

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
RISC-V 内存虚拟化简析(二)
Corrector: TinyCorrect v0.1-rc3 - [tables epw] Author: XiakaiPan 13212017962@163.com Date: 2022/08/12 Revisor: walimis, Falcon Project: RISC-V Linux 内核剖析 Proposal: RISC-V 虚拟化技术调研与分析 Sponsor: PLCT Lab, ISCAS
前言
本文尝试解读 RISC-V 指令集中为了实现更细粒度内存管理而引入的扩展指令集 Svinval,分析 S-Mode 和 H-Mode 下的地址转换机制及其模拟器实现,最终给出内存管理相关 CSR 及指令在硬件实现层面的作用机制。
S 模式下的虚拟内存
Sv32 虚拟内存系统
虚拟地址和物理地址
SvX 表示存储系统中使用 X 位的虚拟地址,不同位数的虚拟地址对应的物理地址的位宽也会有所不同(Sv32 的 PA 位宽为 34,其它均为 56 位),除去 VA 和 PA 中的 12 位 Page Offset,每个页表项(PTE)实际存储的是物理页号(PPN)。对应页表项中 PPN 的位宽为 22(Sv32)或 44(Sv39,Sv48,Sv57)。
虚拟地址、物理地址、页表项示意图如下。
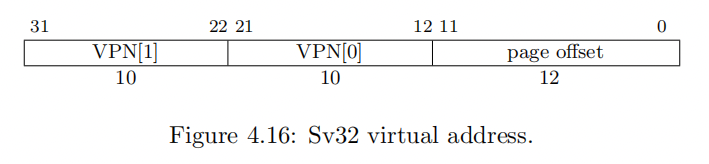




页表项
页表项的主体是其内部存储的 PPN 和协助地址转换的各个标志位,其中标志位位于 [7:0] 区域。RSW[9:8] 在实现时可以忽略,这些标志位是所有页表项共有的,PPN 位宽有所不同。现将标志位所在位置及其功能整理如下:
| 名称 | 位 | 功能 |
|---|---|---|
| V | 0 | PTE 是否有效 |
| R | 1 | 权限位,是否可读 |
| W | 2 | 权限位,是否可写 |
| X | 3 | 权限位,是否可执行 |
| U | 4 | 该页在 U-Mode 是否可访问 |
| G | 5 | 是否为全局映射 (无 ASID,不会被 TLB 刷新) |
| A | 6 | 是否被访问(Access)过 |
| D | 7 | 是否被写入变成脏页(Dirty) |
| RSW | [9:8] | 保留位用于内核态软件;实现时可忽略 |
R/W/X 编码及其功能总结如下:
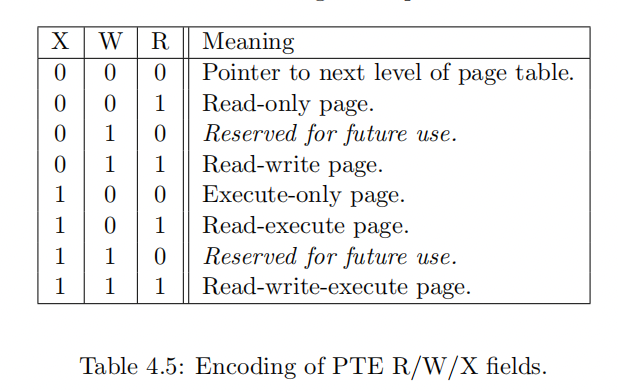
R/W/X 位对应的可能的异常有如下情况:
| 访问行为 | 权限 | 异常 |
|---|---|---|
| fetch an instruction from a page(页内取指令) | page does not have execute permissions(无执行权限) | fetch page-fault exception |
| execute a load or load-reserved instruction(执行加载或加载保留指令) | instruction’s effective address lies within a page without read permissions(指令所需地址位于无读权限的页内) | load page-fault exception |
| execute a store, store-conditional, or AMO instruction(执行加载、条件加载或原子指令) | instruction’s effective address lies within a page without write permissions(指令所需地址位于无写权限的页内) | store page-fault exception |
地址转换过程(以 Sv32 为例)
常量定义
用 PAGESIZE 表示页的大小,LEVELS 表示页表级别,根页表级别最高,PTESIZE 表示页中的一个页表项的大小。
对于 Sv32,其大小做如下规定:\[PAGESIZE=4KiB=2^{12} Bytes\]\[{LEVELS}=2\]\[PTESIZE=4 Bytes\]
过程图示
从虚拟地址到物理地址的转换过程如下图所示:
flowchart
1[1. Initialization: a = satp.ppn x PAGESIZE, i = LEVELS-1]
2.1[2.1. pte = PTE at address a+va.ppn_i x PTESIZE]
2.2{2.2 Whether pte accessing not violates PMA or PMP}
AFE[Access-Fault Exception]
3{3. Whether pte is valid? pte.v}
PFE[Page-Fault Exception]
1--->2.1--->2.2--Yes-->3--No-->PFE
2.2--->AFE
3--Yes-->4
