

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
RISC-V Syscall 系列 2:Syscall 过程分析
Author: envestcc chen1233216@hotmail.com Date: 2022/06/22 Revisor: Falcon, dlan17 Project: RISC-V Linux 内核剖析 Sponsor: PLCT Lab, ISCAS
概述
本文主要对 Linux 在 RISC-V 架构下的 Syscall 机制进行分析,探究计算机是如何一步一步从应用程序开始,到执行 Syscall,最后返回应用程序的全过程。
文章因涉及技术术语,建议读者阅读本文前先熟悉以下知识:
- Syscall 概念
- RISC-V 规范
- C 语言
说明:文中涉及的 Linux 源码是基于 5.17 版本
Syscall 开始
首先,Syscall 是如何开始的呢?当应用程序需要使用操作系统提供的一系列功能时,一般会通过操作系统提供的 C 标准库来进行 Syscall 的调用。而实际上,C 标准库的内部则使用了 ecall 指令来触发了整个 Syscall 流程。
ecall
先介绍一下 ecall 指令。ecall 指令以前叫做 scall,用于执行环境的变更,它会根据当前所处模式触发不同的执行环境切换异常:
- in U-mode: environment-call-from-U-mode exception
- in S-mode: environment-call-from-S-mode exception
- in M-mode: environment-call-from-M-mode exception
Syscall 场景下是在 U-mode(用户模式)下执行 ecall 指令,主要会触发如下变更:
- 处理器特权级别由 User-mode(用户模式)提升为 Supervisor-mode(内核模式)
- 当前指令地址保存到
sepc特权寄存器 - 设置
scause特权寄存器 - 跳转到
stvec特权寄存器指向的指令地址
简单来说,ecall 指令将权限提升到内核模式并将程序跳转到指定的地址。操作系统内核和应用程序其实都是相同格式的文件,最关键的区别就是程序执行的特权级别不同。所以 Syscall 的本质其实就是提升特权权限到内核模式,并跳转到操作系统指定的用于处理 Syscall 的代码地址。
调用参数和返回值约定
ecall 指令规范中没有其他的参数,Syscall 的调用参数和返回值传递通过遵循如下约定实现:
- 调用参数
a7寄存器存放系统调用号,区分是哪个 Syscalla0-a5寄存器依次用来表示 Syscall 编程接口中定义的参数
- 返回值
a0寄存器存放 Syscall 的返回值
Syscall 入口
ecall 跳转的地址是哪儿呢?根据 ecall 指令描述,stvec 寄存器存放的就是跳转的目标地址。下面通过代码看看 stvec 寄存器设置的值,以及设置的时机:
// arch/riscv/kernel/head.S
setup_trap_vector:
/* Set trap vector to exception handler */
la a0, handle_exception
csrw CSR_TVEC, a0 // 将异常处理函数地址设置到 stvec 寄存器
// arch/riscv/include/asm/csr.h
#define CSR_STVEC 0x105
#define CSR_TVEC CSR_STVEC
从上述代码可以看出,stvec 寄存器被设置成了 handle_exception 的地址,故 ecall 指令执行后会跳转到 handle_exception。而且 arch/riscv/kernel/head.S 是操作系统初始化时运行的代码,所以操作系统在启动时就配置了好 ecall 的跳转地址。
handle_exception
handle_exception 不止是作为 Syscall 调用进入内核的入口,也是整个 trap(transfer of control to a trap handler) 机制的入口。从下面简单的描述中可以看出 Syscall 其实是 trap 机制的一个应用场景。
- trap
- exceptions
- Load access fault
- Environment call from U-mode (Syscall)
- …
- interrupts
- exceptions
接下来一起探究一下 handle_exception 的代码。因 trap 本身涉及的内容也比较多,但本篇文章主要聚焦于其中跟 Syscall 相关的,所以为了更清晰地展示 Syscall 流程,下文中的代码经过删减,只保留了 Syscall 相关的部分,删减的部分会用 ... 来标识。大概是因为这部分功能需要访问寄存器,所以主要语言是汇编代码。为了降低阅读障碍,请先熟悉 RISC-V 汇编语言。
// arch/riscv/kernel/entry.S
ENTRY(handle_exception)
/*
* If coming from userspace, preserve the user thread pointer and load
* the kernel thread pointer. If we came from the kernel, the scratch
* register will contain 0, and we should continue on the current TP.
