

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
Qemu vhost 原理分析
Gao Chengbo 创作于 2020/05/26
By Chengbo of TinyLab.org May 13, 2020
技术简介
virtio-net 简介
virtio-net 在 guest 前端驱动 kick 后端驱动时,采用 I/O 指令方式退出到 host KVM。kvm 通过 eventfd_signal 唤醒阻塞的 qemu 线程。qemu 通过 vring 处理报文。qemu 把报文从用户态传送给 tap 口。
vhost-net 简介
与 virtio-net 不同的是,eventfd_signal 唤醒的是内核 vhost_worker 进程。vhost_worker 从 vring 提取报文数据,然后发送给 tap。与 virtio-net 相比,vhost-net 处理数据在内核态,在发送到 tap 口的时候少了一次数据的拷贝。
ovs 转发涉及的模块概要
VM->VM 流程:
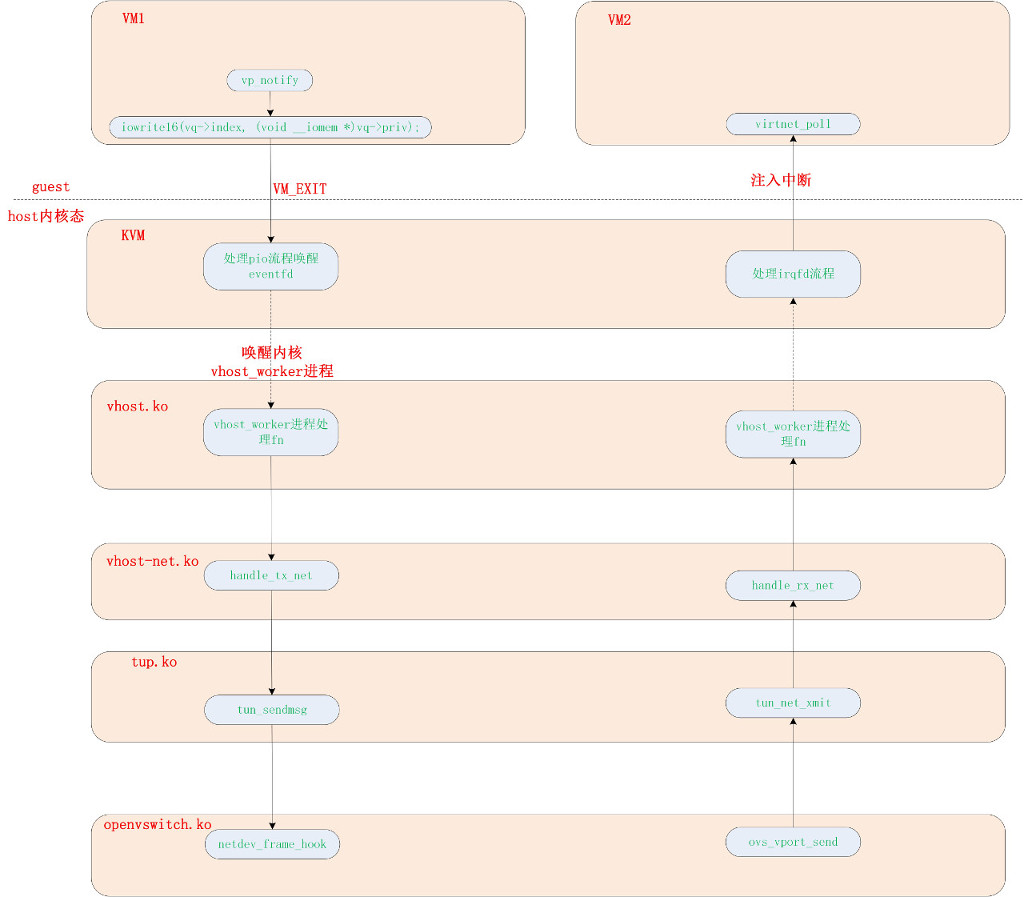
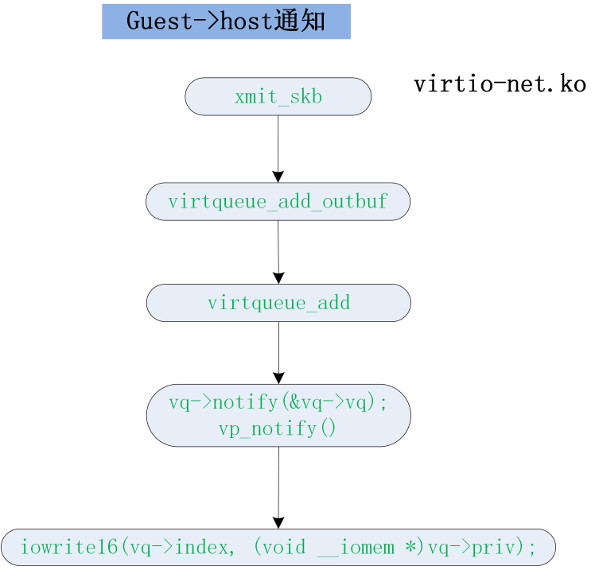
virtio-net.ko 前端驱动部分
guest->host 数据发送
当前端 virtio-net 有想发送的报文数据时将会 kick 后端,右面是前端 kick 后端的流程。前端调用 xmit_skb 发送数据,virtqueue_add_outbuf 是把 sk_buff 里的内容(frag[]数组)逐一的填入 scatterlist 数组中。这里可以理解成填写分散聚合描述符表。
但前端和后端数据传递是通过 struct vring_desc 传递的,所以 virtqueue_add() 再把 struct scatterlist 里的数据填写到 struct vring_desc 里。
struct vring_desc 这个数据结构的使用,后面我们再详细说。
最后通过 vq->notify(&vq->vq) (vp_notify()) kick 后端,后续流程到了 kvm.ko 部分的第 4 小节。
guest->host 代码流程
host->guest 数据发送
guest 通过 NAPI 接口的 virtnet_poll 接收数据,通过 virtqueue_get_buf_ctx 从 Vring 中获取报文数据。再通过 receive_buf 把报文数据保存到 skb 中。
这样目的端就成功接收了来自源端的报文。
host->guest 代码流程

kvm.ko 部分
eventfd 注册

由上图可见 eventfd 的注册是在 qemu 中发起的。qemu 调用 kvm 提供的系统调用。
eventfd 通知流程
eventfd 一半的用法是用户态通知用户态,或者内核态通知用户态。例如 virtio-net 的实现是 guest 在 kick host 时采用 eventfd 通知的 qemu,然后 qemu 在用户态做报文处理。但 vhost-net 是在内核态进行报文处理,guest 在 kick host 时采用 eventfd 通知的是内核线程 vhost_worker。所以这里的用法就跟常规的 eventfd 的用法不太一样。
下面介绍 eventfd 通知的使用。
eventfd 核心数据结构:
struct eventfd_ctx {
struct kref kref;
wait_queue_head_t wqh;
__u64 count;
unsigned int flags;
};
eventfd 的数据结构其实就是包含了一个等待队列头。当调用 eventfd_signal 函数时就是唤醒 wgh 上等待队列。
__u64 eventfd_signal(struct eventfd_ctx *ctx, __u64 n)
{
unsigned long flags;