4{4. Whether a leaf PTE? i := i-1}
4--Yes-->5
4--No: a = pte.ppn x PAGESIZE-->2.1
4--i < 0-->PFE
5{5. Whether memory accessible?} --No-->PFE
5--Yes: pte.r=1 or pte.x=1--->6
6{6. Whether superpage misaligned?}---No-->PFE
6--Yes-->7
7{7. Whether pte is valid-pte.a, pte.d?}--No-->PFE
7--Yes-->
8{8. Whether superpage? i>0}
8--Yes-->SPG
8--No-->NSPG
SPG[Superpage Translation]
NSPG[Normal Translation: pa.ppn=pte.ppn, pa.pgoff =va.pgoff]
步骤详解
该转换过程中的细节解释如下:
- 初始化:a 用于表示根页表的物理地址,i 用于索引虚拟地址的 VPN 所指示的特定层级页表的页表项偏移。通过 $PAGESIZE \times satp.PPN$ 可以得到根页表所在的起始地址,通过 $va.VPN[LEVELS-1] \times PTESIZE$ 可以得到在上述找到的根页表中存储了下一级页表的页表项。
- PMA or PMP check 即物理内存的属性和保护检查,此处暂不做讨论。
PTE.V表示该页表项是否有效,如果有针对该页表项所指示的最终地址处的数据的 Store 操作,将会导致对应页表项全部无效,也就是将其 V 位设置为 0,后续访问就可以据此判断当前页表项是否有效。具体的更新策略有待进一步讨论。- 当且仅当 PTE 的 R/W/X 位均为 0 时,该页表项指向下一级页表,否则,当前 PTE 即为可读或可执行的页表,也就是 0 级页表,可以从中获得 PPN,配合 va 进而得到最终要访问的物理地址。
- 判断 PTE 所指示的内存区域是否可访问需要结合 PTE 的 R/W/X 位、U 位和当前所在的特权级、
mstatus.SUM和mstatus.MXR位来判断。其中 U 位用来确定 PTE 是否能够被处于 U-Mode 的程序访问,mstatus.SUM用来确定是否允许 S-Mode 的程序访问,mstatus.MXR用于表示标记为可执行(eXecutable)的页表是否可读,若为 0 则不可读,只能够访问标记为可读(readable)的页表项,若为 1 则二者均可访问。 - 如果 $i > 0$ 并且 $pte.ppn[i − 1: 0] \neq 0$,视为未对齐的超级页。超级页此处亦不做讨论。
- 如果 a 为 0,或当前访存操作为写且 d 为 0,有不同的处理方式,最直接的可以抛出页错误的异常。
- 若 i=0,则可以通过 $pa.page_offset = va.page_offset$,$pa.ppn[LEVELS-1:0] = pte.[LEVELS-1:0]$ 获得最终要访问的物理地址;若 i>0,则为超级页(superpage)访问,偏移量不变,但物理地址的物理页号将有所不同:$pa.ppn[i − 1: 0] = va.vpn[i − 1: 0]$。
其它虚拟地址系统
Page Size(页大小): 4 KiB Page Offset(页偏移量): 12 bits
VA:Virtual Address(虚拟地址);VPN:Virtual Page Number(虚拟页号); PA:Physical Address(物理地址);PPN:Physical Page Number(物理页号); PTE:Page Table Entry(页表项)
| Sv32 | Sv39 | Sv48 | Sv57 | |
|---|---|---|---|---|
| 页表级数 | 2 | 3 | 4 | 5 |
| VA 位宽 | 32 | 39 | 48 | 57 |
| VPN 位宽 | 20 | 27 | 36 | 45 |
| PA 位宽 | 34 | 56 | 56 | 56 |
| PPN 位宽 | 22 | 44 | 44 | 44 |
| PTE 位宽 | 32 | 64 | 64 | 64 |
H 扩展中的内存管理:两阶段地址转换
概览
在虚拟机里的虚拟地址访问需要经历 VS 和 G 两个阶段的转换,这两个阶段分别由 CSR vsatp 和 hgatp 控制,完成从原始虚拟地址(original virtual address, VA)到客户机物理地址(guest physical address, GPA)再到监视器物理地址(supervisor physical address, SPA)的转换,分别记作 VS-Stage 和 G-Stage,过程如下右图所示,左图为 S-Mode 的地址转换示意图。
graph
subgraph H-Mode 2-Stage Address Translation
ova[original virtual address in VS-Mode or VU-Mode]--conversion controlled by CSR vsatp-->gpa[guest physical address]