*/
csrrw tp, CSR_SCRATCH, tp
bnez tp, _save_context
_restore_kernel_tpsp:
csrr tp, CSR_SCRATCH
REG_S sp, TASK_TI_KERNEL_SP(tp)
...
_save_context:
REG_S sp, TASK_TI_USER_SP(tp)
REG_L sp, TASK_TI_KERNEL_SP(tp)
addi sp, sp, -(PT_SIZE_ON_STACK)
REG_S x1, PT_RA(sp)
REG_S x3, PT_GP(sp)
REG_S x5, PT_T0(sp)
REG_S x6, PT_T1(sp)
...
REG_S x30, PT_T5(sp)
REG_S x31, PT_T6(sp)
li t0, SR_SUM | SR_FS
REG_L s0, TASK_TI_USER_SP(tp)
csrrc s1, CSR_STATUS, t0
csrr s2, CSR_EPC
csrr s3, CSR_TVAL
csrr s4, CSR_CAUSE
csrr s5, CSR_SCRATCH
REG_S s0, PT_SP(sp)
REG_S s1, PT_STATUS(sp)
REG_S s2, PT_EPC(sp)
REG_S s3, PT_BADADDR(sp)
REG_S s4, PT_CAUSE(sp)
REG_S s5, PT_TP(sp)
首先交换了 tp 和 sscratch 寄存器的内容。tp 存储的是用户线程地址,sscratch 内容分以下两种情况:
- 从用户态进入时:存储的是内核线程栈地址
- 从内核态进入时:存储的是 0
如果从内核态进入,则会往下继续执行 _restore_kernel_tpsp,保存内核栈地址,然后再执行 _save_context;如果是从用户态进入,则会直接进入 _save_context。Syscall 都是从用户态进入,因此会跳转到 _save_context。
_save_context 主要是进行用户态到内核态的上下文切换。首先是保存了用户栈地址,并切换成了内核栈地址。然后在内核栈开辟空间,存储除 x0 之外的 31 个通用寄存器以及 sstatuc、sepc、stval、scause、sscratch 这 5 个 csr 寄存器。因为触发 trap 的原因有很多,所以接下来的代码逻辑就是根据触发 trap 的原因,找到各自对应的处理方法执行。
// arch/riscv/kernel/entry.S
bge s4, zero, 1f
/* Handle interrupts */
...
1:
...
/* Handle syscalls */
li t0, EXC_SYSCALL
beq s4, t0, handle_syscall
// arch/riscv/include/asm/csr.h
#define EXC_SYSCALL 8
因为此时 s4 存储的是 scause 的值,表示了 trap 的原因。scause 寄存器最高位含义如下:
- 最高位=1:interrupts
- 最高位=0:exceptions
所以 s4>=0 表示本次 trap 是由某个 exception 触发,反之是由某个 interrupt 触发。所以这里会继续跳转到 1f。
接着判断 s4 如果和 EXC_SYSCALL 相等,则跳转到 handle_syscall。实际上这里是在根据 exception code 判断 trap 的原因是否是 Syscall。当 scause==8 时,就表示由 Syscall 触发的 trap(具体 scause 值的含义可以参考文章末尾 scause 寄存器介绍部分),故这里会跳转到 handle_syscall。
handle_syscall
接下来就到 handle_syscall 部分,它用于找到对应的实际处理 Syscall 的代码并跳转执行。这段代码分为两部分:
- 汇编部分:用于跳转到 Syscall 实现的代码
- C 语言:实现具体的 Syscall 函数
汇编语言部分
// arch/riscv/kernel/entry.S
handle_syscall:
...
addi s2, s2, 0x4
REG_S s2, PT_EPC(sp)
...
check_syscall_nr:
/* Check to make sure we don't jump to a bogus syscall number. */
li t0, __NR_syscalls
la s0, sys_ni_syscall
/*
* Syscall number held in a7.