spin_lock_irqsave(&ctx->wqh.lock, flags);
if (ULLONG_MAX - ctx->count < n)
n = ULLONG_MAX - ctx->count;
ctx->count += n;
if (waitqueue_active(&ctx->wqh))
wake_up_locked_poll(&ctx->wqh, POLLIN);
spin_unlock_irqrestore(&ctx->wqh.lock, flags);
return n;
}
#define wake_up_locked_poll(x, m) \
__wake_up_locked_key((x), TASK_NORMAL, (void *) (m))
void __wake_up_locked_key(struct wait_queue_head *wq_head, unsigned int mode, void *key)
{
__wake_up_common(wq_head, mode, 1, 0, key, NULL);
}
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,
int nr_exclusive, int wake_flags, void *key,
wait_queue_entry_t *bookmark)
{
...
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
unsigned flags = curr->flags;
int ret;
if (flags & WQ_FLAG_BOOKMARK)
continue;
ret = curr->func(curr, mode, wake_flags, key); /* 调用vhost_poll_wakeup */
if (ret < 0)
break;
if (ret && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
if (bookmark && (++cnt > WAITQUEUE_WALK_BREAK_CNT) &&
(&next->entry != &wq_head->head)) {
bookmark->flags = WQ_FLAG_BOOKMARK;
list_add_tail(&bookmark->entry, &next->entry);
break;
}
}
return nr_exclusive;
}
static int vhost_poll_wakeup(wait_queue_entry_t *wait, unsigned mode, int sync,
void *key)
{
struct vhost_poll *poll = container_of(wait, struct vhost_poll, wait);
if (!((unsigned long)key & poll->mask))
return 0;
vhost_poll_queue(poll);
return 0;
}
void vhost_poll_queue(struct vhost_poll *poll)
{
vhost_work_queue(poll->dev, &poll->work);
}
void vhost_work_queue(struct vhost_dev *dev, struct vhost_work *work)
{
if (!dev->worker)
return;
if (!test_and_set_bit(VHOST_WORK_QUEUED, &work->flags)) {
/* We can only add the work to the list after we're
* sure it was not in the list.
* test_and_set_bit() implies a memory barrier.
