运行在用户态的进程,遇到状况会陷入到内核态一样。
那么,哪些状况会造成 VM_EXIT 呢?前篇以 ARMv8 为例,结合 Linux Kvm 代码,进行展开说明。
特别展开说明了:
- 缺页造成的 VM_EXIT,及相关处理过程,由此一窥内存虚拟化
- 中断造成的 VM_EXIT,及相关处理过程,由此一窥中断虚拟化
其中,为获得更真实的观察,上述说明带入了 ARMv8 的一些设定细节:
- 内存虚拟化,面上看到的是 2 Stages 的内存映射。背后还有异常向量表,以及 VM_EXIT 的 Guest → Host 的 World switch。而伴随 VHE 模式,“Worlds” 间的区分就显得更复杂了。
- 中断虚拟化,由 Hypervisor 进行统一物理中断分发(
HCR_EL2.IMO=1)。介绍了三种使用情形下的中断虚拟化:- Host OS 驱动设备。此时在
List Register<N>写入成对的(vINT, pINT)来关联物理中断和虚拟中断,从而 EOI 后者是连带作用前者。需要指出的是这句话中,Host OS 是指「非 VHE」模式下的,即运行在 EL1,仅 部分 KVM 模块的代码 运行在 EL2。 - Guest OS 驱动设备。通过复用 VFIO 框架来将设备透传(Pass-through)给 Guest OS 驱动, 并通过
Maintenance Interrupt来连带 EOI pINT - 虚拟设备
- Host 通过如 Kvmtool、qemu 来虚拟设备
- Guest OS 通过半虚拟化(Para-Virtualization)驱动,来访问之
- 此时,虚拟中断不对应物理中断,所以无需额外处理。
- Host OS 驱动设备。此时在
本篇进一步展开虚拟化后的外设访问 —— 即上述 “2” 和 “3” 中断之外的虚拟化工作:
- Guest OS 驱动设备:复用 VFIO 来进行设备透传(Pass-through)
- 虚拟设备,从而让多个 Guest OS 共享资源:使用 Virtio 框架来实现
与前篇不同,本篇聚焦在软件框架,终于可以忽视 ARMv8 相关的虚拟化知识条目了。
设备透传(Pass-through)给 Guest OS 专用
本节介绍的透传方案,通过 复用 VFIO 框架来实现。
设备透传需处理如下问题:
| 序号 | 问题 |
|---|---|
| 1 | 设备上电初始化 |
| 2 | 设备在 Device Tree 中的 Device Node 信息透传给 Guest OS |
| 3 | 设备中断注入给 Guest OS,及 EOI 过程 |
| 4 | 设备总线上的空间(例如 MMIO)暴露给 Guest OS |
| 5 | DMA 时,需要能让设备访问 Guest OS 中的 DMA Buffer,how? |
其中,问题 1 可能在 Host OS 甚至固件中完成,不作进一步展开。问题 2 可以是 Kvmtool 从 “Host 处全量 DTS” 中摘出并导入(/sys/firmware/devicetree/*)。问题 3 在前篇中已有阐述。
展开问题 4
问题 4,涉及了 VFIO 的 bus driver,常见的 VFIO bus driver 有 vfio-pci 以及 vfio-platform。
下面以 vfio-platform 为例,展开部分伪代码说明:
/**
* 此处伪代码从下述三处提取关键逻辑,拼贴成说明链:
* - https://elinux.org/R-Car/Virtualization/VFIO
* - https://www.kernel.org/doc/Documentation/vfio.txt
* - Qemu VFIO
*
* 首先将设备从 Host OS 总线驱动上解绑,并重新绑定给 vfio-platform
* 下述仅示意,非实际代码
* - echo 0123:abcd > /sys/bus/platform/drivers/foo_driver/unbind
*
* - echo vfio-platform > /sys/bus/platform/devices/0123:abcd/driver_override
* - echo 0123:abcd > /sys/bus/platform/drivers/vfio-platform/bind
*
* 如此操作后,ls -l /sys/bus/paltform/devices/0123:abcd/iommu_group -> /dev/vfio/12
*/
int container_fd = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container_fd, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
