

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
RISC 内存虚拟化在 KVM 及 kvmtool 中的实现
Corrector: TinyCorrect v0.1 - [spaces images urls] Author: XiakaiPan 13212017962@163.com Date: 2022/10/11 Revisor: walimis, Falcon Project: RISC-V Linux 内核剖析 Proposal: RISC-V 虚拟化技术调研与分析 Sponsor: PLCT Lab, ISCAS
前言
在 RISC-V 特权指令级中,H 扩展规定了实现虚拟化支持所需的一系列 CSR、指令和机制,前文 在指令集层面就内存虚拟化的相关机制进行了分析,在此基础之上,本文将讨论 KVM 中关于这一系列机制的具体实现。
软件版本
| Software | commit ID or version No. | Link |
|---|---|---|
| Linux Kernel | v6.0 | https://www.kernel.org/ |
| kvmtool | 6a1f699108e5c2a280d7cd1f1ae4816b8250a29f | https://github.com/kvmtool/kvmtool |
KVM 中的 G-Stage 地址转换实现
KVM 对外提供了用于创建设备的接口 kvm_dev_ioctl,kvmtool 之类的外部虚拟机管理程序通过调用 KVM 提供的对应接口创建虚拟机。KVM 本身则以 RISC-V 特权指令集为标准,实现了 RISC-V 的虚拟化机制。RISC-V 将 Guest 虚拟地址转换为 Host 的物理地址的这一过程划分为两个阶段,即 VS-Stage 和 G-Stage,其中 VS-Stage 与常见的支持 M/S/U 三种模式的机器的地址转换机制一致,而 G-Stage 由于需要考虑 Hypervisor 对多个虚拟机的地址空间的分配,所以需要额外引入其他机制对上述分配进行管理,这也正是虚拟化实现中需要特别考虑的地方。而 KVM 对于 RISC-V 虚拟化的支持,相较于其他架构的实现,就体现在实现了一套 RISC-V 标准的虚拟机创建与管理机制。
本节将对 KVM 中与 G-Stage 地址转换相关的代码进行分析。创建 KVM 虚拟机需要调用 virt/kvm/kvm_main.c/kvm_create_vm 函数,该函数内部则是通过 arch/riscv/kvm/vcpu_exit.c/kvm_arch_init_vm 来做架构初始化的,初始化的过程就是调用对应函数为虚拟机申请地址空间、初始化 vmid (Virtual Machine InDex)、初始化 Guest 计时器。下面将分析逐个分析与虚拟机内存管理相关的内存申请、CSR 修改、页缺陷处理、HFENCE 指令。
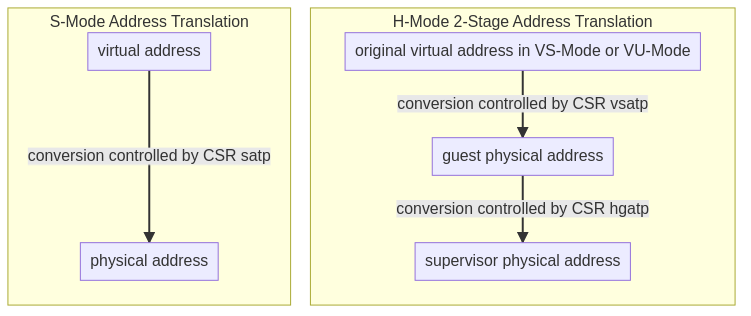
地址定义
在 KVM 的 RISC-V 虚拟化实现里,将分别使用 GVA, GPA 表示 VM 中的虚拟地址、物理地址,使用 HVA,HPA 表示 Host 中的虚拟地址、物理地址,使用 GFN 和 HFN 表示 Guest 和 Host 物理页的页帧号,如下所示:
/*
* Address types:
*
* gva - guest virtual address
* gpa - guest physical address
* gfn - guest frame number
* hva - host virtual address
* hpa - host physical address
* hfn - host frame number
*/
typedef unsigned long gva_t;
typedef u64 gpa_t;
typedef u64 gfn_t;
#define GPA_INVALID (~(gpa_t)0)
typedef unsigned long hva_t;
typedef u64 hpa_t;
typedef u64 hfn_t;
为虚拟机申请内存
arch/riscv/kvm/vm.c 的 kvm_arch_init_vm 函数调用 arch/riscv/kvm/mmu.c 中的 kvm_riscv_gstage_alloc_pgd(struct kvm *kvm) 函数为虚拟机申请内存,具体来说是将被 Hypervisor 做分页管理的内存空间分配(allocate)给虚拟机,表现为返回给 KVM 虚拟机一个页目录(Page Directory)。这一过程发生在 Hypervisor 的内存管理即 G-Stage 地址转换过程中。代码实现如下:
// arch/riscv/kvm/mmu.c: line 712
int kvm_riscv_gstage_alloc_pgd(struct kvm *kvm)
{
struct page *pgd_page;
// 是否已经为 VM 分配了目录页号
if (kvm->arch.pgd != NULL) {
kvm_err("kvm_arch already initialized?\n");
return -EINVAL;
}
// 分配
