

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 75198: 虚拟内存专题二:基于对象的反向映射(object-based reverse mapping,简称 objrmap)的回归
原文:Virtual Memory II: the return of objrmap 原创:By corbet @ Mar. 10, 2004 翻译:By unicornx 校对:By Wen Yang
Andrea Arcangeli not only wants to make the Linux kernel scale to and beyond 32GB of memory on 32-bit processors; he seems to be in a real hurry. There are, it would seem, customers waiting for a 2.6-based distribution which can run in such environments.
对于 Andrea Arcangeli 来说,他所要做的可不仅仅是使 Linux 能够在 32 位处理器上支持大于 32 GB 的内存;他还有更重要的使命(译者注,即本文要重点介绍的 objrmap)。大家都在等待他的工作完成,从而能够在基于 2.6 内核的发行版上享受到该功能。
For Andrea, the real culprit in the exhaustion of low memory is clear: it’s the reverse-mapping virtual memory (“rmap”) code. The rmap code was first described on this page in January, 2002; its purpose is to make it easier for the kernel to free memory when swapping is required. To that end, rmap maintains, for each physical page in the system, a chain of reverse pointers; each pointer indicates a page table which has a reference for that page. By following the rmap chains, the kernel can quickly find all mappings for a given page, unmap them, and swap the page out.
对于 Andrea 来说,真正导致低端内存被耗尽的罪魁祸首是虚拟内存中实现的反向映射代码(译者注,反向映射,英文是 reverse-mapping,简称 “rmap”,下文用 rmap 指代早期内核版本中的反向映射技术,和 objrmap 相对)。 在 2002 年 1 月 首次给大家介绍了 rmap;引入它的目的是为了方便内核在执行页交换(swap)时释放内存。rmap 为系统中的每个物理页维护一个链表用于保存反向映射指针;每个指针指向映射该物理页的一个页表。在给定一个物理页后,通过遍历其 rmap 链表,内核可以快速查找到映射该物理页的所有进程,逐个取消这些映射关系后就可以将该物理页交换出来(page out)。
The rmap code solved some real performance problems in the kernel’s virtual memory subsystem, but it, too has a cost. Every one of those reverse mapping entries consumes memory - low memory in particular. Much effort has gone into reducing the memory cost of the rmap chains, but the simple fact remains: as the amount of memory (and the number of processes using that memory) goes up, the rmap chains will consume larger amounts of low memory. Eliminating the rmap overhead would go a long way toward allowing the kernel to scale to larger systems. Of course, one wants to eliminate this overhead while not losing the benefits that rmap brings.
rmap 技术解决了内核虚拟内存子系统中的性能问题,但它也是有成本的。链表中用于保存反向映射指针的每个元素都要消耗内存,而且是低端内存(low memory)。内核社区为降低 rmap 的内存消耗付出了很多努力,但现实是:随着系统的内存量(以及使用内存的进程数目)的增加,rmap 将消耗更多的低端内存。只有降低 rmap 的内存开销才能推动内核支持更大规模的系统。当然,前提是不能失去 rmap 带给我们的在性能上的提升。
Andrea’s approach is to bring back and extend the object-based reverse mapping patches. The initial object-based patch was created by Dave McCracken; LWN covered this patch a year ago. Essentially, this patch eliminates the rmap chains for memory which maps a file by following pointers “the long way around” and searching candidate virtual memory areas (VMAs). Andrea has updated this patch and fixed some bugs, but the core of the patch remains the same; see last year’s description for the details.
Andrea 参考了原先的基于对象的反向映射(object-based reverse mapping)补丁并基于该补丁做了改进。这个补丁最初是由 Dave McCracken 提交的;LWN 一年前为大家介绍过。这个补丁最主要的优点,是针对文件映射使用的物理页,消除了 rmap 对内存的巨大需求,但代价是它需要通过 “更复杂” 的方式反向查找到映射该物理页的页表项,这其中还包括需要搜索关联的虚拟内存区域(virtual memory area,简称 VMA)。Andrea 对该补丁进行了修改 并修复了一些错误,但补丁的核心思想仍然保持不变;有关其核心思想可以参阅去年的详细介绍。
Last week, we raised the possibility that the virtual memory subsystem could see fundamental changes in the course of the 2.6 “stable” series. This week, Linus confirmed that possibility in response to Andrea’s object-based reverse mapping patch:
I certainly prefer this to the 4:4 horrors. So it sounds worth it to put it into -mm if everybody else is ok with it.