*/
llist_add(&work->node, &dev->work_list); /* 添加到 dev->work_list)*/
wake_up_process(dev->worker); /* 唤醒vhost_worker线程 */
}
}
这里有一个疑问,就是 vhost_worker 什么时候加入到 eventfd 的 wgh 字段的,__wake_up_common 函数里 curr->func 又是什么时候被设置成 vhost_poll_wakeup 函数的呢?请看下一节。
eventfd 与 vhost_worker 绑定
vhost.ko 创建了一个字符设备,vhost_net_open 在打开这个设备文件的时候会调用 vhost_net_open 函数。这里为 vhost_dev 设备进行初始化。
static int vhost_net_open(struct inode *inode, struct file *f)
{
...
dev = &n->dev;
vqs[VHOST_NET_VQ_TX] = &n->vqs[VHOST_NET_VQ_TX].vq;
vqs[VHOST_NET_VQ_RX] = &n->vqs[VHOST_NET_VQ_RX].vq;
n->vqs[VHOST_NET_VQ_TX].vq.handle_kick = handle_tx_kick;
n->vqs[VHOST_NET_VQ_RX].vq.handle_kick = handle_rx_kick;
...
vhost_poll_init(n->poll + VHOST_NET_VQ_TX, handle_tx_net, POLLOUT, dev);
vhost_poll_init(n->poll + VHOST_NET_VQ_RX, handle_rx_net, POLLIN, dev);
f->private_data = n;
return 0;
}
void vhost_poll_init(struct vhost_poll *poll, vhost_work_fn_t fn,
unsigned long mask, struct vhost_dev *dev)
{
init_waitqueue_func_entry(&poll->wait, vhost_poll_wakeup); /* 给curr->fn赋值 vhost_poll_wakeup */
init_poll_funcptr(&poll->table, vhost_poll_func); /* 给poll_table->_qproc赋值vhost_poll_func */
poll->mask = mask;
poll->dev = dev;
poll->wqh = NULL;
vhost_work_init(&poll->work, fn); /* 给 work->fn 赋值为handle_tx_net和handle_rx_net */
}
qemu 使用 ioctl 系统调用 VHOST_SET_VRING_KICK 时会把 eventfd 的 struct file 指针付给 pollstart 和 pollstop,同时调用 vhost_poll_start()。
long vhost_vring_ioctl(struct vhost_dev *d, int ioctl, void __user *argp)
{
...
case VHOST_SET_VRING_KICK:
if (copy_from_user(&f, argp, sizeof f)) {
r = -EFAULT;
break;
}
eventfp = f.fd == -1 ? NULL : eventfd_fget(f.fd);
if (IS_ERR(eventfp)) {
r = PTR_ERR(eventfp);
break;
}
if (eventfp != vq->kick) {
pollstop = (filep = vq->kick) != NULL;
pollstart = (vq->kick = eventfp) != NULL;
} else
filep = eventfp;
break;
...
if (pollstart && vq->handle_kick)
r = vhost_poll_start(&vq->poll, vq->kick);
...
}
int vhost_poll_start(struct vhost_poll *poll, struct file *file)
{
unsigned long mask;