pgd_page = alloc_pages(GFP_KERNEL | __GFP_ZERO,
get_order(gstage_pgd_size));
if (!pgd_page)
return -ENOMEM;
kvm->arch.pgd = page_to_virt(pgd_page);
kvm->arch.pgd_phys = page_to_phys(pgd_page);
return 0;
}
其中 alloc_pages 函数中用到的参数相关的宏定义如下:
// include/linux/gfp_types.h: line 333
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
// include/linux/gfp_types.h: line 249
#define __GFP_ZERO ((__force gfp_t)___GFP_ZERO)
// arch/riscv/include/asm/csr.h: line 139
#define HGATP_PAGE_SHIFT 12
// include/linux/gfp_types.h: line 32
#define gstage_pgd_xbits 2
#define gstage_pgd_size (1UL << (HGATP_PAGE_SHIFT + gstage_pgd_xbits))
alloc_pages 函数定义如下:
// include/linux/gfp.h: line 275
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_node(numa_node_id(), gfp_mask, order);
}
// include/linux/gfp.h: line 260
/*
* Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,
* prefer the current CPU's closest node. Otherwise node must be valid and
* online.
*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
// include/linux/gfp.h: line 237
/*
* Allocate pages, preferring the node given as nid. The node must be valid and
* online. For more general interface, see alloc_pages_node().
*/
static inline struct page *
__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);
VM_WARN_ON((gfp_mask & __GFP_THISNODE) && !node_online(nid));
return __alloc_pages(gfp_mask, order, nid, NULL);
}
最终执行页分配的函数是 __alloc_pages,该函数是 kernel 的 Buddy 内存管理系统的核心函数之一,其定义如下。以下关于该函数的分析以及对应的 Linux Buddy System 的解读参考自 此文。
Linux 中的内存管理从大到小可以分为 node、zone、page 三个级别。其中 page(页)是分页内存机制和底层内存分配的最小单元,大小为 4K 字节,物理页的页帧叫做 pfn(page frame number)。
flowchart
subgraph node0
subgraph zone0
subgraph page00
end
page01
page0N[...]
end
subgraph zone1
subgraph page10
end
page11
page1N[...]
end
zoneN[...]
end
伙伴内存系统(Buddy System)是对物理内存进行分配的算法,它的基本管理单位是区域(zone),最小分配粒度是页面(page)。但伙伴系统本身并不直接管理页帧,而是管理由多个页帧组成的页块(pageblock),一个 n 阶(order)的页块包含了 $2^n$ 个页帧,n 的大小为 0 到 10。伙伴系统的所有分配接口最终都会使用、__alloc_pages 这个函数来进行分配。
// mm/page_alloc.c: line 5513
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
/* 页分配之前的准备工作,此处代码略去 */
/* Preparation code, omitted here */
// ...
/* 先从 freelist 中申请内存 */
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))
goto out;
// ...
/* 如果从 freelist 中申请失败,则需要在内存回收后进行分配,即 slow path */
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);
out:
// ...
