

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
RISC-V Linux SPARSEMEM 介绍与分析
Author: Jack Y. eecsyty@outlook.com Date: 2022/04/10 Revisor: Falcon falcon@tinylab.org Project: RISC-V Linux 内核剖析 Sponsor: PLCT Lab, ISCAS
本文主要介绍 Linux 的 SPARSEMEM 内存模型,具体到体系结构特异的部分,将以 RISC-V 为例来介绍,本文中的 Linux 内核源码对应的版本为 5.17.
Linux 物理内存模型
学习过操作系统课程的同学都知道,Linux 把 RAM 空间分成大小相同的页帧(Page Frame),Page Frame 是 Linux 内存管理的基本单位,在大多数情况下一般把一页的大小配置为 4 KB。每个页帧对应着一个「页帧号」(Page Frame Number,简称 PFN)。只要得知该页帧的 PFN,就能得知该页帧的物理地址,即可在硬件 RAM 上对这个地址对应的内存空间进行访问。
而为了对一个页帧进行管理,Linux 设计了 struct page 这个结构体,该结构体中包括了该页的状态标志位、映射的地址空间、引用计数等内容,具体可参考这篇文章。
物理内存的每一个页帧,都有一个对应的 struct page 结构体,而如何将这些结构体进行有效地组织和管理,就是 Linux 物理内存模型。更加通俗的来说,物理内存模型主要的作用是完成 PFN 和 struct page 之间的相互查找,即 pfn_to_page() 和 page_to_pfn()。
FLATMEM 模型
Linux 最早采用的是简单直接的 FLATMEM 模型,从名字可以看出,该模型认为物理内存是「平铺」的,即连续存在的。在最早期的电脑中,物理内存都是以 0x0 地址开始的一块连续空间,因此早期 Linux 采用 FLATMEM 这种简单设计是符合当时的情况的(注:后来的 FLATMEM 模型也支持一个起始地址的偏移量,允许物理空间不从 0x0 地址开始,但仍认为物理地址是连续存在的)。
对于 FLATMEM 模型来说,所有页帧的 struct page 结构体以一个数组的形式,按照 PFN 从小到大的顺序连续存储,这使得 FLATMEM 模型的 pfn_to_page() 和 page_to_pfn() 十分简单而直接,其代码如下(include/asm-generic/memory_model.h):
// include/asm-generic/memory_model.h:18
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
ARCH_PFN_OFFSET)
从 PFN 到 struct page 的地址,只需在 struct page 数组的基地址 mem_map 的基础上,加上 PFN(再减去体系结构定义的偏移量 ARCH_PFN_OFFSET,以适配不从 0x0 地址开始的物理空间)即可;而从 struct page 的地址到 PFN 也仅仅是把上述公式进行一下移项变换而已。FLATMEM 模型的 struct page 结构如下图所示:
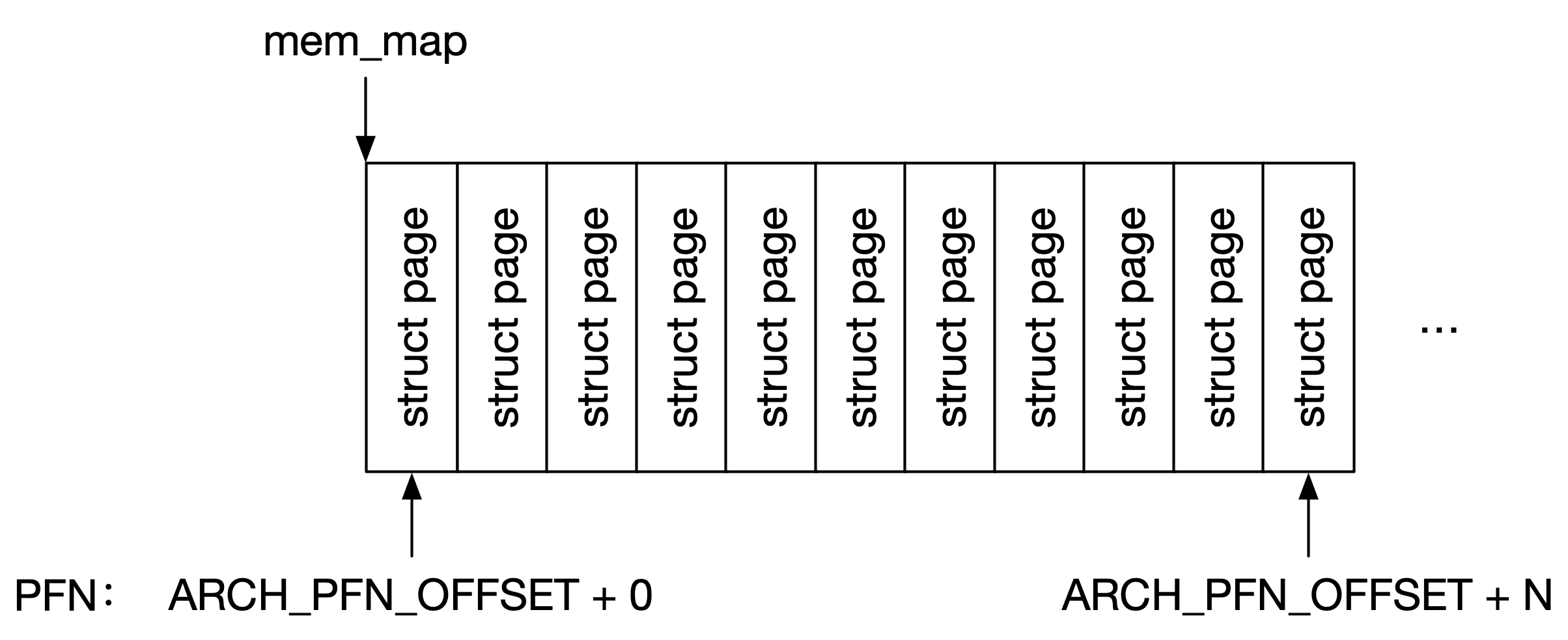
FLATMEM 模型的优点是结构简单,而且 pfn_to_page() 和 page_to_pfn() 只需进行两次加减法运算,十分高效。
但另一方面,现代的 SoC 中拥有不连续的物理地址空间的现象很普遍(即物理地址空间有「空洞」),而 FLATMEM 认为物理地址是连续的,这使得即使某些页帧所对应的物理地址并没有实际的内存,Linux 也要为其分配 struct page 结构体,十分浪费内存资源。而对于 NUMA(一种目前广泛用于服务器上的内存架构,大致意思是每个 CPU 有自己对应的内存 Bank,其访问自己的内存 Bank 十分高效,而访问其他 Bank 则相对速度较慢,具体内容读者可自行查阅相关资料)、内存热插拔(HotPlug 和 HotRemove)等内存特性,FLATMEM 则无法支持。这就需要一个能适应现代硬件结构的新的物理内存模型。
在 1999 年,为了使 Linux 内核能够更好地运行在 NUMA 机器上,一种名为 DISCONTIGMEM 的内存模型诞生了,但由于其管理的粒度较粗,无法支持内存热插拔功能。本文受篇幅所限,不对该内存模型进行详细介绍。
SPARSEMEM 模型
2005 年 Linux 又设计了 SPARSEMEM 模型,顾名思义就是稀疏内存,专为不连续的物理内存而设计。
SPARSEMEM 模型在当时被称为「一个新的、实验性的 DISCONTIGMEM 替代品」,由于 SPARSEMEM 功能已经完全覆盖 DISCONTIGMEM,后者已于 2021 年被移除。
mem_section
在 SPARSEMEM 模型中,设计了一个比 page 更大的内存管理粒度「mem_section」。
一个 mem_section 所对应的内存大小由宏 SECTION_SIZE_BITS 定义。在 RISC-V 中,其被定义为 27(见arch/riscv/include/asm/sparsemem.h),即一个 mem_section 对应 $2^{27} = 128 $ MB 物理内存。
而 SPARSEMEM 的总共数量则由宏 NR_MEM_SECTIONS 来定义,后者的定义整理如下:
// arch/riscv/include/asm/sparsemem.h:7
#ifdef CONFIG_64BIT
#define MAX_PHYSMEM_BITS 56
#else
#define MAX_PHYSMEM_BITS 34
#endif /* CONFIG_64BIT */
// include/linux/page-flags-layout.h:31
#define SECTIONS_SHIFT (MAX_PHYSMEM_BITS - SECTION_SIZE_BITS)
// include/linux/mmzone.h:1287
#define NR_MEM_SECTIONS (1UL << SECTIONS_SHIFT)
即这些 struct section_mem 覆盖了整个物理地址空间大小。在 32 位条件下,struct section_mem 的数量为 $2^7 = 128$ 个;而在 64 位中,其数量达到 $2^{29} = 536,870,912$ 个!