gpa--conversion controlled by CSR hgatp-->hpa[supervisor physical address]
end
subgraph S-Mode Address Translation
va[virtual address]--conversion controlled by CSR satp --->pa[physical address]
end
此处的 supervisor physical address 为特权指令集里的说法,可以理解为被 hypervisor 管理的物理地址(Hypervisor Physical Address)。后续将使用 Hypervisor Physical Address 来表示最终的两阶段地址转换结果而非指令集里所用的 Supervisor Physical Address。
两阶段地址转换对应的内存抽象模式可以归纳为如下左图,对应的两阶段地址转换就可以反向还原为如下右图所示:
flowchart
subgraph Review of 2-Stage Address Translation
direction TB
ova[Original Virtual Address]--vsatp-->gpa[Guest Physical Address / Hypervisor Virtual Address]
gpa--hgatp-->hpa[Hypervisor Physical Address]
hpa-.Hardware Access.->pa[(Physical Memory)]
end
subgraph H-Mode Memory Abstraction
direction BT
pm[(Physical Memory)]-.Organized by Hypervisor.->spm[Page-Based Hypervisor Virtual Memory]
spm--Assigned by Hypervisor to Guests/VMs-->gvm[Guest Physical Memory]
gvm--Assigned by VM OS-->pva[Guest Virtual Memory]
end
虚拟模式(Virtual Mode)为 1 时,两级地址转换及保护视作生效状态,如果需要让这一机制失效只需要将 vsatp 和 hgatp 置零。
当 V=1 时,绕过地址转换的内存访问(如不通过 VS-Stage 转换,直接对 VS 级页表进行读写的操作)将只与 G-Stage 转换有关。
VS-Stage
VS-Stage 的地址转换与 S-Mode 下的大致相同,但在执行地址转换时将会从 vsatp 处取得根页表地址,这与 S-Mode 下从 satp 获取有所不同。
G-Stage
G-Stage 的地址转换由 hgatp 控制,是原有的基于页表的地址转换机制的变体。不同之处在于该阶段的 虚拟地址(在 G-Stage 中称为 Guest Physical Address)相较于原有的地址转换机制需要扩宽两位,指令集里将其称之为 Sv32x4, Sv39x4, Sv48x4,和 Sv57x4 转换机制。与之对应的根页表的大小也随之扩大至 16 KiB 而非原来的 4 KiB,但其它各级页表的大小保持不变。根页表也需要与 16 KiB 的页边界对齐。
除了如下方面,地址转换算法保持不变:
hgatp代替satp用于获取根页表的 PPN。- 这一阶段翻译的起始特权级应该 VU 或 VS,即处于虚拟态,V=1。
- 当进行 PTE.U(页表项中表示是否可被 U-Mode 程序访问)的访问时,特权级会变为 U-Mode,即所有的内存访问都被视为 U-Mode 的访问。
- 出现异常时将会是
guest-page-fault exceptions而非page-fault exceptions。
RISC-V 地址转换机制在 Spike 中的实现
此节将结合上述对地址转换机制的规范解读,分析其在指令集模拟器 Spike 中的实现。
Spike 中的地址转换机制称之为 Page Table Walk,在 riscv/mmu.cc 和 riscv/mmu.h 中实现,相关函数及调用关系如下图所示:
flowchart LR
va((vaddr))-->a[access: fetch/load/store_slow_path]
a-.addr.->t
t[[translate]]-.addr.->w[[Normal PTW-satp: walk]]-.level==0.->gptw[[GStage PTW-hgatp: s2xlate]]
w-.level != 0.->w
rtlb[refill_tlb]
a-.addr.->rtlb
t-- paddr -->rtlb
w-- paddr-->t
subgraph Page Table Walk
w
gptw
end