return page;
}
释放虚拟机内存
与虚拟机的内存申请相似,KVM 释放内存也是通过调用 Linux 的 Buddy System 的内存释放 API 来实现的,具体来说 arch/riscv/kvm/mmu.c/kvm_riscv_gstage_free_pgd() 函数调用 mm/page_alloc.c 中的 free_pages() 函数释放对应虚拟机的内存。
// arch/riscv/kvm/mmu.c: line 731
void kvm_riscv_gstage_free_pgd(struct kvm *kvm)
{
void *pgd = NULL;
spin_lock(&kvm->mmu_lock);
if (kvm->arch.pgd) {
gstage_unmap_range(kvm, 0UL, gstage_gpa_size, false);
pgd = READ_ONCE(kvm->arch.pgd);
kvm->arch.pgd = NULL;
kvm->arch.pgd_phys = 0;
}
spin_unlock(&kvm->mmu_lock);
if (pgd)
free_pages((unsigned long)pgd, get_order(gstage_pgd_size));
}
Buddy System 释放内存的 API 调用如下方代码所示:
// mm/page_alloc.c: 5641
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
// mm/page_alloc.c: 5631
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
else if (!PageHead(page))
while (order-- > 0)
free_the_page(page + (1 << order), order);
}
// mm/page_alloc.c: 764
static inline void free_the_page(struct page *page, unsigned int order)
{
if (pcp_allowed_order(order)) /* Via pcp? */
free_unref_page(page, order);
else
__free_pages_ok(page, order, FPI_NONE);
}
G-Stage Page Fault
G-Stage 的 page fault 处理函数定义在 arch/riscv/kvm/vcpu_exit.c 中,定义如下。其中涉及的 MMIO 处理函数 kvm_riscv_vcpu_mmio_load,kvm_riscv_vcpu_mmio_store 此处不予讨论,下面分析如何通过调用 kvm_riscv_gstage_map 函数实现 G-Stage 的地址映射。
// arch/riscv/kvm/vcpu_exit.c: line 12
static int gstage_page_fault(struct kvm_vcpu *vcpu, struct kvm_run *run,
struct kvm_cpu_trap *trap)
{
struct kvm_memory_slot *memslot;
unsigned long hva, fault_addr;
bool writable;
gfn_t gfn;
int ret;
// 从 trap 信息中获取页错误的地址 gpa (Guest Physical Address)
// get page fault address from trap information
fault_addr = (trap->htval << 2) | (trap->stval & 0x3);
// 将发生错误的地址先转换为 Guest 页号(Guest Frame Number)、再转换为可以在 hypervisor 中进行处理的 hva(Hypervisor Virtual Address)
gfn = fault_addr >> PAGE_SHIFT;
memslot = gfn_to_memslot(vcpu->kvm, gfn);
// 返回 gfn 对应的 hva 及其读写属性
// Return the hva of a @gfn and the R/W attribute if possible
hva = gfn_to_hva_memslot_prot(memslot, gfn, &writable);
// 依据 scause CSR 的值判定当前的 page fault 是何类型(Load/Store)并进行相应处理
if (kvm_is_error_hva(hva) ||
(trap->scause == EXC_STORE_GUEST_PAGE_FAULT && !writable)) {
switch (trap->scause) {
case EXC_LOAD_GUEST_PAGE_FAULT:
return kvm_riscv_vcpu_mmio_load(vcpu, run,
fault_addr,
trap->htinst);
case EXC_STORE_GUEST_PAGE_FAULT:
return kvm_riscv_vcpu_mmio_store(vcpu, run,
fault_addr,
trap->htinst);
default:
return -EOPNOTSUPP;
};
}
// 进行 G-Stage 的地址映射
ret = kvm_riscv_gstage_map(vcpu, memslot, fault_addr, hva,
(trap->scause == EXC_STORE_GUEST_PAGE_FAULT) ? true : false);
if (ret < 0)
return ret;
return 1;
}
传入的参数中 trap 保存了此次 page fault 的具体信息,其定义如下。其中 sepc, scause, stval 是复用了非虚拟化时的 S-Mode CSR,而 htval 和 htinst 这两个 CSR 则是 H 扩展中为了支持 G-Stage 而添加的。
// arch/riscv/include/asm/kvm_host.h
struct kvm_cpu_trap {
unsigned long sepc;
unsigned long scause;
unsigned long stval;
unsigned long htval;
unsigned long htinst;
};
kvm_riscv_gstage_map 函数通过如下三个部分实现了地址映射。
第一部分是 mmap_read_lock(current->mm); 和 mmap_read_unlock(current->mm); 之间的代码,这部分通过 hva 初始化 vma(Virtual Memory Area,虚拟内存区域,用于表示具有特定 page-fault 处理方式的 Virtual Memory Space 的任意部分,参见 include/linux/mm_types.h 403 行定义)最终确定 gfn 的值。
第二部分是调用 gfn_to_pfn_prot 用 gfn 的值初始化 hfn 的值。
第三部分则是 spin_lock(&kvm->mmu_lock); 和 spin_unlock(&kvm->mmu_lock); 之间的代码段,用于更新 MMU:如果此次 page fault 是要求无效化特定存储项的,则跳转到 out_unlock 部分设置并清除 hfn 项,否则的话将会根据此次 page fault 对应页帧的可写状态调用 gstage_map_page 函数对 gpa 和 hpa(代码中即为 hfn << PAGE_SHIFT)进行映射。