在经典 SPARSEMEM 模型中,struct mem_section 在程序中的组织方式也很简单,通过一个二维数组将所有的 struct mem_section 保存在一个连续、固定的内存空间中:
// include/linux/mmzone.h:1372
#define SECTIONS_PER_ROOT 1
// include/linux/mmzone.h:1376
#define NR_SECTION_ROOTS DIV_ROUND_UP(NR_MEM_SECTIONS, SECTIONS_PER_ROOT)
// mm/sparse.c:29
struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT]
____cacheline_internodealigned_in_smp;
由于在经典 SPARSEMEM 模型中, SECTIONS_PER_ROOT 被定义为 1,mem_section 二维数组实际上就是长度为 NR_MEM_SECTIONS 的一维数组。经典 SPARSEMEM 模型中 struct mem_section 的组织结构如下:
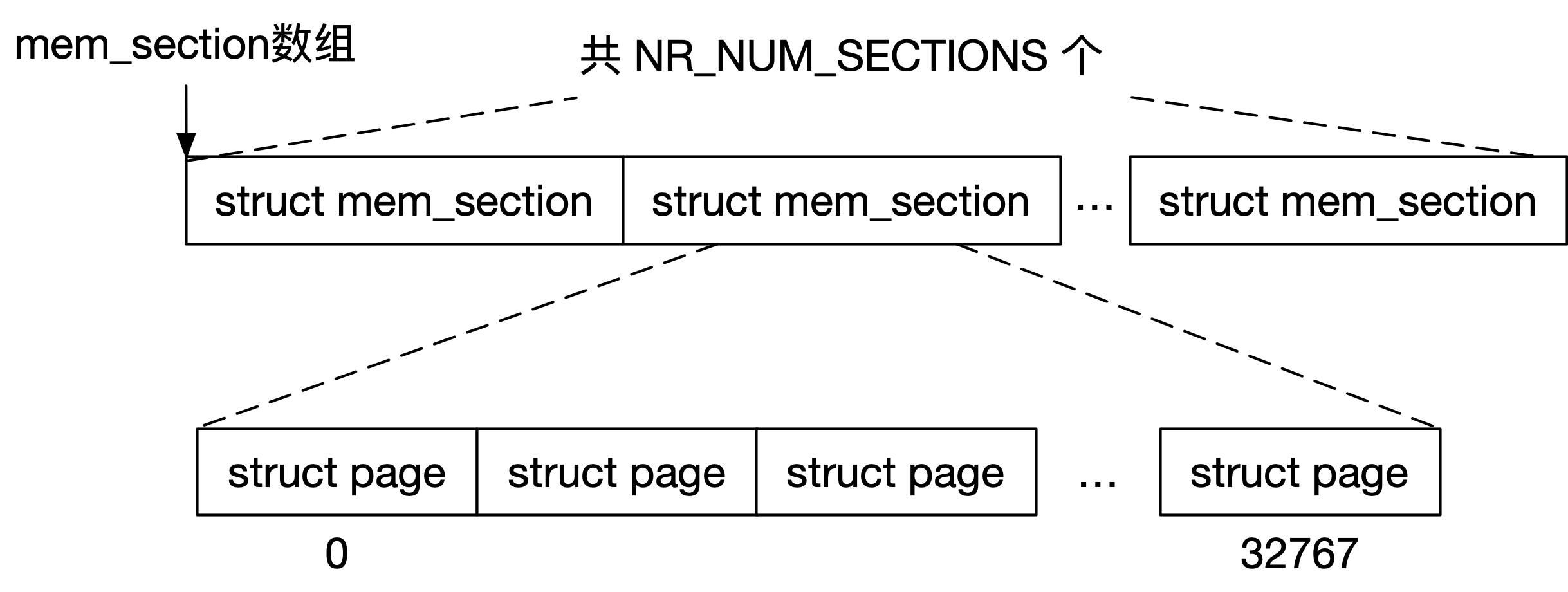
每一个 struct mem_section 都有一个编号,叫做 section_nr,定义方式为物理地址右移 PA_SECTION_SHIFT 位,可以轻易理解的是,PA_SECTION_SHIFT 的值就等于 SECTION_SIZE_BITS。
因此从 PFN 到 section_nr 的过程也就是简单的移位过程:
// include/linux/mmzone.h:4
static inline unsigned long pfn_to_section_nr(unsigned long pfn)
{
return pfn >> PFN_SECTION_SHIFT;
}
经典 SPARSEMEM 模型的 pfn_to_page() 和 page_to_pfn()
讲了半天 struct mem_section 的组织形式,接下来详细介绍一下其内部结构:
// include/linux/mmzone.h:1339
struct mem_section {
unsigned long section_mem_map;
struct mem_section_usage *usage;
};
struct mem_section 只有两个成员。其中 section_mem_map 主要是该 mem_section 管理的 struct page 的数组指针,但为了充分利用空间,在这其中还编码了其他信息。在 mem_section 的初始化函数 sparse_init_one_section 中,我们可以看到 section_mem_map 的赋值逻辑:
// mm/sparse.c:301
static void __meminit sparse_init_one_section(struct mem_section *ms,
unsigned long pnum, struct page *mem_map,
struct mem_section_usage *usage, unsigned long flags)
{
ms->section_mem_map &= ~SECTION_MAP_MASK;
ms->section_mem_map |= sparse_encode_mem_map(mem_map, pnum)