int group_fd = open("/dev/vfio/12", O_RDWR);
ioctl(group_fd, VFIO_GROUP_SET_CONTAINER, &container_fd);
/* ^^^^^^^^^^^^^^^^^^^ 层次结构:Container/Group/Device */
/**
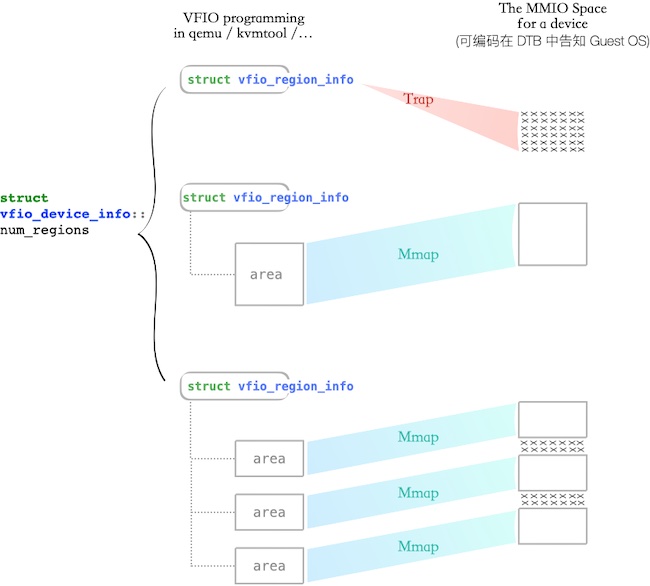
* 拿到 device_fd,进而查询到设备的 MMIO regions,并进行遍历
* 这些 MMIO regions 可分成两类:MMAP-able 和 TRAP access
*/
int device_fd = ioctl(group_fd, VFIO_GROUP_GET_DEVICE_FD, "0123:abcd");
struct vfio_device_info dev_info = { .argsz = sizeof(dev_info) };
ioctl(device_fd, VFIO_DEVICE_GET_INFO, &dev_info);
for (i = 0; i < dev_info->num_regions; i++) { /* 遍历设备的 MMIO regions */
struct vfio_region_info region_info = { .index = i; .argsz = sizeof(region_info); };
ioctl(device_fd, VFIO_DEVICE_GET_REGION_INFO, ®ion_info);
if (region_info.flags & VFIO_REGION_INFO_FLAG_MMAP)
setup_mmaps(...);
else
setup_traps(on_read_trap, on_write_trap, context);
}
如代码,可分成两种类型的空间:
- MMAP:可直接 mmap 成 qemu 进程的虚拟地址(VA),随后将 VA 通过 ioctl
KVM_SET_USER_MEMORY_REGION映射到 Guest OS 的 IPA(Intermediate Physical Address)
struct mapped {
int nr_areas;
struct {
void *ptr;
off_t offset;
size_t size;
} areas[];
};
/**
* 展开前述伪代码中的 setup_mmaps()
*/
bool setup_mmaps(int device_fd, struct vfio_region_info *region_info, struct mapped *m) {
uint32_t flags = region_info->flags;
struct vfio_region_info_cap_sparse_mmap *sparse = NULL;
if (flags & VFIO_REGION_INFO_FLAG_CAPS) { /* sparse mmap regions */
struct vfio_info_cap_header *hdr = \
(uint8_t *) ®ion_info + region_info.cap_offset;
for (; hdr != ®ion_info; hdr = (uint8_t *) hdr + hdr->next)
if (hdr->id == VFIO_REGION_INFO_CAP_SPARSE_MMAP) {
sparse = container_of(hdr, struct vfio_region_info_cap_sparse_mmap, header);
break;
}
}
/**
* 可进一步细分成两子类
* 第一子类:稀疏的、好几个 MMAP-able 空间
*/
if (sparse) {
for (i = 0; i < sparse->nr_areas; i++) {
auto area = &sparse->areas[i];
if (area->size) {
void *ptr = mmap( ... length = area->size,
prot = flags & VFIO_REGION_INFO_FLAG_READ ? PROT_READ : 0 | \
flags & VFIO_REGION_INFO_FLAG_WRITE ? PROT_WRITE : 0,
fd = device_fd,
offset = region_info->offset + area->offset);
m->areas[m->nr_areas].ptr = ptr;
m->areas[m->nr_areas].offset = region_info->offset + area->offset;