// arch/riscv/kvm/mmu.c: line 617
int kvm_riscv_gstage_map(struct kvm_vcpu *vcpu,
struct kvm_memory_slot *memslot,
gpa_t gpa, unsigned long hva, bool is_write)
{
int ret;
kvm_pfn_t hfn;
bool writable;
short vma_pageshift;
gfn_t gfn = gpa >> PAGE_SHIFT;
struct vm_area_struct *vma;
struct kvm *kvm = vcpu->kvm;
struct kvm_mmu_memory_cache *pcache = &vcpu->arch.mmu_page_cache;
bool logging = (memslot->dirty_bitmap &&
!(memslot->flags & KVM_MEM_READONLY)) ? true : false;
unsigned long vma_pagesize, mmu_seq;
mmap_read_lock(current->mm);
vma = find_vma_intersection(current->mm, hva, hva + 1);
if (unlikely(!vma)) {
kvm_err("Failed to find VMA for hva 0x%lx\n", hva);
mmap_read_unlock(current->mm);
return -EFAULT;
}
if (is_vm_hugetlb_page(vma))
vma_pageshift = huge_page_shift(hstate_vma(vma));
else
vma_pageshift = PAGE_SHIFT;
vma_pagesize = 1ULL << vma_pageshift;
if (logging || (vma->vm_flags & VM_PFNMAP))
vma_pagesize = PAGE_SIZE;
if (vma_pagesize == PMD_SIZE || vma_pagesize == PGDIR_SIZE)
gfn = (gpa & huge_page_mask(hstate_vma(vma))) >> PAGE_SHIFT;
mmap_read_unlock(current->mm);
if (vma_pagesize != PGDIR_SIZE &&
vma_pagesize != PMD_SIZE &&
vma_pagesize != PAGE_SIZE) {
kvm_err("Invalid VMA page size 0x%lx\n", vma_pagesize);
return -EFAULT;
}
/* We need minimum second+third level pages */
ret = kvm_mmu_topup_memory_cache(pcache, gstage_pgd_levels);
if (ret) {
kvm_err("Failed to topup G-stage cache\n");
return ret;
}
mmu_seq = kvm->mmu_invalidate_seq;
hfn = gfn_to_pfn_prot(kvm, gfn, is_write, &writable);
if (hfn == KVM_PFN_ERR_HWPOISON) {
send_sig_mceerr(BUS_MCEERR_AR, (void __user *)hva,
vma_pageshift, current);
return 0;
}
if (is_error_noslot_pfn(hfn))
return -EFAULT;
/*
* If logging is active then we allow writable pages only
* for write faults.
*/
if (logging && !is_write)
writable = false;
spin_lock(&kvm->mmu_lock);
if (mmu_invalidate_retry(kvm, mmu_seq))
goto out_unlock;
if (writable) {
kvm_set_pfn_dirty(hfn);
mark_page_dirty(kvm, gfn);
ret = gstage_map_page(kvm, pcache, gpa, hfn << PAGE_SHIFT,
vma_pagesize, false, true);
} else {
ret = gstage_map_page(kvm, pcache, gpa, hfn << PAGE_SHIFT,
vma_pagesize, true, true);
}
if (ret)
kvm_err("Failed to map in G-stage\n");
out_unlock:
spin_unlock(&kvm->mmu_lock);
kvm_set_pfn_accessed(hfn);
kvm_release_pfn_clean(hfn);
return ret;
}
下面分析实现 gstage page-fault 处理的核心函数 gstage_map_page,其代码实现如下:
// arch/riscv/kvm/mmu.c: line 177
static int gstage_map_page(struct kvm *kvm,
struct kvm_mmu_memory_cache *pcache,
gpa_t gpa, phys_addr_t hpa,
unsigned long page_size,
bool page_rdonly, bool page_exec)
{
int ret;
u32 level = 0;
pte_t new_pte;
pgprot_t prot;
// 根据 page_size 确定页所在层级(level),如果没有对应大小的页,则返回非 0 值
ret = gstage_page_size_to_level(page_size, &level);
if (ret)
return ret;
/*
* A RISC-V implementation can choose to either:
* 1) Update 'A' and 'D' PTE bits in hardware
* 2) Generate page fault when 'A' and/or 'D' bits are not set
* PTE so that software can update these bits.
*
* We support both options mentioned above. To achieve this, we
* always set 'A' and 'D' PTE bits at time of creating G-stage
* mapping. To support KVM dirty page logging with both options
* mentioned above, we will write-protect G-stage PTEs to track
* dirty pages.