int ret = 0;
if (poll->wqh)
return 0;
mask = file->f_op->poll(file, &poll->table); /* 执行eventfd_poll */
if (mask)
vhost_poll_wakeup(&poll->wait, 0, 0, (void *)mask);
if (mask & POLLERR) {
vhost_poll_stop(poll);
ret = -EINVAL;
}
return ret;
}
static unsigned int eventfd_poll(struct file *file, poll_table *wait)
{
struct eventfd_ctx *ctx = file->private_data;
unsigned int events = 0;
u64 count;
poll_wait(file, &ctx->wqh, wait);
。。。
}
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p); /* 调用vhost_poll_func */
}
static void vhost_poll_func(struct file *file, wait_queue_head_t *wqh,
poll_table *pt)
{
struct vhost_poll *poll;
poll = container_of(pt, struct vhost_poll, table);
poll->wqh = wqh;
add_wait_queue(wqh, &poll->wait);
}
关键数据结构关系如下图:
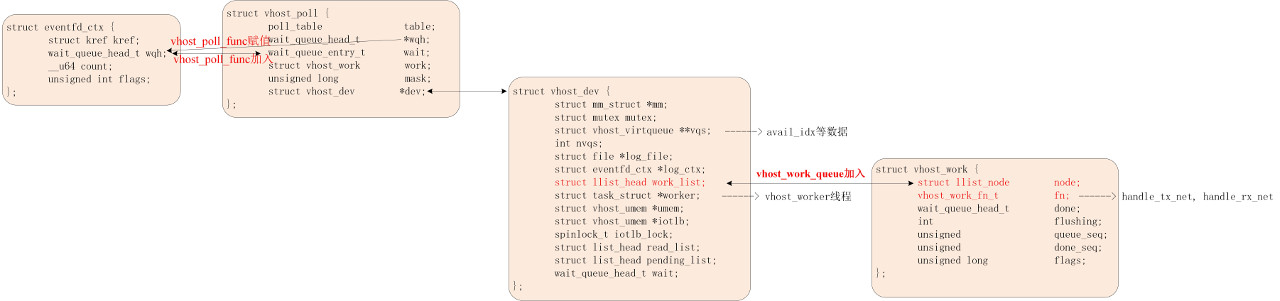
guest->host 的通知流程(唤醒 vhost_worker 线程)
Kick host 的原理是通过 io 指令实现的。前端执行 io 指令,就会发生 vm exit。KVM 捕捉到 vm exit 会去查询退出原因,由于是 io 指令,所以执行对应的 handle_io 处理。handle_io() 从 exit_qualification 中得到 io 操作地址。kvm_fast_pio_out() 会根据 io 操作的地址找到对应的处理函数。第 1 小节 eventfd 注册的流程可知,kvm_fast_pio_out() 最终会调用 eventfd 对应的回调函数 ioeventfd_write()。再根据第 3 小节可知 eventfd 最终会唤醒 vhost_worker 内核进程。
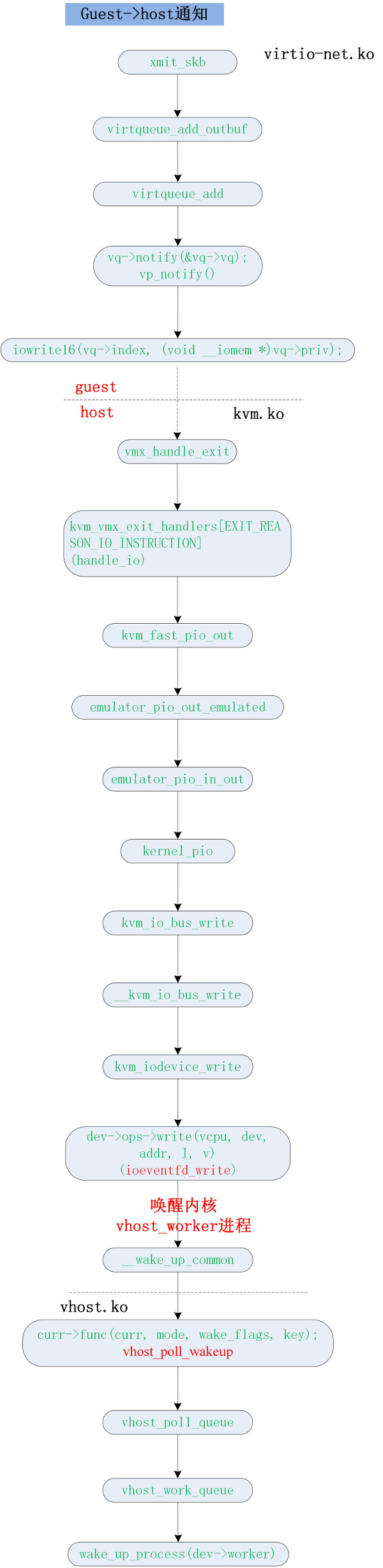
流程进入 vhost.ko 的第3小节。
host 给 guest 注入中断
到目前位置,发送给 guest 的报文已经准备好了。通过注入中断通知 guest 接收报文。这里要为虚机的 virtio-net 设备模拟一个 MSI 中断,并且准备了中断向量号。调用 vmx_deliver_posted_interrupt 给目的 VCPU 线程所在的物理核注入终端。
流程将跳转到 virtio-net.ko 前端驱动的第3小节。
host 给 guest 注入中断代码流程

vhost.ko 部分
前面有提到 vhost_worker 线程被唤醒后将执行 vhost_poll_init() 函数这册的 handle_tx_net 和 handle_rx_net 函数。
vhost_worker 线程创建
long vhost_dev_set_owner(struct vhost_dev *dev)
{
...
/* No owner, become one */
dev->mm = get_task_mm(current);
worker = kthread_create(vhost_worker, dev, "vhost-%d", current->pid);
if (IS_ERR(worker)) {
err = PTR_ERR(worker);
goto err_worker;
}
dev->worker = worker;
wake_up_process(worker); /* avoid contributing to loadavg */
err = vhost_attach_cgroups(dev);
if (err)
goto err_cgroup;
err = vhost_dev_alloc_iovecs(dev);
if (err)
goto err_cgroup;
...