m->areas[m->nr_areas].size = area->size;
m->nr_areas++;
}
}
return true;
}
/* 第二子类:一整个 region 都是 MMAP-able */
m->areas[m->nr_areas].ptr = mmap( ... length = region_info->size,
prot = flags & VFIO_REGION_INFO_FLAG_READ ? PROT_READ : 0 | \
flags & VFIO_REGION_INFO_FLAG_WRITE ? PROT_WRITE : 0,
fd = device_fd,
offset = region_info->offset);
return true;
}
- TRAP: Kvm Trap,随后交由 qemu 来处理:
struct trap {
off_t offset;
uint8_t size;
union {
uint8_t u8;
uint16_t u16;
uint32_t u32;
uint64_t u64;
} val;
};
/**
* 展开前述伪代码中的 on_read_trap()。说明如何从 device_fd 中读取相关信息
*/
bool on_read_trap(int device_fd, struct vfio_region_info *region_info, struct trap *trap) {
return pread(device_fd, &trap->val, trap-size, region_info->offset + trap->offset) == trap->size;
}
本节最末,用一图说明两类空间,是如何让 Guest OS 访问到的:
展开问题 5
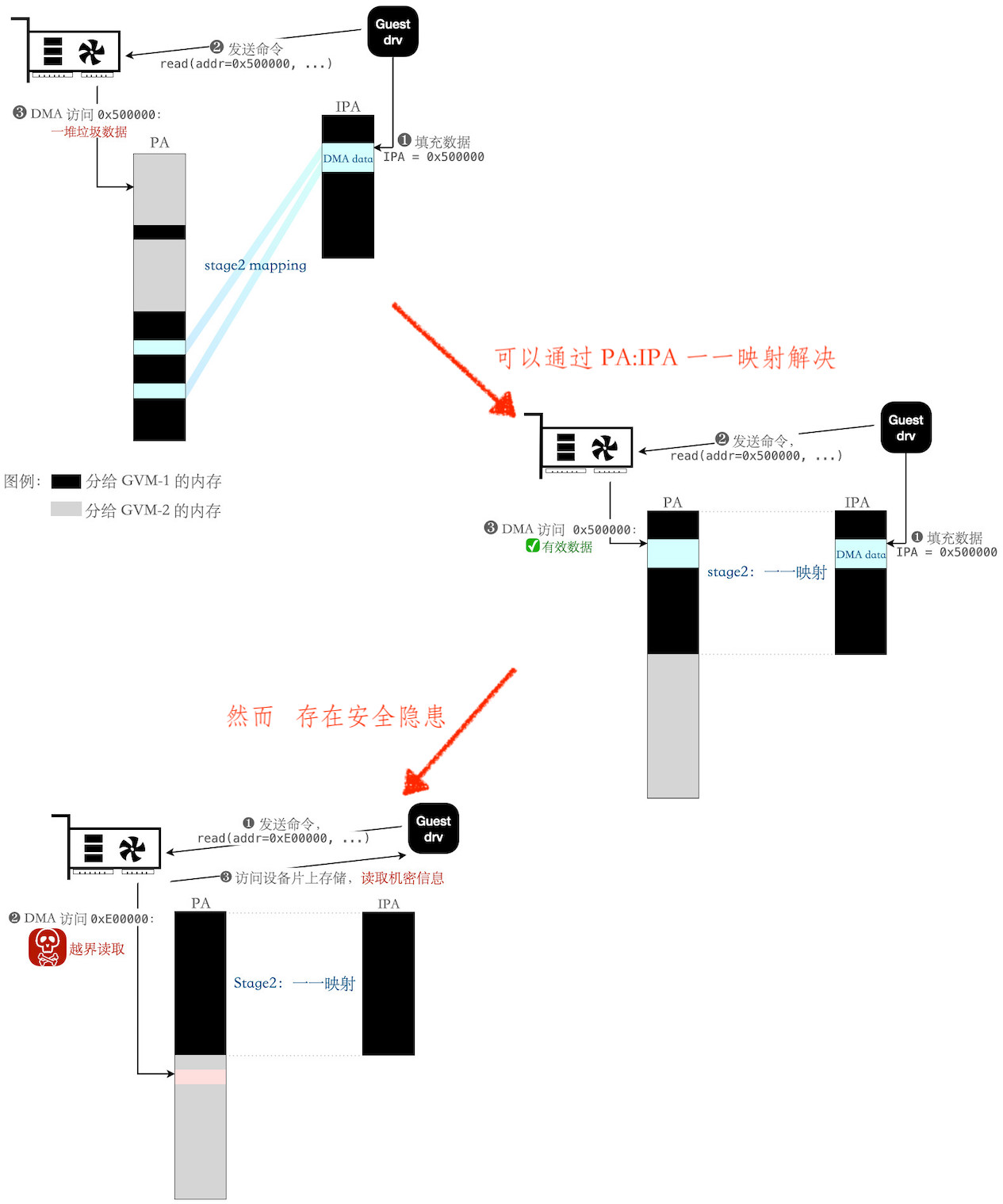
对问题进行初步沙盘推演,考虑 Guest Drv 填充数据,让 Device 来 DMA 读取:
- 原始问题:DMA 命令中,访问的地址为 IPA。但 Device 直接将 IPA 当成 PA 进行访问,于是访问了错误的地址
- 解决方案一:目标虚拟机配置内存时,特意让 PA 和 IPA 形成一一映射,这样 Device 就能正确访问到数据了
- 安全隐患:上述方案中,Guest Drv 可以恶意填入出圈的 IPA。借由 Device DMA(可直接访问 PA),以 Device 为跳板,越界访问
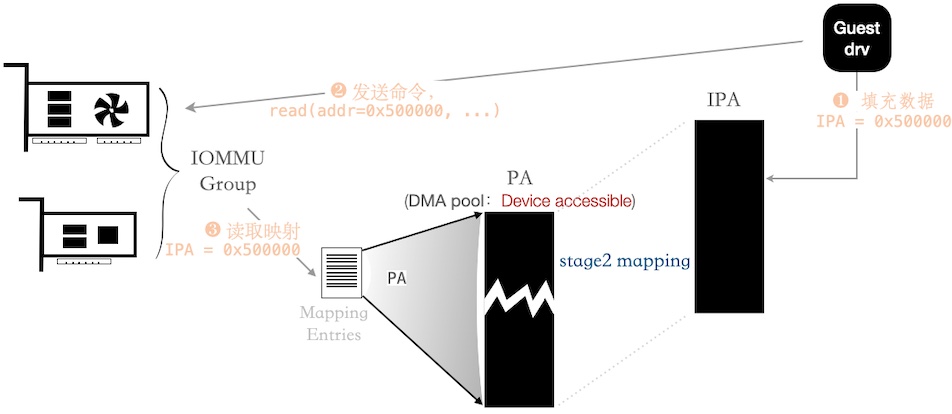
一个 IOMMU group 包含若干个设备,通过配置 映射表项 ,限制设备只能访问指定范围内的 PA。
而对于基于 VFIO 的 设备透传 场景中,可限制为 Guest 名下的全部内存。
上述过程,对照到 Kvmtool 中的关键代码如下:
/**
* 此处伪代码从下述三处提取关键逻辑,拼贴成说明链:
* - https://elinux.org/R-Car/Virtualization/VFIO
* - https://www.kernel.org/doc/Documentation/vfio.txt
* - Qemu VFIO
*
* 首先将设备从 Host OS 总线驱动上解绑,并重新绑定给 vfio-platform
* 下述仅示意,非实际代码
* - echo 0123:abcd > /sys/bus/platform/drivers/foo_driver/unbind
*
* - echo vfio-platform > /sys/bus/platform/devices/0123:abcd/driver_override
* - echo 0123:abcd > /sys/bus/platform/drivers/vfio-platform/bind
*
* 如此操作后,ls -l /sys/bus/paltform/devices/0123:abcd/iommu_group -> /dev/vfio/12
*/
int container_fd = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container_fd, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
int group_fd = open("/dev/vfio/12", O_RDWR);
ioctl(group_fd, VFIO_GROUP_SET_CONTAINER, &container_fd);
/* ^^^^^^^^^^^^^^^^^^^ Attach 到 container 上
* 层次结构:Container/Group/Device
*/
/**
* 注意!注意!注意!