| SECTION_HAS_MEM_MAP | flags;
ms->usage = usage;
}
section_mem_map 的赋值包括三个部分,一个是 sparse_encode_mem_map() 的返回值,另外两个是 flag,分别是 SECTION_HAS_MEM_MAP,这个从字面意义上很好理解,以及外面传进来的 flags。
在系统初始化时加载的 mem_section,该 flags 传的值为 SECTION_IS_EARLY;而对于热插入的 mem_section,该值为 0。
sparse_encode_mem_map() 则相对复杂而「巧妙」一些,它传入了两个参数:mem_map 是这个 mem_section 的 struct page 数组地址;pnum 是该 mem_section 的 section_nr,即它的编号。在 sparse_encode_mem_map() 内部,将 mem_map 和 section_nr 转换得到的 PFN 做差值,结果则为函数的返回值,最终写入 section_mem_map 结构体成员中。这样就将该 mem_section 的初始 PFN 也编码进其中,其主要是,以后进行转换时可通过 PFN 作为 section_mem_map 的索引,快速得到 struct page 的地址;或者通过 struct page 的地址,快速得到 PFN。
// mm/sparse.c:280
static unsigned long sparse_encode_mem_map(struct page *mem_map, unsigned long pnum)
{
unsigned long coded_mem_map =
(unsigned long)(mem_map - (section_nr_to_pfn(pnum)));
BUILD_BUG_ON(SECTION_MAP_LAST_BIT > (1UL<<PFN_SECTION_SHIFT));
BUG_ON(coded_mem_map & ~SECTION_MAP_MASK);
return coded_mem_map;
}
上述代码中的 section_nr_to_pfn() 也很直接,只要位移相应的位数即可。
// include/linux/mmzone.h:1303
static inline unsigned long section_nr_to_pfn(unsigned long sec)
{
return sec << PFN_SECTION_SHIFT;
}
现在我们就可以顺理成章地得到经典 SPARSEMEM 模型的 pfn_to_page() 和 page_to_pfn() 了:
从 PFN 到 struct page 的步骤:
- 我们利用上文中的
pfn_to_section_nr()函数,得到该 PFN 对应的section_nr。 - 从
mem_section数组中,获得下标为section_nr的struct mem_section。 - 把得到的
struct mem_section中的section_mem_map成员中编码的flags去掉,再利用 PFN 作为下标进行索引(即地址 + PFN),即可得到struct page的地址。
从 struct page 到 PFN 的步骤几乎就是上述过程的逆过程:
- 获得该
struct page所属的mem_section。 - 计算