其中,mmu 私有成员函数 fetch_slow_path(), load_slow_path(), store_slow_path() 调用 translate() 函数获取指定(虚拟)地址的物理地址(Physical Address, paddr)并将虚拟、物理地址对通过调用 refill_tlb() 函数添加到 TLB 中予以保存。translate() 是通过调用 walk 函数获得最终的物理地址的。在 walk 函数中,如果遇到涉及需要第二阶段地址转换即 G-Stage 转换,就会调用 s2xlate 函数进行转换。
其中 translate 函数声明及定义如下:
// riscv/mmu.cc: line 51
reg_t mmu_t::translate(reg_t addr, reg_t len, access_type type, uint32_t xlate_flags)
{
// ...
// 调用 walk() 函数获得物理地址
reg_t paddr = walk(addr, type, mode, virt, hlvx) | (addr & (PGSIZE-1));
// PMP(Physical Memory Protection)检查
if (!pmp_ok(paddr, len, type, mode))
throw_access_exception(virt, addr, type);
return paddr;
}
walk 函数声明及定义如下:
// riscv/mmu.h: line 443
reg_t walk(reg_t addr, access_type type, reg_t prv, bool virt, bool hlvx);
// riscv/mmu.cc: line 358
reg_t mmu_t::walk(reg_t addr, access_type type, reg_t mode, bool virt, bool hlvx)
{
reg_t page_mask = (reg_t(1) << PGSHIFT) - 1; /* PGSHIFT=12 */
reg_t satp = proc->get_state()->satp->readvirt(virt);
vm_info vm = decode_vm_info(proc->get_const_xlen(), false, mode, satp);
if (vm.levels == 0)
return s2xlate(addr, addr & ((reg_t(2) << (proc->xlen-1))-1), type, type, virt, hlvx) & ~page_mask; // zero-extend from xlen
bool s_mode = mode == PRV_S;
bool sum = proc->state.sstatus->readvirt(virt) & MSTATUS_SUM;
bool mxr = (proc->state.sstatus->readvirt(false) | proc->state.sstatus->readvirt(virt)) & MSTATUS_MXR;
// verify bits xlen-1:va_bits-1 are all equal
int va_bits = PGSHIFT + vm.levels * vm.idxbits;
reg_t mask = (reg_t(1) << (proc->xlen - (va_bits-1))) - 1;
reg_t masked_msbs = (addr >> (va_bits-1)) & mask;
if (masked_msbs != 0 && masked_msbs != mask)
vm.levels = 0;
reg_t base = vm.ptbase;
for (int i = vm.levels - 1; i >= 0; i--) {
int ptshift = i * vm.idxbits;
reg_t idx = (addr >> (PGSHIFT + ptshift)) & ((1 << vm.idxbits) - 1);
// check that physical address of PTE is legal
auto pte_paddr = s2xlate(addr, base + idx * vm.ptesize, LOAD, type, virt, false);
auto ppte = sim->addr_to_mem(pte_paddr);
if (!ppte || !pmp_ok(pte_paddr, vm.ptesize, LOAD, PRV_S))
throw_access_exception(virt, addr, type);
reg_t pte = vm.ptesize == 4 ? from_target(*(target_endian<uint32_t>*)ppte) : from_target(*(target_endian<uint64_t>*)ppte);
reg_t ppn = (pte & ~reg_t(PTE_ATTR)) >> PTE_PPN_SHIFT;