*/
/* 基于 RISC-V 指令集手册的 PTE 更新机制的实现可以有两种选择,
* 即在硬件中更新页表项(PTE)的 A(Access)/D(Dirty)位,
* 或默认 PTE 的 A/D 位不设置,当访问未初始化的 PTE 时产生 page-fault
* 从而使软件更新上述标志位。
*
* KVM 的实现中同时支持了上述两种机制:在进行 G-Stage 地址映射时就初始化
* 对应标志位,同时通过对 G-Stage PTEs 的写保护达成了软件层面的脏页追踪机制。
*/
// 获取要执行操作的页的访问权限
if (page_exec) {
if (page_rdonly)
prot = PAGE_READ_EXEC;
else
prot = PAGE_WRITE_EXEC;
} else {
if (page_rdonly)
prot = PAGE_READ;
else
prot = PAGE_WRITE;
}
// 设置 hpa 对应页的权限位并标记为 dirty
new_pte = pfn_pte(PFN_DOWN(hpa), prot);
new_pte = pte_mkdirty(new_pte);
// 设置此次 page-fault 处理的页的内容
return gstage_set_pte(kvm, level, pcache, gpa, &new_pte);
}
在 gstage_set_pte 内部,逐级遍历 hypervisor 的页表,直至到达指定 level 的页表,之后对其进行操作(赋值、视是否为叶子结点刷新 TLB):
// arch/riscv/kvm/mmu.c: line 137
static int gstage_set_pte(struct kvm *kvm, u32 level,
struct kvm_mmu_memory_cache *pcache,
gpa_t addr, const pte_t *new_pte)
{
u32 current_level = gstage_pgd_levels - 1;
pte_t *next_ptep = (pte_t *)kvm->arch.pgd;
pte_t *ptep = &next_ptep[gstage_pte_index(addr, current_level)];
if (current_level < level)
return -EINVAL;
while (current_level != level) {
if (gstage_pte_leaf(ptep))
return -EEXIST;
// 若当前页表项无效,则根据 pcache 的内容有效性选择申请页表项(kvm_mmu_memory_cache_alloc)或直接返回错误代码
if (!pte_val(*ptep)) {
if (!pcache)
return -ENOMEM;
next_ptep = kvm_mmu_memory_cache_alloc(pcache);
if (!next_ptep)
return -ENOMEM;
*ptep = pfn_pte(PFN_DOWN(__pa(next_ptep)),
__pgprot(_PAGE_TABLE));
} else {
if (gstage_pte_leaf(ptep))
return -EEXIST;
next_ptep = (pte_t *)gstage_pte_page_vaddr(*ptep);
}
current_level--;
ptep = &next_ptep[gstage_pte_index(addr, current_level)];
}
// 为找到的页表项赋值(保存之前设置的权限位和脏页标志位)
*ptep = *new_pte;
// 倘若为叶子页表,刷新 TLB 对应项
if (gstage_pte_leaf(ptep))
gstage_remote_tlb_flush(kvm, current_level, addr);
return 0;
}
其中,逐级遍历找到下一级的页表项是通过交替更新 next_ptep 和 ptep 实现的,next_ptep 首先初始化为 page directory 即根页表,之后通过 gstage_pte_index 函数获得要操作的地址在当前层级页内的页表项索引,最终获得对应的当前层级的页表项。
// arch/riscv/kvm/mmu.c: line 42
static inline unsigned long gstage_pte_index(gpa_t addr, u32 level)
{
unsigned long mask;
unsigned long shift = HGATP_PAGE_SHIFT + (gstage_index_bits * level);
if (level == (gstage_pgd_levels - 1))
mask = (PTRS_PER_PTE * (1UL << gstage_pgd_xbits)) - 1;
else
mask = PTRS_PER_PTE - 1;
return (addr >> shift) & mask;
}
处理一个虚拟地址对应的 page-fault 意味着要更新其对应的 TLB 项,KVM 内部实现了内存操作的扩展指令集中的 hfence.gvma,该指令有 rs1 和 rs2 两个源操作数,分别指定了 Guest Address 和上述地址对应的 Guest 所在的 VM 的 ID(Index)。H 扩展相关的指令在 KVM 中的实现将在 后续小节 进行分析。
// arch/riscv/kvm/mmu.c: line 126
static void gstage_remote_tlb_flush(struct kvm *kvm, u32 level, gpa_t addr)