* If syscall number is above allowed value, redirect to ni_syscall.
*/
bgeu a7, t0, 1f
/* Call syscall */
la s0, sys_call_table
slli t0, a7, RISCV_LGPTR
add s0, s0, t0
REG_L s0, 0(s0)
1:
jalr s0
ret_from_syscall:
...
首先将 s2 加 4 并保存到用于存储用户态 sepc 寄存器的地方。实际上就是将 Syscall 返回到用户态的地址加 4 字节。上文在介绍 ecall 时提到 ecall 指令执行时会将当前指令(ecall)的地址保存到 sepc,而 RISC-V 指令长度是 4 字节,加 4 之后就指向了下一条指令地址,这也正是 Syscall 调用完返回期望的结果。
这里可能有人会有疑问,那为什么不在一开始就将 sepc 设置为加 4 之后的地址呢?这其实还是要回到 Syscall 是依赖 trap 机制的一个使用场景,而 trap 的触发原因分为 exceptions 和 interrupts。一般来说触发 exception 后表示指令执行异常,经过 trap handler 后希望重新执行该指令达到正常结果,所以因 exception 触发的 trap 时 sepc 都设置为触发异常的指令地址。
接下来会校验系统调用号的合法性。__NR_syscalls 表示系统调用的数量,sys_ni_syscall 是返回系统调用不存在的处理函数。本次 Syscall 的系统调用号存储在 a7 中,当 a7 < __NR_syscalls 时才会进入对于系统调用的入口,否则跳转到 sys_ni_syscall。相关定义代码如下。
// include/uapi/asm-generic/unistd.h
#define __NR_syscalls 451
// kernel/sys_ni.c
/*
* Non-implemented system calls get redirected here.
*/
asmlinkage long sys_ni_syscall(void)
{
return -ENOSYS;
}
sys_call_table 是一个函数指针数组,存储的是每个系统调用号对应的处理函数地址。例如 sys_call_table[n] 表示的系统调用号为 n 的 Syscall 处理函数地址。
RISCV_LGPTR 宏的定义如下:
- 在 64 位处理器中,定义是 3
- 在 32 位处理器,定义是 2
所以这里跳转的地址就相当于是 sys_call_table[a7]。另外 jalr 伪指令除了跳转外,会执行 ra=pc+4,因此当 sys_call_table[a7] 执行完后会返回到 ret_from_syscall 处。
// arch/riscv/include/asm/syscall.h
/* The array of function pointers for syscalls. */
extern void * const sys_call_table[];
// arch/riscv/include/asm/asm.h
#if __SIZEOF_POINTER__ == 8
#define RISCV_LGPTR 3
#elif __SIZEOF_POINTER__ == 4
#define RISCV_LGPTR 2
C 语言部分
那实际的 Syscall 处理函数在哪儿呢?这就得先看看 sys_call_table 是如何定义和初始化的。这里就是使用 C 语言实现的部分。
// arch/riscv/kernel/syscall_table.c
#define __SYSCALL(nr, call) [nr] = (call),
void * const sys_call_table[__NR_syscalls] = {
[0 ... __NR_syscalls - 1] = sys_ni_syscall,
#include <asm/unistd.h>
};
以上代码展示了 sys_call_table 定义为一个函数指针数组,数组长度为 __NR_syscalls,默认所有函数都指向 sys_ni_syscall。而实际系统调用号和函数的映射关系通过头文件的方式定义。头文件 asm/unistd.h 最终包含了 include/uapi/asm-generic/unistd.h 头文件,这个文件里面定义了具体每个系统调用号对应哪个处理函数。下面是 write 系统调用的声明示例。
// include/uapi/asm-generic/unistd.h
/* fs/read_write.c */
#define __NR_write 64
__SYSCALL(__NR_write, sys_write)
从这里可以看出,write 的系统调用号为 64,对应的处理函数是 sys_write。那 sys_write 的实现在哪儿呢?一开始搜遍了也没找到它的函数实现,后来发现是原来是用宏实现的。具体代码如下:
// fs/read_write.c
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
...