bool pbmte = virt ? (proc->get_state()->henvcfg->read() & HENVCFG_PBMTE) : (proc->get_state()->menvcfg->read() & MENVCFG_PBMTE);
if (pte & PTE_RSVD) {
break;
} else if (!proc->extension_enabled(EXT_SVNAPOT) && (pte & PTE_N)) {
break;
} else if (!pbmte && (pte & PTE_PBMT)) {
break;
} else if ((pte & PTE_PBMT) == PTE_PBMT) {
break;
} else if (PTE_TABLE(pte)) { // next level of page table
if (pte & (PTE_D | PTE_A | PTE_U | PTE_N | PTE_PBMT))
break;
base = ppn << PGSHIFT;
} else if ((pte & PTE_U) ? s_mode && (type == FETCH || !sum) : !s_mode) {
break;
} else if (!(pte & PTE_V) || (!(pte & PTE_R) && (pte & PTE_W))) {
break;
} else if (type == FETCH || hlvx ? !(pte & PTE_X) :
type == LOAD ? !(pte & PTE_R) && !(mxr && (pte & PTE_X)) :
!((pte & PTE_R) && (pte & PTE_W))) {
break;
} else if ((ppn & ((reg_t(1) << ptshift) - 1)) != 0) {
break;
} else {
reg_t ad = PTE_A | ((type == STORE) * PTE_D);
#ifdef RISCV_ENABLE_DIRTY
// set accessed and possibly dirty bits.
if ((pte & ad) != ad) {
if (!pmp_ok(pte_paddr, vm.ptesize, STORE, PRV_S))
throw_access_exception(virt, addr, type);
*(target_endian<uint32_t>*)ppte |= to_target((uint32_t)ad);
}
#else
// take exception if access or possibly dirty bit is not set.
if ((pte & ad) != ad)
break;
#endif
// for superpage or Svnapot NAPOT mappings, make a fake leaf PTE for the TLB's benefit.
reg_t vpn = addr >> PGSHIFT;
int napot_bits = ((pte & PTE_N) ? (ctz(ppn) + 1) : 0);
if (((pte & PTE_N) && (ppn == 0 || i != 0)) || (napot_bits != 0 && napot_bits != 4))
break;
reg_t page_base = ((ppn & ~((reg_t(1) << napot_bits) - 1))
| (vpn & ((reg_t(1) << napot_bits) - 1))
| (vpn & ((reg_t(1) << ptshift) - 1))) << PGSHIFT;
reg_t phys = page_base | (addr & page_mask);
return s2xlate(addr, phys, type, type, virt, hlvx) & ~page_mask;
}
}
switch (type) {
case FETCH: throw trap_instruction_page_fault(virt, addr, 0, 0);
case LOAD: throw trap_load_page_fault(virt, addr, 0, 0);
case STORE: throw trap_store_page_fault(virt, addr, 0, 0);
default: abort();
}
}
s2xlate 函数声明及定义如下:
// 对给定的虚拟地址进行第二阶段(G-Stage)的转换
// perform a stage2 translation for a given guest address
reg_t s2xlate(reg_t gva, reg_t gpa, access_type type, access_type trap_type, bool virt, bool hlvx);