* 对 IOMMU 设定,都以 Container 为单位进行的 (Kvmtool: vfio/core.c, vfio_container_init())
*/
int container_fd = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container_fd, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
int iommu_type = -1;
if (ioctl(container_fd, VFIO_CHECK_EXTENSION, VFIO_TYPE1v2_IOMMU))
iommu_type = VFIO_TYPE1v2_IOMMU;
else if (ioctl(container_fd, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU)
iommu_type = VFIO_TYPE1_IOMMU;
if (iommu_type < 0)
/* Unsupported IOMMU type */
ioctl(container_fd, VFIO_SET_IOMMU, iommu_type);
list_for_each_entry(mem_bank, &Guest_VM->mem_banks, list) {
if (is_not_ram(mem_bank))
continue;
/* 进行 IOMMU mapping 设定 */
struct vfio_iommu_type1_dma_map dma_map = {
.argsz = sizeof(dma_map);
.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE,
.vaddr = (unsigned long) mem_bank->host_addr, /* Guest 内存,对应到 Qemu 的 VA */
.iova = (uint64_t) mem_bank->guest_phys_addr, /* GPA (即 Guest VM 的 IPA) */
.size = mem_bank->size,
};
ioctl(container_fd, VFIO_IOMMU_MAP_DMA, &dma_map);
}
小结
在本系列前篇,中断虚拟化一节,提及了 基于 VFIO 的设备透传 的中断处理。
本节进一步介绍了 VFIO 框架下,设备 MMIO 空间和 IOMMU 的编程模型。