{
unsigned long order = PAGE_SHIFT;
if (gstage_level_to_page_order(level, &order))
return;
addr &= ~(BIT(order) - 1);
kvm_riscv_hfence_gvma_vmid_gpa(kvm, -1UL, 0, addr, BIT(order), order);
}
HGATP 更新
hgatp 的结构及其功能参见 内存虚拟化一文 对应章节,区别于 satp 和 vsatp 中由 ASID 来保存 Hypervisor/Supervisor 和 Guest 中的地址空间的索引值,hgatp 对应区域规定为 VMID,用于保存虚拟机的索引值。
下面将结合 KVM 中 hgatp 的更新函数的具体实现及其调用,详细分析该 CSR 的功能。
kvm_riscv_gstage_update_hgatp 函数定义在 mmu.c 中:
// arch/riscv/kvm/mmu.c: line 748
void kvm_riscv_gstage_update_hgatp(struct kvm_vcpu *vcpu)
{
// 设置当前地址系统(SV32,SV39,etc.)对应的 hgatp 初始值
unsigned long hgatp = gstage_mode;
// 获取指向当前 vcpu 的架构信息的指针
struct kvm_arch *k = &vcpu->kvm->arch;
// 设置 hgatp.VMID 位
hgatp |= (READ_ONCE(k->vmid.vmid) << HGATP_VMID_SHIFT) &
HGATP_VMID_MASK;
// 设置 hgatp.PPN 位
hgatp |= (k->pgd_phys >> PAGE_SHIFT) & HGATP_PPN;
// 更新 hgatp 的值
csr_write(CSR_HGATP, hgatp);
// 若当前 vmid 无效,使用 hfence.gvma 指令刷新全部 TLB 的项
if (!kvm_riscv_gstage_vmid_bits())
kvm_riscv_local_hfence_gvma_all();
}
如果为 64 位机器默认使用 SV39 的地址系统,否则若为 32 位机器则默认使用 SV32 的地址系统。
#ifdef CONFIG_64BIT
static unsigned long gstage_mode = (HGATP_MODE_SV39X4 << HGATP_MODE_SHIFT);
static unsigned long gstage_pgd_levels = 3;
#define gstage_index_bits 9
#else
static unsigned long gstage_mode = (HGATP_MODE_SV32X4 << HGATP_MODE_SHIFT);
static unsigned long gstage_pgd_levels = 2;
#define gstage_index_bits 10
#endif
涉及 hgatp 的更新有两种情况:
- 第一种的调用关系为:
kvm_arch_vcpu_create->kvm_riscv_reset_vcpu->kvm_arch_vcpu_load->kvm_riscv_gstage_update_hgatp,即在创建 vCPU 时进行初始化。 - 第二种的调用关系为:
kvm_arch_vcpu_ioctl_run->kvm_riscv_check_vcpu_requests->kvm_riscv_gstage_update_hgatp,即在 vCPU 运行时处理来自 Guest 的请求(sleep,reset,fence,update hgatp,etc.)
// arch/riscv/kvm/vcpu.c: line 915
int kvm_arch_vcpu_ioctl_run(struct kvm_vcpu *vcpu)
{
int ret;
// ...
vcpu_load(vcpu);
kvm_sigset_activate(vcpu);
ret = 1;
run->exit_reason = KVM_EXIT_UNKNOWN;
/* 处理 vCPU 内部请求的循环 */
while (ret > 0) {
// ...
/* 更新 VMID(内部将根据 VM 做出更新 hgatp 等请求)*/
kvm_riscv_gstage_vmid_update(vcpu);
/* 处理各个 vCPU 内部的请求 */
kvm_riscv_check_vcpu_requests(vcpu);
// ...
ret = kvm_riscv_vcpu_exit(vcpu, run, &trap);
}
kvm_sigset_deactivate(vcpu);
vcpu_put(vcpu);
kvm_vcpu_srcu_read_unlock(vcpu);
return ret;
}
其中 vmid 的更新函数如下:
// arch/riscv/kvm/vmid.c: line 71
void kvm_riscv_gstage_vmid_update(struct kvm_vcpu *vcpu)
{
unsigned long i;
struct kvm_vcpu *v;
struct kvm_vmid *vmid = &vcpu->kvm->arch.vmid;
/* 视情况更新 vmid 版本并刷新 TLB */
if (!kvm_riscv_gstage_vmid_ver_changed(vmid))
return;
spin_lock(&vmid_lock);
// ...