}
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
实际上是 SYSCALL_DEFINE3 宏里面会定义一个 sys_write 的函数。具体 SYSCALL_DEFINE3 宏的定义代码如下:
// include/linux/syscalls.h
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
__diag_push(); \
__diag_ignore(GCC, 8, "-Wattribute-alias", \
"Type aliasing is used to sanitize syscall arguments");\
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(__se_sys##name)))); \
ALLOW_ERROR_INJECTION(sys##name, ERRNO); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__));\
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__));\
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
__diag_pop(); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__))
从上述代码中可以看出,SYSCALL_DEFINE3 宏主要做了如下几件事:
- 给
sys_write定义别名__se_sys_write - 定义函数
__se_sys_write,函数里调用__do_sys_write并返回 - 在
SYSCALL_DEFINE3下面定义的实际函数名为__do_sys_write
所以最后通过宏的方式定义了 sys_write 函数。那为什么要这么麻烦呢?直接定义 sys_write 不行吗?这里涉及 Linux 以前的一个漏洞 CVE-2009-0029。感兴趣可以看看 Linux Kernel 代码艺术——系统调用宏定义,这篇文章里介绍了 SYSCALL_DEFINE3 宏的展开以及 CVE-2009-0029 漏洞,本文就不展开解释了。
ret_from_syscall
在 handle_syscall 里跳转到实际的系统调用函数时把返回地址设置成了 ret_from_syscall。所以上述的 sys_write 函数返回后会跳转到 ret_from_syscall 继续执行。下面看看这部分代码。
