

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 717293: 五级页表
原文:Five-level page tables 原创:By corbet @ Mar. 15, 2017 翻译:By unicornx of TinyLab.org 校对:By simowce
Near the beginning of 2005, the merging of the four-level page tables patches for 2.6.10 was an early test of the (then) new kernel development model. It demonstrated that the community could indeed merge fundamental changes and get them out quickly to users — a far cry from the multi-year release cycles that prevailed before the 2.6.0 release. The merging of five-level page tables (outside of the merge window) for 4.11-rc2, instead, barely raised an eyebrow. It is, however, a significant change that is indicative of where the computing industry is going.
远在 2005 年年初的时候,在 2.6.10 的基础上合入四级页表补丁的工作是一次基于(当时)新的内核开发模式的早期尝试。它表明在社区的合作努力下完全有能力针对一些核心模块进行快速修改并发布给用户,而这在 2.6.0 版本之前是一件难以想象的事情,那时一个重大功能的更新需要经过多轮发布,而这往往需要等上好几年。(译者注,也许大家已经习惯了内核开发上这种重大更新的快速发布方式),所以当内核在 4.11-rc2 版本上合入五级页表(严格说来,具体加入该补丁的时间是在集成周期之外)时几乎没有引起人们的太大关注。然而,这的确是一个显著的改进,体现了现代计算机行业的发展方向。
A page table, of course, maps a virtual memory address to the physical address where the data is actually stored. It is conceptually a linear array indexed by the virtual address (or, at least, by the page-frame-number portion of that address) and yielding the page-frame number of the associated physical page. Such an array would be large, though, and it would be hugely wasteful. Most processes don’t use the full available virtual address space even on 32-bit systems, and they don’t use even a tiny fraction of it on 64-bit systems, so the address space tends to be sparsely populated and, as a result, much of that array would go unused.
所谓页表,理论上可以想象成一个线性的数组(译者注,这里所谓的理论模型可以理解成就是最基本的一级页表方式),数组的每一项(译者注,即页表项)用于保存一组映射关系,即描述给定一个虚拟内存地址后如何找到其对应的实际数据所在的物理页框(page-frame)。虚拟地址中含有页表项的索引值(其本质也是该虚拟地址所对应的物理页框的编号),根据其索引值我们就可以找到实际对应的物理页框(译者注,假设一个页框为 4KB,考虑到页框地址按照 4K 边界对齐,则物理页框的物理地址通过索引值乘上 4096 即为页框的物理地址)。但问题是,这样的数组(即页表)会很大,而且会非常浪费。绝大多数进程即使在 32 位的系统上也不会访问整个虚拟地址空间,更不用说在 64 位的系统上了。进程所访问的地址空间往往非常离散,且相对整个虚拟地址空间来说只是很小的一部分,所以如果采用一级页表方式,大部分的页表项都将被闲置。
The solution to this problem, as implemented in the hardware for decades, is to turn the linear array into a sparse tree representing the address space. The result is something that looks like this:
几十年来,硬件上的解决方案一直没有变,基本思路就是将一维的线性数组(一级页表方式)变成支持离散地址区间的树状结构(多级页表方式)。如下图所示:
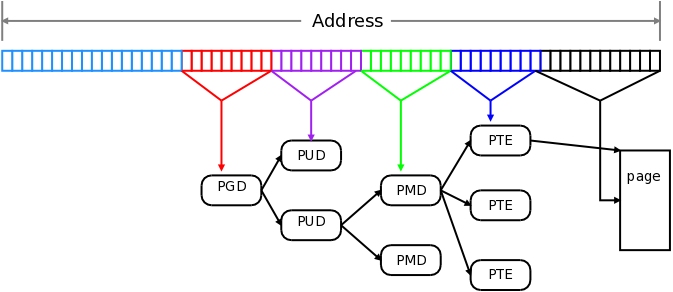
The row of boxes across the top represents the bits of a 64-bit virtual address. To translate that address, the hardware splits the address into several bit fields. Note that, in the scheme shown here (corresponding to how the x86-64 architecture uses addresses), the uppermost 16 bits are discarded; only the lower 48 bits of the virtual address are used. Of the bits that are used, the nine most significant (bits 39-47) are used to index into the page global directory (PGD); a single page for each address space. The value read there is the address of the page upper directory (PUD); bits 30-38 of the virtual address are used to index into the indicated PUD page to get the address of the page middle directory (PMD). With bits 21-29, the PMD can be indexed to get the lowest level page table, just called the PTE. Finally, bits 12-20 of the virtual address will, when used to index into the PTE, yield the physical address of the actual page containing the data. The lowest twelve bits of the virtual address are the offset into the page itself.