上周,我们提出是否有可能在 2.6 的 “稳定”版本系列中看到这个重大改变。本周,Linus 确认了这种可能性 并提到了 Andrea 的基于对象的反向映射补丁:
相对于 “4:4”(译者注,指 [4G/4G 补丁][6]),我更倾向于合入这个补丁(译者注,指 Andrea 的基于对象的反向映射补丁)。如果其他人都觉得没问题的话,我将把它合入 “-mm” 代码版本库。
Assuming this work goes forward, it has the usual implications for the stable kernel. Even assuming that it stays in the -mm tree for some time, its inclusion into 2.6 is likely to destabilize things for a few releases until all of the obscure bugs are shaken out.
这么做势必会影响到内核版本的稳定性。即使该补丁会在 “-mm” 代码库中保留一段时间,但一旦当它被合入 2.6 中后肯定还会出现这样或者那样的问题,可以预期的是这种不稳定性会延续多个版本,直到所有那些不易察觉的错误都被消除干净。
Dave McCracken’s original patch, in any case, only solves part of the problem. It gets rid of the rmap chains for file-backed memory, but it does nothing for anonymous memory (basic process data - stacks, memory obtained with
malloc(), etc.), which has no “object” behind it. File-backed memory is a large portion of the total, especially on systems which are running large Oracle servers and use big, shared file mappings. But anonymous memory is also a large part of the mix; it would be nice to take care of the rmap overhead for that as well.
Dave McCracken 提交的补丁起初只解决了部分问题。它解决了那些文件映射内存(file-backed memory)的反向映射,但对匿名内存(anonymous memory),即那些没有映射实际文件的内存(那些最基本的进程运行时所需要的内存,譬如栈、以及使用 malloc() 所分配的堆等),并没有任何改进(译者注,即还是采用旧的 rmap 方式)。用于文件映射的内存占内存消耗总数的很大一部分,特别是在那些运行大型 Oracle 系统的服务器上,这些系统会对很大的共享文件进行内存映射;但这并不意味着我们可以忽略匿名内存所消耗的内存数量;它涉及的 rmap 开销也不少。
To that end, Andrea has posted another patch (in preliminary form) which provides object-based reverse mapping for anonymous memory as well. It works, essentially, by replacing the rmap chain with a pointer to a chain of virtual memory area (VMA) structures.
为此,Andrea 提交了另一个补丁(目前还处于原型状态),它为匿名内存也提供了基于对象的反向映射机制。它本质上是用虚拟内存区域(VMA)链表替换了 rmap 所使用的针对每个物理页所维护的反向映射链表。
Anonymous pages are always created in response to a request for memory from a single process; as a result, they are never shared at creation time. Given that, there is no need for a new anonymous page to have a chain of reverse mappings; we know that there can be only a single mapping. Andrea’s patch adds a union to
struct pagewhich includes the existingmappingpointer (for non-anonymous memory) and adds a couple of new ones. One of those is simply calledvma, and it points to the (single) VMA structure pointing to the page. So if a process has several non-shared, anonymous pages in the same virtual memory area, the structure looks somewhat like this:
我们知道,只有当一个进程发起内存申请请求时内核才会为其创建匿名页;因此,匿名页在创建之初不存在共享的情况。鉴于此,不需要对于一个新建的匿名页维护一个反向映射的链表;也就是说此时只会存在一个映射。Andrea 在补丁中为 struct page 添加了一个联合体(union)类型的成员,该联合体中除了包含现有的 mapping 指针(用于非匿名内存)外还添加了几个新的成员。其中一个简称为 vma,它指向(单个)VMA 结构体,而通过该 VMA 结构体则可以找到其关联的页。因此,假设某个进程的一个连续的虚拟地址区间映射了多个非共享的匿名页,则它们之间的关系看起来有点像下图这样:
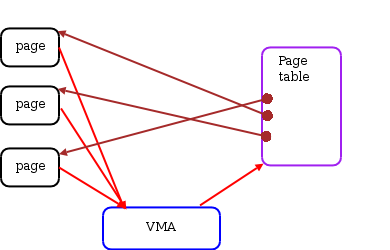
With this structure, the kernel can find the page table which maps a given page by following the pointers through the VMA structure.