下图小结下 VFIO 诸个 ioctl(s):
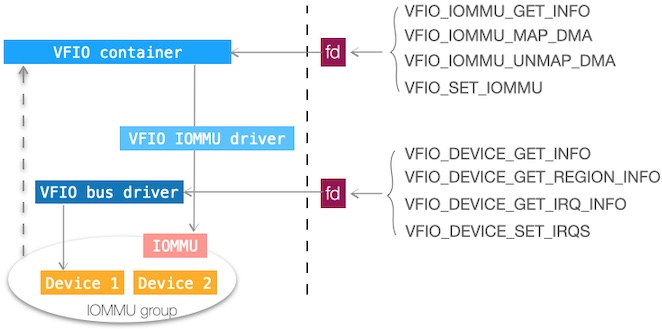
图:VFIO ioctl(s) 一览,修改自「Platform Device Assignment to KVM-on-ARM Virtual Machines via VFIO」一文
虚拟设备,从而让多个 Guest OS 共享资源
最常见的方案是基于 Virtio 框架实现的。即便不算厂商实现的、Out-of-tree 的 Virtio 虚拟设备,光 Linux kernel 主线已包含许多 Virtio 设备,如下图:
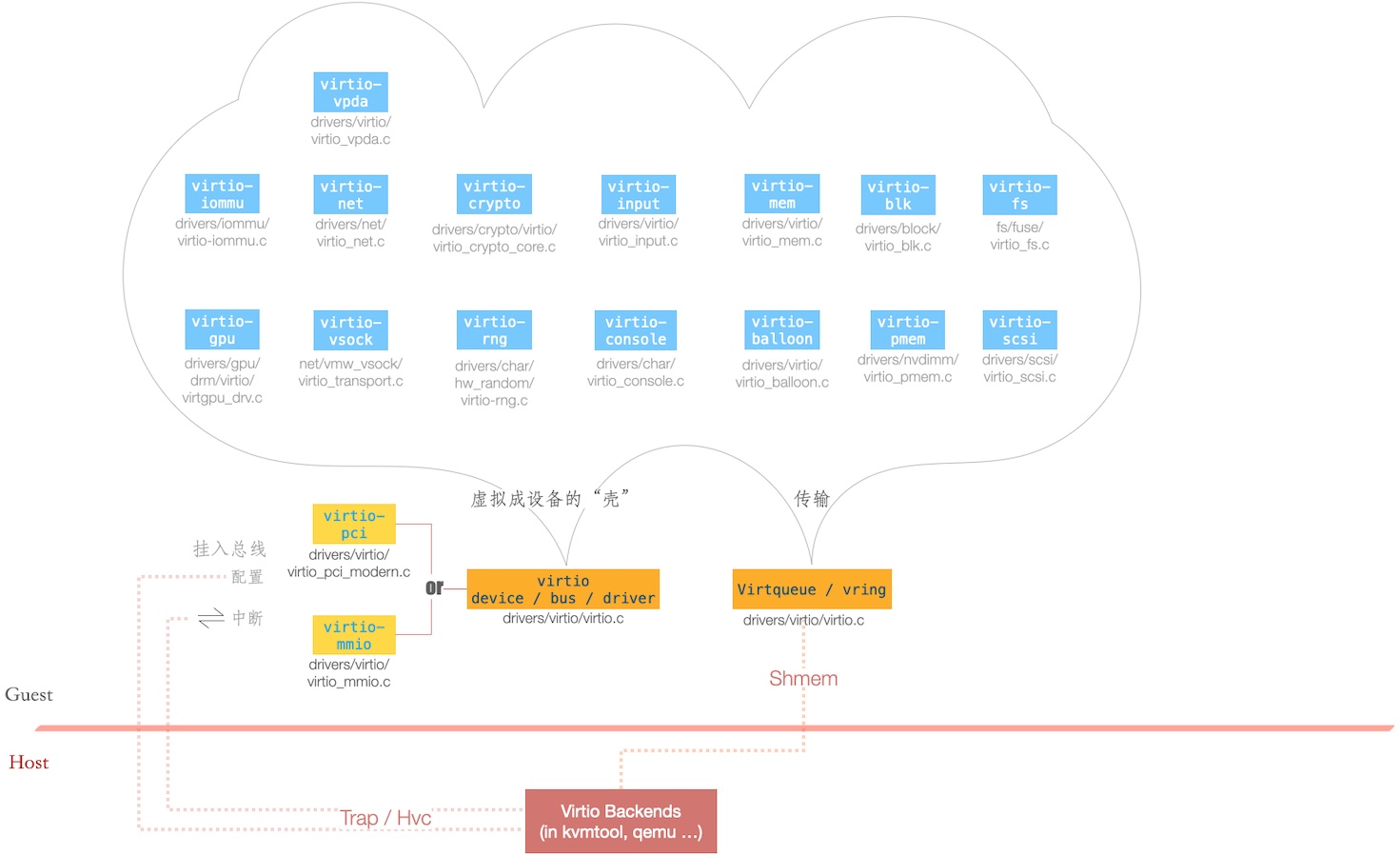
图中部分 virtio 设备简介如下:
| 虚拟设备 | 简介 |
|---|---|
| virtio-net | - 实现了 Guest 和 Host 的联网 - 借助 Host 的路由,可以进一步连接互联网 |
| virtio-sock | - Guest 和 Host 的 “unix domain socket” - 但目前不能传输 fd |
| virtio-balloon | - Guest 和 Host 的内存协商通道 - 动态增减 Guest 的内存大小 |
| virtio-blk | - 将镜像文件或块设备,虚拟成块设备给 Guest |
| virtio-fs | - 在 Guest 处,以 FUSE 接口,导出成文件系统 - 通过 Virtio 传输通道(virtqueue / vring),对接到 Host 文件系统的某个目录 |
| virtio-gpu | - 将图形显示和渲染,对接到 Host - 图形渲染时, 命令流入 Qemu 中的一个 Virgl 实例,后者可视为状态机,并提交实际渲染命令 |
这些设备,或挂入 PCI,或挂入 MMIO,成为设备,为 Guest OS 所发现、配置、及“双向” 中断。
而数据传输部分,则基于共享内存的队列(Virtqueue / vring)。
什么是 Virtio?以 virtio-net 为例
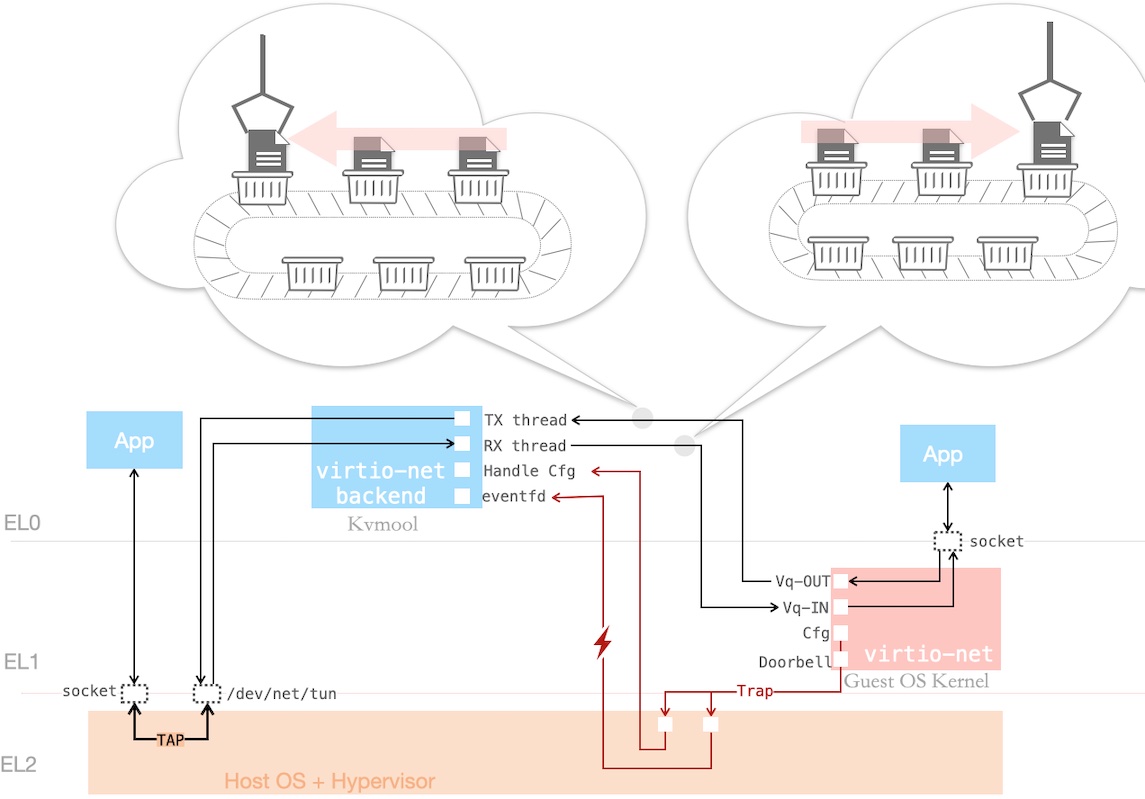
下图简示了 virtio-net 的工作流:
- 对于位于 Host 和 Guest 的 App 而言,只是个普通的、socket 网络通信过程
- 其中,Guest 处是走了 virtio-net 这个 虚拟网卡
- 而 Host 处,则通过 Linux Kernel 的 Tap 设备,允许用户态进程(Kvmtool)注入网络包,并被其他进程通过网络接口(例如