spin_unlock(&vmid_lock);
/* 为每一个 vCPU 更新页表的刷新请求 */
/* Request G-stage page table update for all VCPUs */
kvm_for_each_vcpu(i, v, vcpu->kvm)
kvm_make_request(KVM_REQ_UPDATE_HGATP, v);
}
在更新了 VMID 及其对应的 vCPU 内部的处理请求之后,将通过调用 kvm_riscv_check_vcpu_requests 函数进行处理:
// arch/riscv/kvm/vcpu.c: line 848
static void kvm_riscv_check_vcpu_requests(struct kvm_vcpu *vcpu)
{
struct rcuwait *wait = kvm_arch_vcpu_get_wait(vcpu);
if (kvm_request_pending(vcpu)) {
/* sleep, reset requests handling */
// ...
if (kvm_check_request(KVM_REQ_UPDATE_HGATP, vcpu))
kvm_riscv_gstage_update_hgatp(vcpu);
/* Memory management requests (fence.i, hfence.gvma, hfence.vvma, etc.) handling */
// ...
}
}
HFENCE 扩展指令的实现
与 H 扩展相关的内存管理指令包含了 HINVAL 扩展 和 HFENCE 扩展,其指令格式和功能参见 此文。HINVAL 指令 KVM 中并未予以实现,HFENCE 指令则在 tlb.c 中通过调用 make_xfence_request 实现。以 hfence.gvma 为例,其实现如下:
// arch/riscv/kvm/tlb.c: line 388
void kvm_riscv_hfence_gvma_vmid_gpa(struct kvm *kvm,
unsigned long hbase, unsigned long hmask,
gpa_t gpa, gpa_t gpsz,
unsigned long order)
{
struct kvm_riscv_hfence data;
data.type = KVM_RISCV_HFENCE_GVMA_VMID_GPA;
data.asid = 0;
data.addr = gpa;
data.size = gpsz;
data.order = order;
make_xfence_request(kvm, hbase, hmask, KVM_REQ_HFENCE,
KVM_REQ_HFENCE_GVMA_VMID_ALL, &data);
}
KVM 的实现中,根据指令对应的不同的使用场景,可大致分为如下四类实现:all 对应由 VMID 或 ASID 所指定的 TLB 的所有项,gpa 和 gva 则分别进一步指定了要处理的 TLB 项对应的 Guest/VM 地址。 | hfence | Guest/Virtual | vmid/asid | address space | |————————|—————|———–|—————| | kvm_riscv_local_hfence | gvma | vmid | gpa | | kvm_riscv_local_hfence | gvma | vmid | all | | kvm_riscv_local_hfence | vvma | asid | gva | | kvm_riscv_local_hfence | vvma | asid | all |
xfence 的定义如下:
// arch/riscv/kvm/tlb.c: line 345
static void make_xfence_request(struct kvm *kvm,
unsigned long hbase, unsigned long hmask,
unsigned int req, unsigned int fallback_req,
const struct kvm_riscv_hfence *data)
{
// ...
/* 将每个 vCPU 的 hfence 信息入队 */
kvm_for_each_vcpu(i, vcpu, kvm) {
// ...
if (!vcpu_hfence_enqueue(vcpu, data))
actual_req = fallback_req;
}
/* 若队满无法全部入队,则直接提交名为 fallback_req 的请求,对于指定了 VMID 和 GPA 的 hfence.gvma 指令而言,其 fallback_req 为刷新对应 VMID 的全部 TLB 项的 `KVM_REQ_HFENCE_GVMA_VMID_ALL`,以此保证即便不能做到精细化的内存管理,也可以通过粗粒度的指令达成所需的效果。*/
kvm_make_vcpus_request_mask(kvm, actual_req, vcpu_mask);
}
总览
整个过程中的调用关系如下图所示:
flowchart LR
subgraph arch/riscv/kvm/mmu.c
alloc_pgd[kvm_riscv_gstage_alloc_pgd]
free_pgd[kvm_riscv_gstage_free_pgd]
unmap[gstage_unmap_range]-->free_pgd
leaf[gstage_get_leaf_entry]-->free_pgd
l2s[gstage_level_to_page_size]-->op_pte
op_pte[gstage_op_pte]-->free_pgd
flush[gstage_remote_tlb_flush]-->op_pte
gmap[kvm_riscv_gstage_map]
mode_dtct[kvm_riscv_gstage_mode_detect]
mode[kvm_riscv_gstage_mode]
update_hgatp[kvm_riscv_gstage_update_hgatp]
gpa_bits[kvm_riscv_gstage_gpa_bits]
update_hgatp[kvm_riscv_gstage_update_hgatp]
flush_shadow[kvm_arch_flush_shadow_all]
pgva[gstage_pte_page_vaddr]-->leaf
set_pte[gstage_set_pte]-->mappg[gstage_map_page]
set_pte-->ioremap[kvm_riscv_gstage_ioremap]
mappg-->set_gfn[kvm_set_spte_gfn]
mappg-->gmap[kvm_riscv_gstage_map]
end
subgraph arch/riscv/kvm/vmid.c
vmid_init[kvm_riscv_gstage_vmid_init]
bits[kvm_riscv_gstage_vmid_bits]
vmid_dtct[kvm_riscv_gstage_vmid_detect]
vmid_change[kvm_riscv_gstage_vmid_ver_changed]
update[kvm_riscv_gstage_vmid_update]
end
subgraph arch/riscv/kvm/vm.c
ivm[kvm_arch_init_vm]
check_ext[kvm_vm_ioctl_check_extension]
end
subgraph virt/kvm/kvm_main.c
cvm[kvm_create_vm]
mem[kvm_mmu_topup_memory_cache]
dev_vm[kvm_dev_ioctl_create_vm]
dev[kvm_dev_ioctl]
init[kvm_init]
set_gfn-->mn_pte[kvm_mmu_notifier_change_pte]
flush_shadow-->flush_all[kvm_flush_shadow_all]
cvm-->dev_vm
dev_vm-->dev
end
dev-->external_call[kvmtool, etc.]