利用以上结构,在给定一个物理页的条件下,内核可以通过其关联的 VMA 结构找到映射该物理页的页表。(译者注,这里的描述应该是针对还未合入内核的补丁实现的描述,在正式合入后,并没有上文的联合体和 vma 字段,对于匿名页,无论是否共享,都采用下文的 anon_vma 和 VMA 链表进行管理,对于未共享的场景,VMA 链表上只有一个节点)
Life gets a bit more complicated when the process forks, however. Once that happens, there will be multiple page tables pointing to the same anonymous pages and a single VMA pointer will no longer be adequate. To deal with this case, Andrea has created a new “anon_vma” structure which implements a linked list of VMAs. The third member of the new
struct pageunion is a pointer to this structure which, in turn, points to all VMAs which might contain the page. The structure now looks like:
当进程派生子进程(fork)时,情况会变得复杂一些。此时,将会有多个页表指向相同的匿名页,显然单个 VMA 指针将不再适用。为了解决这个问题,Andrea 创建了一个新的 “anon_vma” 结构体类型,该结构体中包含了一个 VMA 的链表。struct page 的 union 成员中新增的第三个成员是指向此结构体类型的指针。数据结构现在看起来如下图所示:
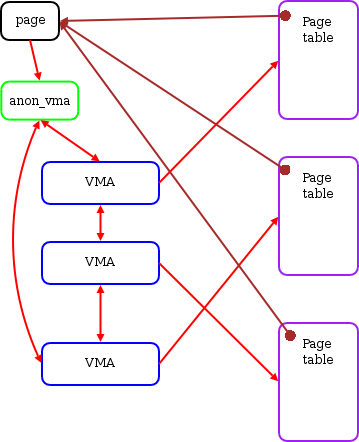
If the kernel needs to unmap a page in this scenario, it must follow the linked list and examine every VMA it finds. Once the page is unmapped from every page table found, it can be freed.
在该场景下如果内核需要取消对该物理页的映射,可以遍历 anon_vma 所维护的 VMA 链表,对链表上的每个 VMA 找到其对应的页表(Page table),然后取消页表中对物理页(page)的映射。遍历完成后说明所有映射关系都被取消,此时就可以释放该物理页了。
There are some memory costs to this scheme: the VMA structure requires a new
list_headstructure, and theanon_vmastructure must be allocated whenever a chain must be formed. One VMA can refer to thousands of pages, however, so a per-VMA cost will be far less than the per-page costs incurred by the existing rmap code.
该方案存在一些内存成本:VMA 结构体中需要新增 list_head 结构,并且在创建链表时需要分配 anon_vma 结构体。但是,由于一个 VMA 可以引用数千个物理页,因此相对于现有的 rmap 的代码,采用 VMA 的方式所消耗的内存要少得多得多。
This approach does incur a greater computational cost. Freeing a page requires scanning multiple VMAs which may or may not contain references to the page under consideration. This cost will increase with the number of processes sharing a memory region. Ingo Molnar, who is fond of O(1) solutions, is nervous about object-based schemes for this reason. According to Ingo, losing the possibility of creating an O(1) page unmapping scheme is a heavy cost to pay for the prize of making large amounts of memory work on obsolete hardware.
这种方法确实会产生更大的计算成本。释放物理页需要扫描多个 VMA,这些 VMA 可能映射了该物理页,也可能没有。查找的成本将随共享内存区的进程的数量增加而增加。更倾向于 O(1) 解决方案的 Ingo Molnar 针对该场景下的 objrmap 方案表达了他的担忧。根据 Ingo 的说法,在取消页面映射处理过程中,仅仅是为了在过时的机器上支持大容量内存就放弃 O(1) 的算法实在是得不偿失。
The solution that Ingo would like to see, instead, is to reduce the per-page memory overhead by reducing the number of pages. The means to that end is page clustering - grouping adjacent hardware pages into larger virtual pages. Page clustering would reduce rmap overhead, and reduce the size of the main kernel memory map as well. The available page clustering patch is even more intrusive than object-based reverse mapping, however; it seems seriously unlikely to be considered for 2.6.
相反,Ingo 建议的解决方案是通过减少物理页的数量来减少每页的内存开销。解决的方案是对页面进行合并(page clustering),即将相邻的物理页面组合为更大的虚拟页面。合并物理页后会减少 rmap 的开销,同时也会减少内核中内存映射表的大小。然而,相对于 objrmap 补丁,“page clustering” 补丁的修改过于激进,看上去不太可能为 2.6 版本所接受。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