}
让 vhost-dev 的 worker 指向刚创建出的 worker 线程。
vhost_worker 实现
static int vhost_worker(void *data)
{
struct vhost_dev *dev = data;
struct vhost_work *work, *work_next;
struct llist_node *node;
mm_segment_t oldfs = get_fs();
set_fs(USER_DS);
use_mm(dev->mm);
for (;;) {
/* mb paired w/ kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
if (kthread_should_stop()) {
__set_current_state(TASK_RUNNING);
break;
}
node = llist_del_all(&dev->work_list); /*vhost_work_queue 添加 */
if (!node)
schedule();
node = llist_reverse_order(node);
/* make sure flag is seen after deletion */
smp_wmb();
llist_for_each_entry_safe(work, work_next, node, node) {
clear_bit(VHOST_WORK_QUEUED, &work->flags);
__set_current_state(TASK_RUNNING);
work->fn(work); /* 由vhost_poll_init赋值 handle_tx_net和handle_rx_net*/
if (need_resched())
schedule();
}
}
unuse_mm(dev->mm);
set_fs(oldfs);
return 0;
}
从代码可以看到在循环的开始部分是摘除 dev->work_list 链表中的头表项。这里如果链表为空则返回 NULL,如果链表不为空则返回头结点。如果链表为空则调用 schedule() 函数 vhost_worker 进程进入阻塞状态,等待被唤醒。
当 vhost_worker 被唤醒后将执行 fn 函数,对于 vhost-net 将被赋值为 handle_tx_net 和 handle_rx_net。
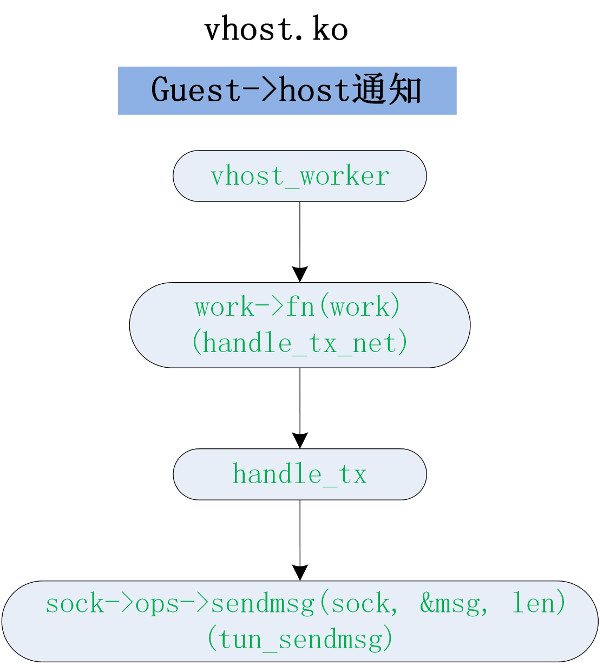
从 guest->host 方向的发送报文函数 handle_tx_net
handle_tx_net 的代码逻辑比较短,里面直接调用了 tun.ko 的接口函数发送报文。流程走到了 tun.ko 章节的第1小节。
static void handle_tx_net(struct vhost_work *work)
{
struct vhost_net *net = container_of(work, struct vhost_net,