图上方有一行方框,每一个方框代表 64 位的虚拟地址的一个比特位。硬件翻译(translate)该地址(译者注,即将虚拟地址转换为物理地址)时,会将整个地址拆分为多段比特位区域(bit field)。注意,在本图中(对应于 x86-64 架构定义虚拟地址的方式),最高的 16 个位并没有被使用;而仅使用虚拟地址的低 48 位。在使用的比特位中,最高的 9 个位(位 39 - 47)用于对页全局目录(Page Global Directory,简称 PGD)的表项进行索引;对每个进程的地址空间(address space)来说,对应唯一的一个 PGD,占用一个物理页。PGD 的每一个表项中可以获得的是对应的那个页上层目录(Page Upper Directory,简称 PUD)的地址;虚拟地址的第 30 - 38 位用于对指定的 PUD 的表项进行索引以获得页中间目录(Page Middle Directory,简称 PMD)的物理地址。而虚拟地址的第 21 - 29 位,则用于对 PMD 中的表项进行索引以获得最低级别的页表,简称为 PTE (译者注,即 Page Tabel Entry 的意思)的物理地址。最后,虚拟地址的第 12 - 20 位用于对 PTE 的表项进行索引,得到最终的包含实际数据的物理页的物理地址。虚拟地址的最低 12 位则以偏移量的方式标识实际数据在最终物理页中的位置。
At any level of the page table, the pointer to the next level can be null, indicating that there are no valid virtual addresses in that range. This scheme thus allows large subtrees to be missing, corresponding to ranges of the address space that have no mapping. The middle levels can also have special entries indicating that they point directly to a (large) physical page rather than to a lower-level page table; that is how huge pages are implemented. A 2MB huge page would be found directly at the PMD level, with no intervening PTE page, for example.
在任意级别的页表中,指向下一级的指针可以为空,表示该范围内的虚拟地址没有被当前进程所使用。因此,采用以上方案后,如果某段虚拟地址没有被使用(即没有映射实际的物理地址),则在整个四级树结构中该段虚拟地址所对应的那些子树也可以不存在。为了支持实现巨页(huge page),中间层级的页表中可以定义一些特殊条目直接指向最终存放实际数据的(更大的)物理页而不是较低层级的页表。例如,PMD 的表项可以跳过 PTE 级别,直接指向 2MB 的巨页。
One can quickly see that the process of translating a virtual address is going to be expensive, requiring several fetches from main memory. That is why the translation lookaside buffer (TLB) is so important for the performance of the system as a whole, and why huge pages, which require fewer lookups, also help.
由于多级页表的存在,地址翻译的过程是一件费时费力的事情,需要从主存中多次读取信息并进行相应处理。这就是为什么 TLB (Translation Lookaside Buffer)的存在对于改进整个系统的性能如此重要的原因,同时也是为什么内核要引入巨页(huge page)的原因,因为采用巨页机制后对主存进行查找的频率会大大减少。
It is worth noting that not all systems run with four levels of page tables. 32-Bit systems use three or even two levels, for example. The memory-management code is written as if all four levels were always present; some careful coding ensures that, in kernels configured to use fewer levels, the code managing the unused levels is transparently left out.
值得注意的是,并非所有系统都使用四级页表。例如,32 位系统只使用三个甚至两个级别。在内存管理的代码实现上,会将底层的页表层级差别封装起来,使得所有的系统看上去好像都采用的是四级页表方式;换句话说,基于精巧的设计,如果某些系统在配置上指定了使用更少的层级,则不使用的层级的页表会被透明地过滤掉。
Back when four-level page tables were merged, your editor wrote: “Now x86-64 users can have a virtual address space covering 128TB of memory, which really should last them for a little while.” The value of “a little while” can now be quantified: it would appear to be about 12 years. Though, in truth, the real constraint appears to be the 64TB of physical memory that current x86-64 processors can address; as Kirill Shutemov noted in the x86 five-level page-table patches, there are already vendors shipping systems with that much memory installed.