tap0)收到
- 位于 Kvmtool 的 virtio-net backend,和 virtio-net drv 有 3 类数据流 —— 配置流 / 中断通知流 / 传输流(Vq-OUT 和 Vq-IN)
配置流
假定 virtio-net 挂在 MMIO,Kvmtool 对配置空间的读 & 写均进行 Trap。
这个 MMIO 空间由 virtio_mmio_hdr 所表述:
struct virtio_mmio_hdr {
...
u32 queue_sel; /* 选定某个 virtqueue,并随后设置 queue 长度等 */
u32 queue_num; /* vq 的长度;常见由 Kvmtool 决定;Guest virtio drv 来接受决定 */
...
u32 queue_pfn; /* vq 所在的 pfn(page frame number),即 (IPA >> PAGE_SHIFT) */
...
u32 queue_notify; /* Guest 的 virtio-net drv 写 MMIO 空间
* - 偏移为:VIRTIO_MMIO_QUEUE_NOTIFY (0x50)
* - 写入值为:vq sel
* 告知选定的 vq 有变化。类似 doorbell register */
} __attribute__((packed));
中断通知流
中断形式的通知,分成两个方向:
方向 Host → Guest,由 Kvmtool 通过
KVM_IRQ_LINE注入 边缘触发型中断 ,详见前篇 5.2 一节。方向 Guest → Host
- 如上一节所提及,通过写 MMIO 空间,
offset = 0x50,Trap 后转解释为中断,为 Kvmtool 所获悉 - 类似 doorbell register
- 通常 Trap 处理,需要 Kvmtool 来介入,这样就牵扯太多上下文,造成过长等待,对此 Kvm 引入了 ioevent 机制
- 如上一节所提及,通过写 MMIO 空间,
// 当对 @io_addr 写入值 @datamatch 时 —— Kvm 写 eventfd 来通知 Qemu / Kvmtool / ...
struct kvm_ioeventfd ioevent = {
.io_addr = mmio_start + VIRTIO_MMIO_QUEUE_NOTIFY,
.io_len = sizeof(u32),
.datamatch = vq_sel,
/**
* 特别留意这是第 N 次,eventfd 在 Kvm 虚拟化中出场了,为何它如此圈粉?