struct page地址与section_mem_map成员的差值,即为 PFN。
经典 SPARSEMEM 模型 pfn_to_page() 和 page_to_pfn() 代码如下:
// include/asm-generic/memory_model.h:29
/*
* Note: section's mem_map is encoded to reflect its start_pfn.
* section[i].section_mem_map == mem_map's address - start_pfn;
*/
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
经典 SPARSEMEM 模型的意义与局限性
SPARSEMEM 模型设计了 struct mem_section 这样一个层级,将 FLATMEM 模型中 struct page 必须从物理地址开始到结束而连续存在,变成了 struct mem_section 必须连续存在。
这样在内存空洞的场景下,只需要每 128 MB 的物理地址空间存在一个 (其中没有 struct page 的)struct mem_section 即可,而无需为每 4 KB 的物理地址空间都分配一个 struct page,减少了不必要的内存开销。
而通过 struct mem_section 的动态初始化与销毁(即释放其中的 struct page),可以实现物理内存热插拔的特性,有关这部分流程,读者可自行阅读「mm/sparse.c」中的 sparse_add_section() 和 sparse_remove_section()。
但经典 SPARSEMEM 模型仍有两大问题:
- 经典 SPARSEMEM 模型的
mem_section数组是固定分配的,在 RV32 架构下,共 128 个,这样的开销还可以接受;但在 RV64 架构下,其数量达到 $2^{29} = 536,870,912$ 个,实在是浪费空间十分严重。 - 尽管已经做了非常「巧妙」的编码,经典 SPARSEMEM 模型的
pfn_to_page()和page_to_pfn()与 FLATMEM相比,仍然较为复杂。就pfn_to_page()来说,前者需要 2 次加法操作、1 次移位操作、1 次按位与操作和 1 次内存读取操作;而后者只需 1 次加法操作和 1 次减法操作即可。
因此后续又增加了 SPARSEMEM 模型的两个扩展版本:SPARSEMEM_EXTREME 和 SPARSEMEM_VMEMMAP。
SPARSEMEM_EXTREME 扩展
SPARSEMEM_EXTREME 扩展是为了解决上文中提到的 SPARSEMEM 的第 1 个问题而诞生的。
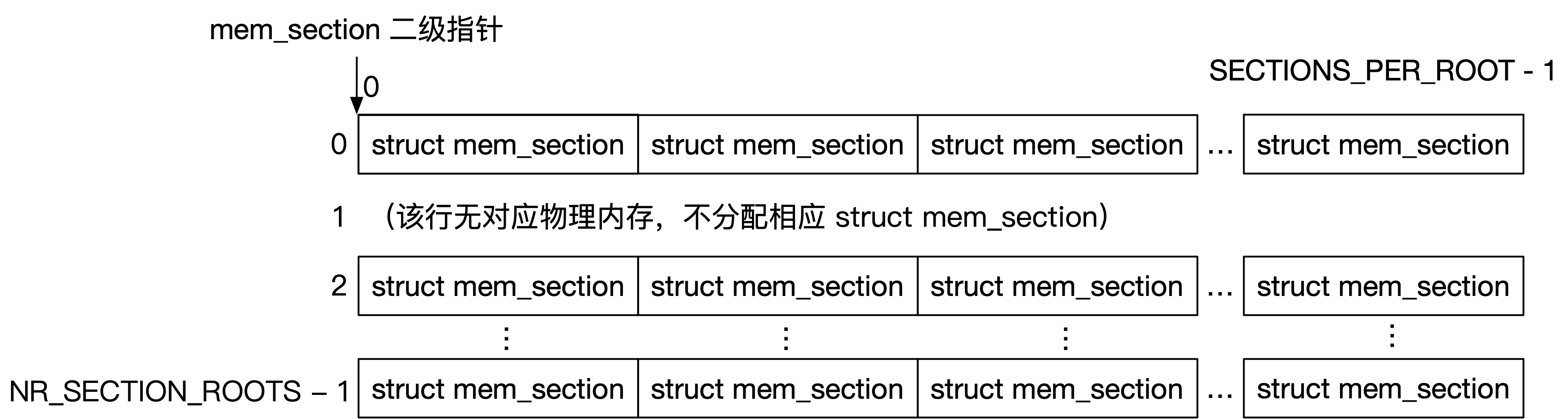
它在 mem_section 的上面又划分了一个层级——将 SECTIONS_PER_ROOT 个 struct mem_section 划分成一个 SECTION_ROOT。在上文经典 SPARSEMEM 模型中 SECTIONS_PER_ROOT 被定义为 1,因此相当于没有这个层次的划分,而开启了 SPARSEMEM_EXTREME 扩展以后,SECTIONS_PER_ROOT 的定义如下:
// include/linux/mmzone.h:1370
#define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof (struct mem_section))