// arch/riscv/kernel/entry.S
ret_from_syscall:
// 将系统调用的返回值 a0 更新到用户态线程的上下文中
REG_S a0, PT_A0(sp)
...
// 释放内核栈内存
addi s0, sp, PT_SIZE_ON_STACK
REG_S s0, TASK_TI_KERNEL_SP(tp)
// 恢复用户态线程栈上下文
REG_L a0, PT_STATUS(sp)
REG_L a2, PT_EPC(sp)
REG_SC x0, a2, PT_EPC(sp)
csrw CSR_STATUS, a0
csrw CSR_EPC, a2
REG_L x1, PT_RA(sp)
REG_L x3, PT_GP(sp)
...
REG_L x31, PT_T6(sp)
REG_L x2, PT_SP(sp)
// 返回用户态
sret
从以上代码可以看出,返回用户态程序过程中主要做以下几件事:
- 将系统调用的返回值 a0 更新到用户态线程的上下文中的 a0
- 释放内核栈内存
- 恢复用户态线程栈上下文信息,包括通用寄存器以及 sstatus 和 sepc 寄存器。
- 执行
sret指令返回到用户态
sret 指令用来从 trap 机制中返回。sret 指令会执行如下操作:
- 将当前处理器特权级别设置为 sstatus.SPP;
sstatus.SPP = U sstatus.SIE = sstatus.SPIE; sstatus.SPIE = 1pc = sepc
也就是说 sret 指令将处理器从内核模式切换到用户模式,并恢复中断的状态,然后跳转到进入 Syscall 时用户线程的下一条指令地址。至此,整个 Syscall 的过程就完成了。
总结
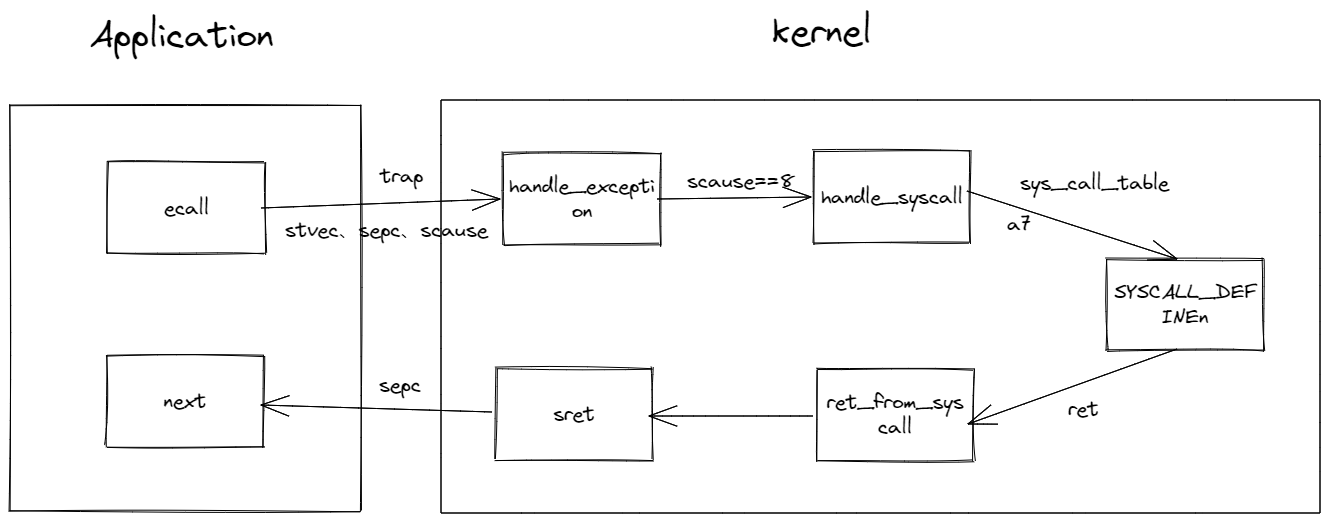
本文详细描述了从应用程序触发 Syscall 开始,到 trap 机制执行,再到 Syscall 实际处理函数,最后返回到应用程序的全过程。整个过程没有复杂的数据结构和算法,关键是理解这个流程机制,其中主要涉及的关键有以下几点:
- ecall:进入比当前级别更高的特权级,针对应用程序,就是进入内核模式
- trap:用户态和内核态切换时的处理逻辑
- SYSCALL_DEFINE3:定义 Syscall 处理函数
- sret:返回进入前的特权级别,这里就是返回用户模式
只要理解了这些,整个 Syscall 过程还是比较简单的。
Syscall 相关特权寄存器