* - eventfd 本身较简单 —— 可以用在 interrupt handler 中
* - fd 可以在进程间传递 —— 从而让通知的源头,直达最终的接收方
*/
.fd = eventfd(0, 0)
};
ioctl(vm_fd, KVM_IOEVENTFD, &ioevent);
传输流
基于共享内存的 Virtqueue / vring 构成了 virtio 设备的传输流。图中展示了 virtio-net 某对双向的传输通道:Vq-OUT 和 Vq-IN。
留意:
- OUT 和 IN 是从 virtio-net drv 的视角
- 对应到 Kvmtool 实现,OUT 对应 TX;IN 对应 RX
另外,图中以 “传送带” 来类比一个 Virtqueue / vring:
| 图中形象 | 类比 | 细节 |
|---|---|---|
| 篮筐中的文件 | 网络的一帧(frame) - 并在前头添加一个 virtio-net 定义的头 | 对于 Vq-OUT: - 这一帧随后被写入到 Tap 设备 - 完成一个桥接 对于 Vq-IN: - 来自 Tap 设备的一帧,塞入 Vq-IN - 随后上抛到 Guest OS 之网络协议栈 - 同样完成一个桥接 |
| 篮筐 | 容纳网络帧的 buffer - 由 Guest OS 分配 | 对于 Vq-OUT: - 填入 payload 后,共享给 Kvmtool 来处理 对于 Vq-IN - 预先共享一组给 Kvmtool - 后者填入 payload 返回 |
| 传送带本身 | vring - 一个建立在共享内存的 “对象池” 和 ringbuffer | 其中,共享内存的 guest 端地址(IPA),由前面小节的 queue_pfn 所指出
|
考虑一个实现细节,内存共享如何实现?有两个关键:
- 所有共享的内存,由 Guest OS 侧分配。
- Kvmtool 能够访问全部 Guest OS 的内存,这是因为:
- 添加给 Guest 的内存,是 Kvmtool 分配的 Buffer(s)(一段或几段 VA 连续的 buffers;VA 和 IPA 线性映射)
- 参见前篇 ioctl
KVM_SET_USER_MEMORY_REGION
本小节最后,来展开下 vring,如下图:
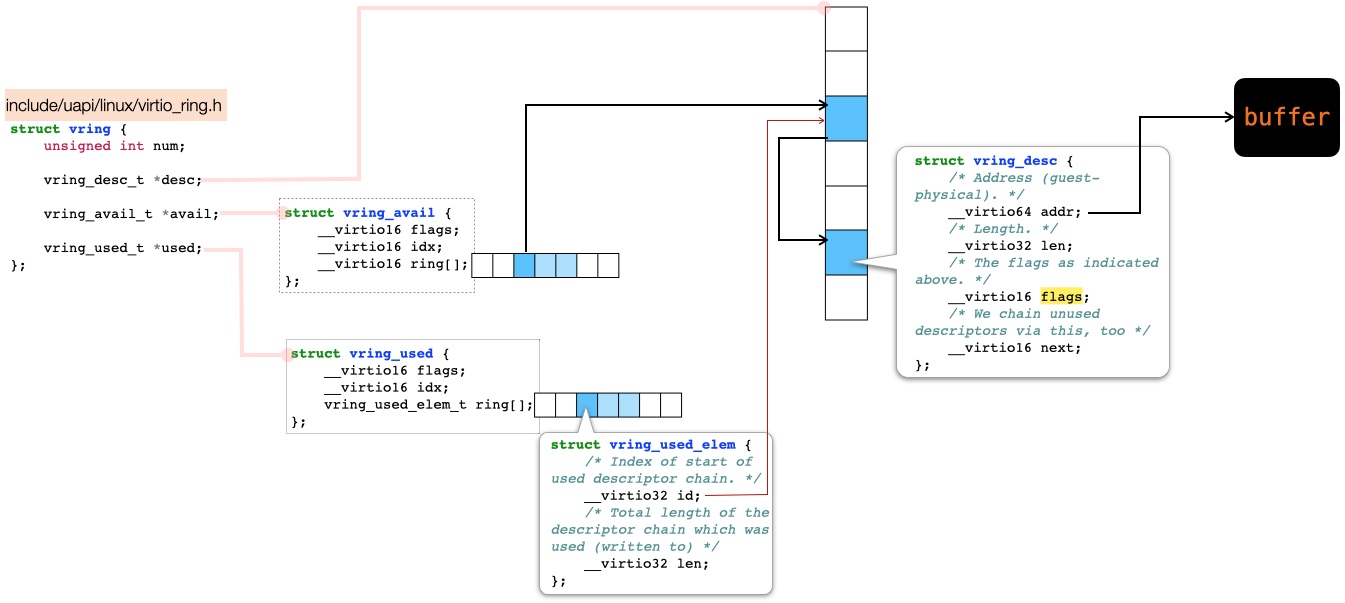
它有三个重要的域:
desc:vring_desc 的数组,构成一个“对象池”,留意:- vring_desc 是一个“链表”结构(留意 next 是一个 index 而非指针)
- 一个 buffer 可被分成多个 vring_desc,构成 Scatter-Gather I/O
- 称之为“对象池”,是因为它指向了实际的 buffer,并被
avail和used所引用(分别对应分配和释放)
avail:“指针数组” —— 指向分配给 Kvmtool 来使用的 buffers- 可以有(或没有)有效的 payload
- 留意共享内存情形下,不能淳朴地用“指针”,而是要用 index (
desc的 index) - 这个 avail 命名,大概是从 resource allocator 的语境来命名的
used:“指针数组” —— 指向释放归还给 virtio-net 的 buffers- 可以有(或没有)有效的 payload
- “指针” 首先指向一个
struct vring_used_elem,最终通过 index(desc的 index)指向 buffer - 填入数据的长度为
vring_used_elem::len
为进一步说明,下面再附上一个 virtio drv 的使用示例:
/**
* Vq-OUT:
* 展示一个 rpc 风格的通信,ret = invoke(my_rpc)
*/
void do_rpc() {
struct my_rpc *rpc = kzalloc(sizeof(struct my_rpc), GFP_KERNEL);
/**
* fill rpc:
* - rpc->cmd = ...;
* - rpc->arg0 = ...;
*/
struct completion finish_completion;
struct scatterlist out_sg;
struct scatterlist in_sg;
struct scatterlist *sgs[] = { &out_sg, &in_sg };
sg_init_once(&out_sg, rpc, sizeof(*rpc));
sg_init_once(&in_sg, rpc, sizeof(*rpc));
init_completion(&finish_completion)
/**
* 下面这个调用,添加了两个 descs:
* vring_avail::ring[idx] ---> desc-A ---> desc-B