poll[VHOST_NET_VQ_TX].work);
handle_tx(net);
}
static void handle_tx(struct vhost_net *net)
{
...
for (;;) {
...
/* TODO: Check specific error and bomb out unless ENOBUFS? */
err = sock->ops->sendmsg(sock, &msg, len); /* tup.c中定义 tup_sendmsg ()*/
if (unlikely(err < 0)) {
...
}
out:
mutex_unlock(&vq->mutex);
}
guest->host 代码流程
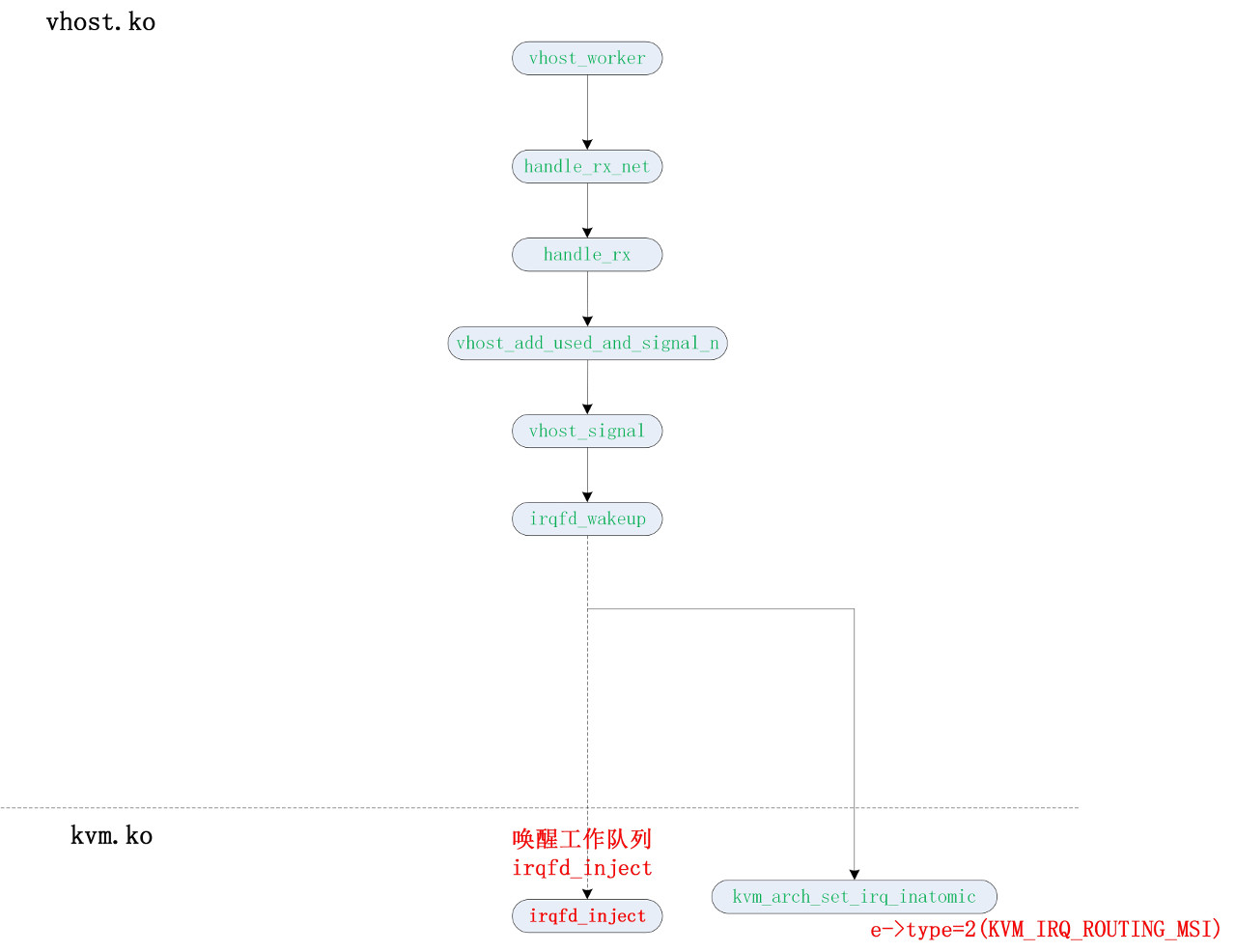
从 host->guest 方向的接收
vhost-worker 进程调用 handle_rx_net。vhost_add_used_and_signal_n 负责从 vring 中接收报文,vhost_signal 函数通知 guest 报文的到来。目前都是通过注入中断的方式通知 guest。
流程将跳转到 kvm.ko 的第5小节。
host->guest 代码流程
host->guest 方向:
tun.ko 部分
报文发送处理流程

tun 模块首先通过调用 __napi_schedue() 接口去挂起 NET_RX_SOFTIRQ 软中断的,并且调度的是 sd->backlog 这个 struct napi。然后在 tun_rx_batched() 函数在使能中断下半部时会调用 do_softirq(),从而执行刚刚挂起的 NET_RX_SOFTIRQ 对应的 net_rx_action 软中断响应函数 net_rx_aciton。net_rx_action 会执行 sd->backlog 对应的 napi 接口函数。process_backlog 是内核的 netdev 在初始化时在每 CPU 变量中填入的 struct napi_struct 结构体。最后从 process_backlog 执行到 openvswitch 注册的 hook 函数 netdev_frame_hook (openvswitch.ko 第 2小节)。
流程将跳转到 openvswitch.ko 第3小节。
process_backlog 的注册
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
…
for_each_possible_cpu(i) { /* 遍历各个CPU的每CPU变量 */
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i); /* sd是个每CPU变量 */
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
sd->backlog.poll = process_backlog; /* 定义napi_struct的poll函数 */