subgraph arch/riscv/kvm/vcpu_exit.c
pgfault[gstage_page_fault]
end
subgraph arch/riscv/kvm/main.c
rkinit[riscv_kvm_init]
archi[kvm_arch_init]
end
archi-->init-->rkinit
subgraph arch/riscv/kvm/tlb.c
tlb_sntz[kvm_riscv_local_tlb_sanitize]
end
subgraph arch/riscv/kvm/vcpu.c
run[kvm_arch_vcpu_ioctl_run]
load[kvm_arch_vcpu_load]
check_vcpu_req[kvm_riscv_check_vcpu_requests]
end
alloc_pgd-->ivm
vmid_init-->ivm
free_pgd-->ivm
ivm-->cvm
gmap-->pgfault
mode_dtct-->archi
vmid_dtct-->archi
mode-->archi
bits-->archi
bits-->update_hgatp
bits-->tlb_sntz
vmid_change-->run
update-->run
gpa_bits-->check_ext
update_hgatp-->load
update_hgatp-->check_vcpu_req
mem-->gmap
kvmtool
kvmtool 为 Guest 申请内存的操作,并不涉及太多特定架构的虚拟化实现细节,其初始化 VM 内存的函数如下所示:
// riscv/kvm.c: line 64
void kvm__arch_init(struct kvm *kvm)
{
/* 申请 Guest 内存。Buffer 做 64K 对齐,如使用了 THP(Transparent Huge Page)则按 2M 对齐 */
/* 确定 Guest 内存的起始位置与大小 */
kvm->ram_size = min(kvm->cfg.ram_size, (u64)RISCV_MAX_MEMORY(kvm));
kvm->arch.ram_alloc_size = kvm->ram_size + SZ_2M;
kvm->arch.ram_alloc_start = mmap_anon_or_hugetlbfs(kvm,
kvm->cfg.hugetlbfs_path,
kvm->arch.ram_alloc_size);
if (kvm->arch.ram_alloc_start == MAP_FAILED)
die("Failed to map %lld bytes for guest memory (%d)",
kvm->arch.ram_alloc_size, errno);
kvm->ram_start = (void *)ALIGN((unsigned long)kvm->arch.ram_alloc_start,
SZ_2M);
/* 为 Guest 申请特定类型的内存 */
madvise(kvm->arch.ram_alloc_start, kvm->arch.ram_alloc_size,
MADV_MERGEABLE);
madvise(kvm->arch.ram_alloc_start, kvm->arch.ram_alloc_size,
MADV_HUGEPAGE);
}
结语
本文对 KVM 如何实现 RISC-V G-Stage 地址转换进行了分析,包括为 Guest 申请内存、处理 G-Stage 页错误、使用 HFENCE 指令管理内存、更新 HGATP 寄存器和释放 VM 的内存,后续可作为 RISC-V 虚拟化软件实现的参考。
参考资料
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- Stratovirt 的 RISC-V 虚拟化支持(六):PLIC 和 串口支持
- Stratovirt 的 RISC-V 虚拟化支持(五):BootLoader 和设备树
- Stratovirt 的 RISC-V 虚拟化支持(四):内存模型和 CPU 模型
- Stratovirt 的 RISC-V 虚拟化支持(三):KVM 模型
- Stratovirt 的 RISC-V 虚拟化支持(二):库的 RISC-V 适配

{kind=link}
{kind=link}