即一页大小的 struct mem_section 被划分成一个 SECTION_ROOT。
另一方面,mem_section 也不再是一个固定分配的二维数组,而是变成了一个二级指针,动态分配所需要的 struct section_mem 的内存空间:
// include/linux/mmzone.h:1380
extern struct mem_section **mem_section;
在初始化时会分配 struct mem_section* 指针数组:
// mm/sparse.c:231
if (unlikely(!mem_section)) {
unsigned long size, align;
size = sizeof(struct mem_section *) * NR_SECTION_ROOTS;
align = 1 << (INTERNODE_CACHE_SHIFT);
mem_section = memblock_alloc(size, align);
if (!mem_section)
panic("%s: Failed to allocate %lu bytes align=0x%lx\n",
__func__, size, align);
}
在初始化,或热插入 mem_section 时,需要先分配该 mem_section 所在的空间,原则是如果分配一个 mem_section,则必须将该 mem_section 所属的 SECTION_ROOT 中所有的 mem_section 的空间全部分配完毕,写入 mem_section 二级指针中。
// mm/sparse.c:63
static noinline struct mem_section __ref *sparse_index_alloc(int nid)
{
struct mem_section *section = NULL;
unsigned long array_size = SECTIONS_PER_ROOT *
sizeof(struct mem_section);
if (slab_is_available()) {
section = kzalloc_node(array_size, GFP_KERNEL, nid);
} else {
section = memblock_alloc_node(array_size, SMP_CACHE_BYTES,
nid);
if (!section)
panic("%s: Failed to allocate %lu bytes nid=%d\n",
__func__, array_size, nid);
}
return section;
}
static int __meminit sparse_index_init(unsigned long section_nr, int nid)
{
unsigned long root = SECTION_NR_TO_ROOT(section_nr);
struct mem_section *section;
/*
* An existing section is possible in the sub-section hotplug
* case. First hot-add instantiates, follow-on hot-add reuses
* the existing section.