stvec (Supervisor Trap Vector Base Address Register)
用户保存发送异常时处理器需要跳转到的地址


根据上图中 RISC-V 规范中的描述,stvec 寄存器分为两部分,低 2 位称为 MODE,其他位称为 BASE。BASE 用于 trap 入口函数的基地址,必须保证四字节对齐。MODE 用于控制入口函数的地址配置方式。
- MODE=0 时,表示使用 Direct 方式,exception 发生后 PC 都跳转到 BASE 指定的地址处。
- MODE=1 时,表示使用 Vectored 方式,exception 的处理方式同 Direct,但 interrupt 的入口地址以数组方式排列。
sepc (Supervisor Exception Program Counter)
当发生 trap 时,处理器会将发生 trap 所对应的指令的地址(pc)保存在 sepc 中
scause (Supervisor Cause Register)
当 trap 发生时,处理器会设置该寄存器表示 trap 发生的原因

根据 RISC-V 规范,scause 寄存器由高 1 位的 Interrupt 和 其他位的 Exception Code 组成。
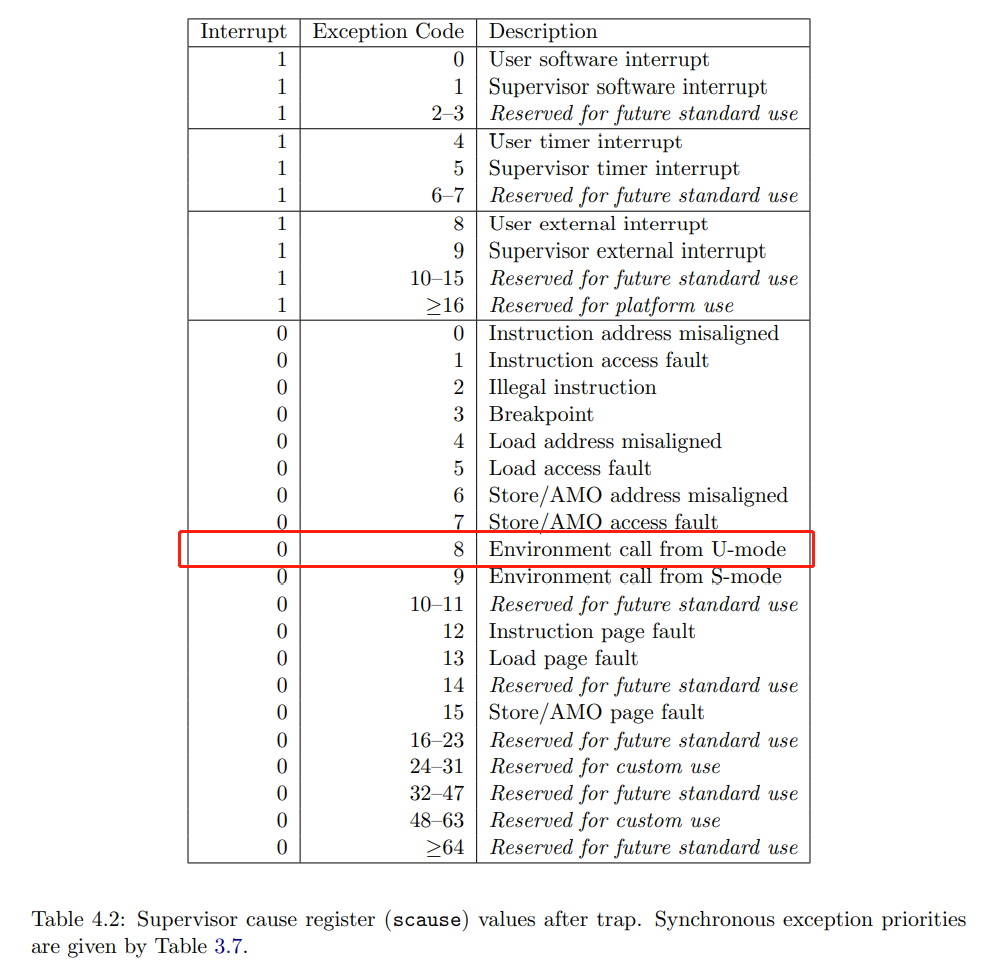
Syscall 触发时设置的内容如上图中红框所示,Interrupt=0 表示是异常,Exception Code=8,表示是从用户态执行的 ecall。
sstatus (Supervisor Status Register)
用于跟踪和控制处理器当前操作状态(比如包括关闭和打开全局中断)

根据 RISC-V 规范,UIE、SIE 分别用于打开(1)或者关闭(0)用户/内核模式下的全局中断。UPIE、SPIE 用于当 trap 发生时保存 trap 发生之前的 UIE、SIE 值。SPP 用于当 trap 发生时用于保存 trap 发生之前的权限级别值。
参考资料
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- Stratovirt 的 RISC-V 虚拟化支持(六):PLIC 和 串口支持
- Stratovirt 的 RISC-V 虚拟化支持(五):BootLoader 和设备树
- Stratovirt 的 RISC-V 虚拟化支持(四):内存模型和 CPU 模型
- Stratovirt 的 RISC-V 虚拟化支持(三):KVM 模型
- Stratovirt 的 RISC-V 虚拟化支持(二):库的 RISC-V 适配