*
* 其中,
* - desc-A 对应 OUT,即让 Kvmtool 来处理的命令
* - desc-B 对应 IN,即让 Kvmtool 来填写返回值
* 从而构成一个 RPC。
*
* 留意:
* - desc-A 和 desc-B 指向了同一块内存 @rpc
* - 可以 attach 一个不相干的 buffer
* 这是因为内部保存了一个 index 和 attached buffer 的关联
* 并在返回时,返回 attached buffer
*/
virtqueue_add_sgs(vq /* struct virtqueue */, sgs,
1 /* @sgs 中有 1 个 out_sg */,
1 /* @sgs 中有 1 个 in_sg */,
&finish_completion /* attach buffer */, GFP_KERNEL);
wait_for_completion(&finish_completion);
/* Process rpc->ret_val */
kfree(rpc);
}
/**
* 另一个线程中,接收 Kvmtool 返回值,并 complete(finish_completion)
*/
void handle_retval_thread()
{
for (;;) {
unsigned len;
struct completion *finish_completion = \
virtqueue_get_buf(vq /* struct virtqueue */, &len);
if (finish_completion)
complete(finish_completion);
}
}
vhost-net 加速
部分 virtio 设备,有对应的 vhost-* 加速路径。例如 virtio-net 有名为 vhost-net 的加速路径,如下图所展示:
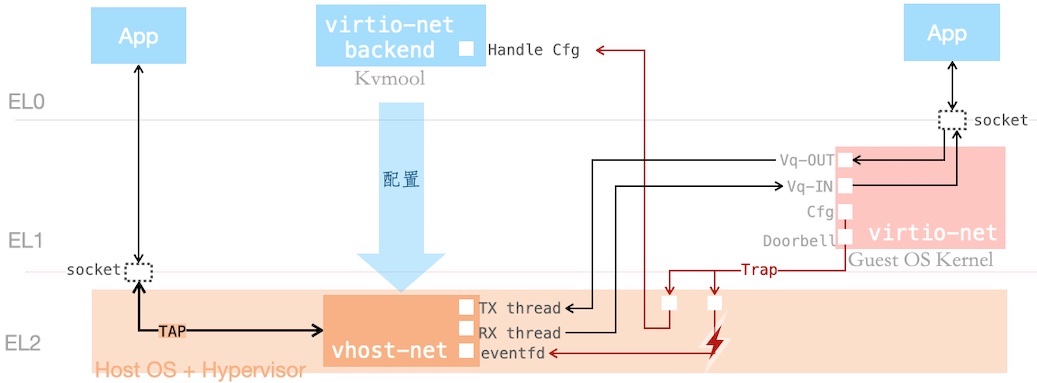
加速后,桥接的数据流略过 Kvmtool,直接在 Kernel 内部模块间流转。
其中 Kvmtool 仅负责 vhost-net 配置,相关的 ioctl(s) 如下:
// Step 1:打开 vhost-net,virtio_net__vhost_init()
vhost_fd = open("/dev/vhost-net", O_RDWR);
// Step 2:进行配置
// 2.1 将 guest 内存,登记给 vhost-net 模块,使之可全权访问
struct vhost_memory_region guest_mems[N];
guest_mems[0].guest_phys_addr = ...;
guest_mems[0].memory_size = ...;
guest_mems[0].userspace_addr = ...; /* Kvmtool 视角下的 VA */
...
ioctl(vhost_fd, VHOST_SET_OWNER);
ioctl(vhost_fd, VHOST_SET_MEM_TABLE, guest_mems);
// 2.2 配置 device features, virtio_net__vhost_set_features()
ioctl(vhost_fd, VHOST_SET_FEATURES, &features);
// 2.3 配置 virtqueue 地址、长度, init_vq()
struct vhost_vring_state state = {
.index = vq_sel,
.num = vq_num /* virtqueue 长度 */
};
ioctl(vhost_fd, VHOST_SET_VRING_NUM, &state);
state.num = 0;
ioctl(vhost_fd, VHOST_SET_VRING_BASE, &state);
struct vhost_vring_addr addr = {
.index = vq_sel,
.desc_user_addr = /* Kvmtool 视角下的 VA,下同 */
.avail_user_addr = ...
.used_user_addr = ...
};
ioctl(vhost_fd, VHOST_SET_VRING_ADDR, &addr);
// 2.4 配置 doorbell 通知链路,notify_vq_eventfd()
struct vhost_ring_file file = {
.index = vq_sel,
.fd = ioevent_fd
};
ioctl(vhost_fd, VHOST_SET_VRING_KICK, &file);
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