*
* The mem_hotplug_lock resolves the apparent race below.
*/
if (mem_section[root])
return 0;
section = sparse_index_alloc(nid);
if (!section)
return -ENOMEM;
mem_section[root] = section;
return 0;
}
下图是 SPARSEMEM_EXTREME 扩展的 struct mem_section 组织结构,在图中下标为 $1$ 的 MEM_SECTION_ROOT 中无任何物理内存与其对应,即可不分配相应的 struct mem_section 结构体。
SPARSEMEM_VMEMMAP 扩展
SPARSEMEM_VMEMMAP 扩展是为了解决上文中提到的经典 SPARSEMEM 模型的第二个缺点,即 pfn_to_page() 和 page_to_pfn() 过程较复杂而出现的。在设计之初,增加 SPARSEMEM_VMEMMAP 的 Commit 的注释中描述其「可能使得 SPARSEMEM 成为绝大多数系统的默认(甚至唯一)选项」,足以体现出其重要性。
它的主要思想并不复杂:在 SPARSEMEM 中,struct page 为应对内存空洞,实际上不会连续存在,但可以设法安排每个 struct page(不管其存在与否)的虚拟地址是固定且连续的,因为分配虚拟地址并不会有实际的开销,反而可以方便进行索引。
在 RISC-V 中,在内核虚拟地址区给 VMEMMAP 单独分配了一段虚拟地址空间,紧挨着 VMALLOC 的空间区域:
// arch/riscv/include/asm/pgtable.h:66
#define VA_BITS (pgtable_l4_enabled ? 48 : 39)
#else
#define VA_BITS 32
#endif
#define VMEMMAP_SHIFT \
(VA_BITS - PAGE_SHIFT - 1 + STRUCT_PAGE_MAX_SHIFT)
#define VMEMMAP_SIZE BIT(VMEMMAP_SHIFT)
#define VMEMMAP_END VMALLOC_START
#define VMEMMAP_START (VMALLOC_START - VMEMMAP_SIZE)
/*
* Define vmemmap for pfn_to_page & page_to_pfn calls. Needed if kernel
* is configured with CONFIG_SPARSEMEM_VMEMMAP enabled.
*/
#define vmemmap ((struct page *)VMEMMAP_START)
在初始化过程中,通过调用 populate_section_memmap() 函数,建立 struct page 到 vmemmap 的映射。
这样一来,开启了 VMEMMAP 扩展后,pfn_to_page() 和 page_to_pfn() 将变得更加简单:
// include/asm-generic/memory_model.h:24
/* memmap is virtually contiguous. */
#define __pfn_to_page(pfn) (vmemmap + (pfn))
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
只需 1 次加(减)法操作,即可完成转换。
总结
本文介绍了 Linux 内核中的物理内存模型从 FLATMEM 到 SPARSEMEM 的发展历程,以及 SPARSEMEM 产生的原因以及背后原理。在经典 SPARSEMEM 模型的基础上为进一步优化产生出了 SPARESMEM_EXTREME 扩展和 SPARSEMEM_VMEMMAP 扩展,让我们体会到,在 Linux 内核中对性能和资源消耗的极致追求是永无止境的。
参考文档
1.Memory: the flat, the discontiguous, and the sparse
2.从 pfn_to_page/page_to_pfn 看 Linux SPARSEMEM 内存模型
3.Remove DISCINTIGMEM memory model
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- Stratovirt 的 RISC-V 虚拟化支持(六):PLIC 和 串口支持
- Stratovirt 的 RISC-V 虚拟化支持(五):BootLoader 和设备树
- Stratovirt 的 RISC-V 虚拟化支持(四):内存模型和 CPU 模型
- Stratovirt 的 RISC-V 虚拟化支持(三):KVM 模型
- Stratovirt 的 RISC-V 虚拟化支持(二):库的 RISC-V 适配