sd->backlog.weight = weight_p;
}
…
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
open_softirq(NET_TX_SOFTIRQ, net_tx_action); /* 设置软中断NET_TX_SOFTIRQ的响应函数 */
open_softirq(NET_RX_SOFTIRQ, net_rx_action); /*设置软中断NET_RX_SOFTIRQ的响应函数 */
rc = cpuhp_setup_state_nocalls(CPUHP_NET_DEV_DEAD, "net/dev:dead",
NULL, dev_cpu_dead);
WARN_ON(rc < 0);
rc = 0;
out:
return rc;
}
openvswitch 部分
openvswitch.ko 作为 openvswitch 的一个内核模块内核态报文的接收和转发。通过给 tun 设备挂接 hook 函数,来处理 tun 接收和发送的报文。在创建虚机时给虚机分配的 vnet 口会暴露给 host,我们一般通过 xml 文件指定到桥入那个 ovs 网桥。在桥入的时候,用户态代码通过 netlink 与 openvswitch.ko 进行通信。把 vnet 口桥入 ovs 网桥时会给 vnet 这个设备挂 netdev_frame_hook 钩子函数。
netlink 注册
当 ovs 添加一个 vport 时会通过 netlink 发送到 openvswitch.ko,openvswitch 注册的 netlink 处理函数负责处理相关命令。
static struct genl_ops dp_vport_genl_ops[] = {
{ .cmd = OVS_VPORT_CMD_NEW,
.flags = GENL_UNS_ADMIN_PERM, /* Requires CAP_NET_ADMIN privilege. */
.policy = vport_policy,
.doit = ovs_vport_cmd_new /* OVS_VPORT_CMD_NEW消息的 */
},
{ .cmd = OVS_VPORT_CMD_DEL,
.flags = GENL_UNS_ADMIN_PERM, /* Requires CAP_NET_ADMIN privilege. */
.policy = vport_policy,
.doit = ovs_vport_cmd_del
},
{ .cmd = OVS_VPORT_CMD_GET,
.flags = 0, /* OK for unprivileged users. */
.policy = vport_policy,
.doit = ovs_vport_cmd_get,
.dumpit = ovs_vport_cmd_dump
},
{ .cmd = OVS_VPORT_CMD_SET,
.flags = GENL_UNS_ADMIN_PERM, /* Requires CAP_NET_ADMIN privilege. */