reg_t mmu_t::s2xlate(reg_t gva, reg_t gpa, access_type type, access_type trap_type, bool virt, bool hlvx)
{
if (!virt)
return gpa;
vm_info vm = decode_vm_info(proc->get_const_xlen(), true, 0, proc->get_state()->hgatp->read());
if (vm.levels == 0)
return gpa;
int maxgpabits = vm.levels * vm.idxbits + vm.widenbits + PGSHIFT;
reg_t maxgpa = (1ULL << maxgpabits) - 1;
bool mxr = proc->state.sstatus->readvirt(false) & MSTATUS_MXR;
reg_t base = vm.ptbase;
if ((gpa & ~maxgpa) == 0) {
for (int i = vm.levels - 1; i >= 0; i--) {
int ptshift = i * vm.idxbits;
int idxbits = (i == (vm.levels - 1)) ? vm.idxbits + vm.widenbits : vm.idxbits;
reg_t idx = (gpa >> (PGSHIFT + ptshift)) & ((reg_t(1) << idxbits) - 1);
// check that physical address of PTE is legal
auto pte_paddr = base + idx * vm.ptesize;
auto ppte = sim->addr_to_mem(pte_paddr);
if (!ppte || !pmp_ok(pte_paddr, vm.ptesize, LOAD, PRV_S)) {
throw_access_exception(virt, gva, trap_type);
}
reg_t pte = vm.ptesize == 4 ? from_target(*(target_endian<uint32_t>*)ppte) : from_target(*(target_endian<uint64_t>*)ppte);
reg_t ppn = (pte & ~reg_t(PTE_ATTR)) >> PTE_PPN_SHIFT;
bool pbmte = proc->get_state()->menvcfg->read() & MENVCFG_PBMTE;
if (pte & PTE_RSVD) {
break;
} else if (!proc->extension_enabled(EXT_SVNAPOT) && (pte & PTE_N)) {
break;
} else if (!pbmte && (pte & PTE_PBMT)) {
break;
} else if ((pte & PTE_PBMT) == PTE_PBMT) {
break;
} else if (PTE_TABLE(pte)) { // next level of page table
if (pte & (PTE_D | PTE_A | PTE_U | PTE_N | PTE_PBMT))
break;
base = ppn << PGSHIFT;
} else if (!(pte & PTE_V) || (!(pte & PTE_R) && (pte & PTE_W))) {
break;
} else if (!(pte & PTE_U)) {
break;
} else if (type == FETCH || hlvx ? !(pte & PTE_X) :
type == LOAD ? !(pte & PTE_R) && !(mxr && (pte & PTE_X)) :
!((pte & PTE_R) && (pte & PTE_W))) {
break;
} else if ((ppn & ((reg_t(1) << ptshift) - 1)) != 0) {
break;
} else {
reg_t ad = PTE_A | ((type == STORE) * PTE_D);
#ifdef RISCV_ENABLE_DIRTY
// set accessed and possibly dirty bits.
if ((pte & ad) != ad) {
if (!pmp_ok(pte_paddr, vm.ptesize, STORE, PRV_S))
throw_access_exception(virt, gva, trap_type);
*(target_endian<uint32_t>*)ppte |= to_target((uint32_t)ad);
}
#else
// take exception if access or possibly dirty bit is not set.