.policy = vport_policy,
.doit = ovs_vport_cmd_set,
},
};
struct genl_family dp_vport_genl_family __ro_after_init = {
.hdrsize = sizeof(struct ovs_header),
.name = OVS_VPORT_FAMILY,
.version = OVS_VPORT_VERSION,
.maxattr = OVS_VPORT_ATTR_MAX,
.netnsok = true,
.parallel_ops = true,
.ops = dp_vport_genl_ops,
.n_ops = ARRAY_SIZE(dp_vport_genl_ops),
.mcgrps = &ovs_dp_vport_multicast_group,
.n_mcgrps = 1,
.module = THIS_MODULE,
};
static struct genl_family *dp_genl_families[] = {
&dp_datapath_genl_family,
&dp_vport_genl_family,
&dp_flow_genl_family,
&dp_packet_genl_family,
&dp_meter_genl_family,
};
static int __init dp_register_genl(void)
{
int err;
int i;
for (i = 0; i < ARRAY_SIZE(dp_genl_families); i++) {
err = genl_register_family(dp_genl_families[i]); 注册netlink处理函数
if (err)
goto error;
}
return 0;
error:
dp_unregister_genl(i);
return err;
}
netdev_frame_hook 函数的注册

ovs 对报文的转发流程
OVS 首先通过 key 值找到对应的流表,然后转发到对应的端口。这篇文章的重点是讲解 vhost 的流程,OVS 具体流程并不是我们的讲解的重点。所以这方面有什么疑问请大家自行搜索一下 OVS 的资料。
这段代码的大体目的就是找到目的虚机所在的端口,也就是目的虚机所在的 vnet 端口。
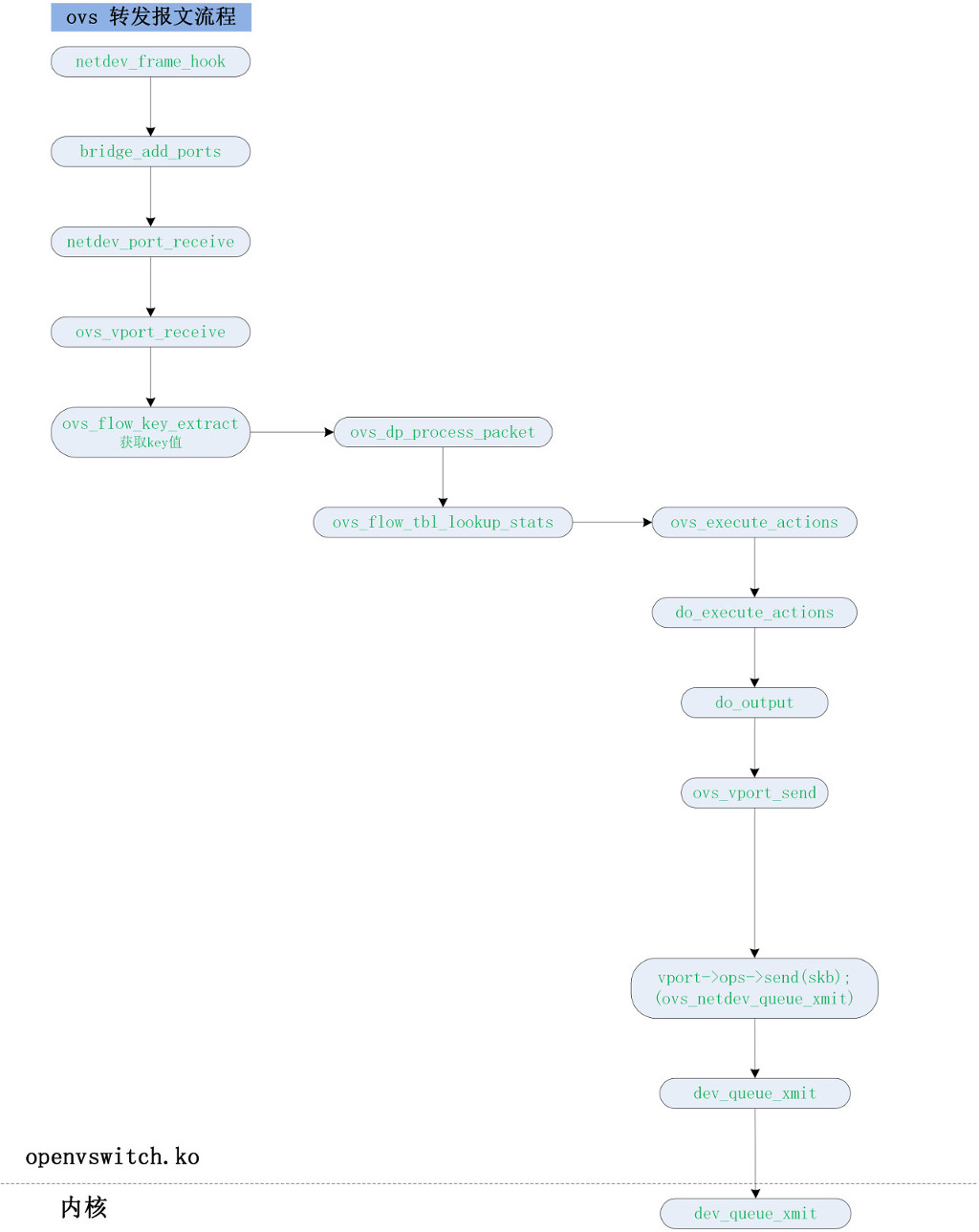
流程跳转到内核部分第1小节。
内核部分
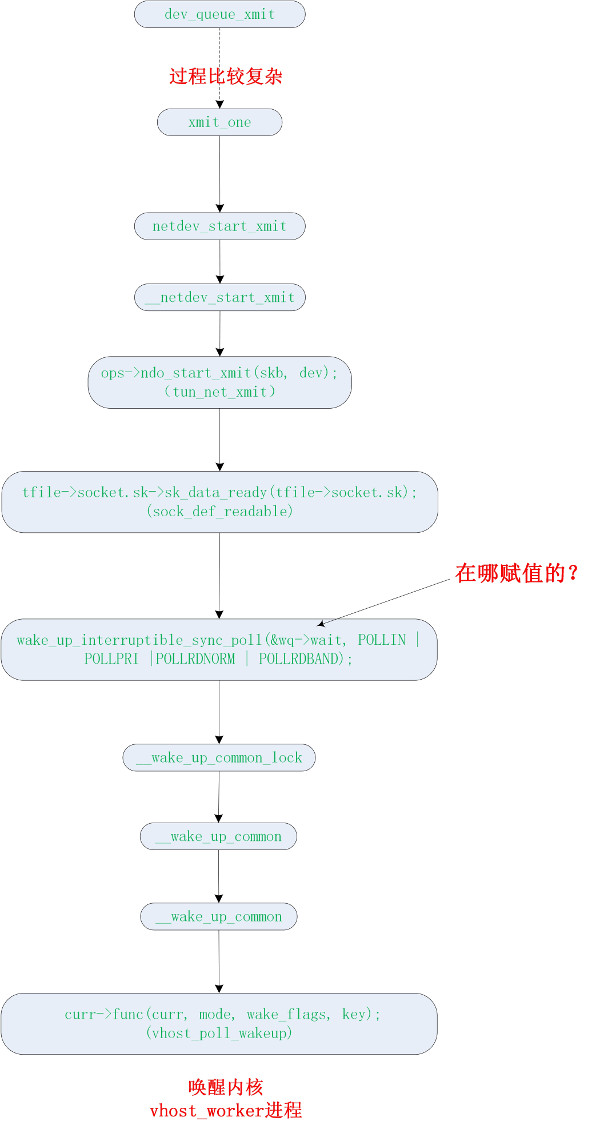
发送报文唤醒目的端的 vhost-worker 进程
内核的发送函数 __dev_queue_xmit 将会找到 vnet 设备对应的等待队列,并唤醒等待队列里对应的进程。这里将唤醒的进程就是 vhost_worker 进程了。
流程跳转到 vhost.ko 的第5小节。
代码流程
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