if ((pte & ad) != ad)
break;
#endif
reg_t vpn = gpa >> PGSHIFT;
reg_t page_mask = (reg_t(1) << PGSHIFT) - 1;
int napot_bits = ((pte & PTE_N) ? (ctz(ppn) + 1) : 0);
if (((pte & PTE_N) && (ppn == 0 || i != 0)) || (napot_bits != 0 && napot_bits != 4))
break;
reg_t page_base = ((ppn & ~((reg_t(1) << napot_bits) - 1))
| (vpn & ((reg_t(1) << napot_bits) - 1))
| (vpn & ((reg_t(1) << ptshift) - 1))) << PGSHIFT;
return page_base | (gpa & page_mask);
}
}
}
switch (trap_type) {
case FETCH: throw trap_instruction_guest_page_fault(gva, gpa >> 2, 0);
case LOAD: throw trap_load_guest_page_fault(gva, gpa >> 2, 0);
case STORE: throw trap_store_guest_page_fault(gva, gpa >> 2, 0);
default: abort();
}
}
内存管理指令扩展 INVAL
S 扩展内存管理指令对应指令
Svinval 标准扩展用于实现更细粒度的地址转换和 TLB 无效化操作,参见 特权指令级手册 第七章。该扩展将 SFENCE.VMA,HFENCE.VVMA 和 HFENCE.GVMA 三条指令拆分成了更细粒度的操作,这些操作可以在特定的高性能 ISA 实现中进行更高效的批量化和流水线化处理。
与 SFENCE.VMA 相关的指令有 SINVAL.VMA,SFENCE.W.INVAL 和 SFENCE.INVAL.IR。其指令结构如下所示:


三条指令作用如下:
SINVAL.VMA用于无效化所有SFENCE.VMA需要进行无效化操作的 TLB 项。SFENCE.W.INVAL指令用于确保所有的存储操作(Stores, W)的完成发生在后续的SINVAL.VMA指令(INVAL)执行之前。SFENCE.INVAL.IR用于保证无效化操作(INVAL)发生在后续的隐式访存(Implicit References, IR)之前。
据此,可以归纳出如下的操作执行次序:SFENCE.W.INVAL 用于确保写操作发生在 TLB 对应项被无效化之前(以避免 TLB miss 之后进行耗时更长的 PTW(Page Table Walk)获取最终物理地址再写入缓存),SFENCE.INVAL.IR 用于确保 TLB 无效化操作发生在读取操作之前(以避免从 TLB 中获取错误的物理地址进而取得错误数据)。SINVAL.VMA 本身则可以视为将 SFENCE.VMA 指令的无效化 TLB 特定项的功能进行单独拆分得到的指令。
对于一个单独的硬件线程(hart, HARdware Thread),按照 SFENCE.W.INVAL, SINVAL.VMA, SFENCE.INVAL.IR 的次序执行上述三条指令,其效果与执行一个假定的 SFENCE.VMA 指令相同,具体而言,三条指令分别完成了如下的与 SFENCE.VMA 指令相同的功能:
SFENCE.VMA通过rs1和rs2的值确定要执行无效化操作的 TLB 项,对应与之俱有相同rs1和rs2值的SINVAL.VMA的执行效果;- 被序列化之后的先于
SFENCE.W.INVAL的读写操作,与被序列化之后的先于SFENCE.VMA的读写操作相同; - 被序列化之后的在
SFENCE.W.INVAL之后执行的读写操作,与被序列化之后的在SFENCE.VMA之后执行的读写操作相同。
单一 hart 的访存操作经过上述指令处理之后,其执行顺序如下图所示,SFENCE.VMA 的执行效果相当于按照次序执行另外三条内存管理指令:
flowchart LR
w[(stores, W)]--SFENCE.W.INVAL---iv[SINVAL.VMA] --SFENCE.INVAL.IR---- r[(implicit references, IR)]
w-..-s[[SFENCE.VMA]]-..-r
H 扩展内存管理指令对应指令
HINVAL.VVMA 和 HINVAL.GVMA 指令与 SINVAL.VMA 结构相同,除了 HINVAL.GVMA 指令的 rs1 和 rs2 分别对应 vmid 和 gaddr 而非 asid 和 vaddr,如下图所示:
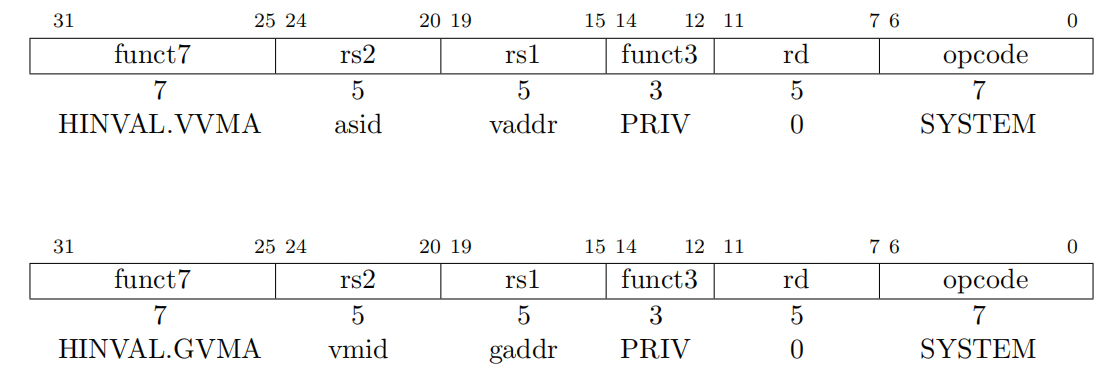
上述两条指令与 SINVAL.VMA 和 SFENCE.INVAL.IR 组合可实现 HFENCE.VVMA 和 HFENCE.GVMA 的功能,如下图所示:
flowchart LR
w[(stores, W)]--SFENCE.W.INVAL---viv[HINVAL.VVMA] --SFENCE.INVAL.IR---- r[(implicit references, IR)]
w-..-s[[HFENCE.VVMA]]-..-r
flowchart LR
w[(stores, W)]--SFENCE.W.INVAL---giv[HINVAL.GVMA] --SFENCE.INVAL.IR---- r[(implicit references, IR)]
w-..-s[[HFENCE.GVMA]]-..-r
相关异常
SINVAL.VMA, HINVAL.VVMA 和 HINVAL.GVMA 指令执行时所需权限即抛出的异常与 SFENCE.VMA, HFENCE.VVMA 和 HFENCE.GVMA 对应一致,如下表所示:
| SINVAL.VMA | HINVAL.VVMA | HINVAL.GVMA | Privilege Mode(特权级) | Exception(异常) |
|---|---|---|---|---|
| ✅ | ✅ | ✅ | U | illegal instruction exception |
| ✅ | ✅ | S/HS when mstatus.TVM=1 | illegal instruction exception | |
| ✅ | ✅ | VS/VU | virtual instruction exception | |
| ✅ | VU | virtual instruction exception | ||
| ✅ | VS when hstatus.VTVM=1 | virtual instruction exception |
SFENCE.W.INVAL 和 SFENCE.INVAL.IR 指令并无指令可见性修改作用,所以在 mstatus.TVM=1 或 hstatus.VTVM=1 时不会造成 trap。
一个典型的使用场景是,软件如需要无效化一系列虚拟地址对应的的 TLB 项,则需要按照如下次序执行指令:
flowchart LR
wi[SFENCE.W.INVAL]-->i[SINVAL.VMA, HINVAL.VVMA, or HINVAL.GVMA]-->ir[SFENCE.INVAL.IR]
高性能的处理器设计能够将上述操作流水线化,并将任何流水线暂停操作或强制序列化访存操作延后,直至上述指令序列执行完成。
更加简单的实现 中,SFENCE.W.INVAL 和 SFENCE.INVAL.IR 实现为无操作(no-ops),SINVAL.VMA, HINVAL.VVMA 和 HINVAL.GVMA 则与 SFENCE.VMA, HFENCE.VVMA,和 HFENCE.GVMA 相同。
模拟器实现
Spike 对上述指令的实现即参考上述简化实现,如下表所示:
| Svinval 指令 | 实现 |
|---|---|
| SFENCE.W.INVAL | no-op |
| SINVAL.VMA | SFENCE.VMA |
| HINVAL.VVMA | HFENCE.VVMA |
| HINVAL.GVMA | HFENCE.GVMA |
| SFENCE.INVAL.IR | no-op |
参考资料
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- Stratovirt 的 RISC-V 虚拟化支持(六):PLIC 和 串口支持
- Stratovirt 的 RISC-V 虚拟化支持(五):BootLoader 和设备树
- Stratovirt 的 RISC-V 虚拟化支持(四):内存模型和 CPU 模型
- Stratovirt 的 RISC-V 虚拟化支持(三):KVM 模型
- Stratovirt 的 RISC-V 虚拟化支持(二):库的 RISC-V 适配

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}