记得当初内核开始支持四级页表时,我曾经写道:“现在 x86-64 的用户可以拥有一个高达 128TB 的虚拟地址空间,这真的够他们用一段时间了。” 如果我们可以给这 “一段时间” 定一个期限,现在我们终于知道那就是大概 12 年吧。当然,实际的物理内存约束取决于 x86-64 处理器的设计,这个限制是最大支持 64TB 的物理内存;正如 Kirill Shutemov 在针对 x86 系统的五级页表补丁中所指出的那样,目前已经有一些系统供应商为他们的系统安装了高达 64TB 的内存(译者注,言下之意,不仅体系架构支持的物理内存的最大上限行将被突破,内核所支持的最大虚拟地址空间被突破那也是指日可待)。
As is so often the case in this field, the solution is to add another level of indirection in the form of a fifth level of page tables. The new level, called the “P4D”, is inserted between the PGD and the PUD. The patches adding this level were merged for 4.11-rc2, even though there is, at this point, no support for five-level paging on any hardware. While the addition of four-level page tables caused a bit of nervousness, the five-level patches merged were described as “low risk”. At this point, the memory-management developers have a pretty good handle on the changes that need to be made to add another level.
按照惯例,解决这个问题的方案是将四级页表扩展为五级。新的级别称为 “P4D”,插入在 PGD 和 PUD 之间。虽然当前在硬件上还没有实现五级页表,但内核已经提前将支持五级页表的补丁合入 4.11-rc2。回想当初内核增加四级页表时,社区还为此紧张了一段时间,但目前内核在集成这个五级页表补丁时仅仅将其风险级别定义为 “低风险”。应该说,当前内核的内存管理模块开发人员在处理类似添加一个新的页表级别这类问题上已经驾轻就熟了。
The patches adding five-level support for upcoming Intel processors is currently slated for 4.12. Systems running with five-level paging will support 52-bit physical addresses and 57-bit virtual addresses. Or, as Shutemov put it: “It bumps the limits to 128 PiB of virtual address space and 4 PiB of physical address space. This ‘ought to be enough for anybody’.” The new level also allows the creation of 512GB huge pages.
目前计划在 4.12 版本上正式合入该补丁以支持即将推出的新的英特尔处理器(译者注,最终实际合入五级页表功能的内核版本是 4.14)。使用五级页表方式运行的系统将支持 52 位字宽的物理地址和 57 位字宽的虚拟地址。或者,按照 Shutemov 所描述的:“它突破了原先的限制,最大可以支持高达 128 PiB 的虚拟地址空间和 4 PiB 的物理地址空间。这对任何人都应该足够了”。新的五级页表机制还允许创建高达 512GB 的巨页。
The current patches have a couple of loose ends to take care of. One of those is that Xen will not work on systems with five-level page tables enabled; it will continue to work on four-level systems. There is also a need for a boot-time flag to allow switching between four-level and five-level paging so that distributors don’t have to ship two different kernel binaries.
目前的补丁有两个遗留问题需要关注。一是 Xen 无法在启用了五级页表的系统上运行;它目前只支持在四级页表的系统上工作。另外一个是内核需要在引导过程中提供一个开关量,以允许在四级页表和五级页表之间切换,这样在发布安装包时就不必提供两个不同的内核二进制文件了。
Another interesting problem is described at the end of the patch series. It would appear that there are programs out there that “know” that only the bottom 48 bits of a virtual address are valid. They take advantage of that knowledge by encoding other information in the uppermost bits. Those programs will clearly break if those bits suddenly become part of the address itself. To avoid such problems, the x86 patches in their current form will not allocate memory in the new address space by default. An application that needs that much memory, and which does not play games with virtual addresses, can provide an address hint above the boundary in a call to
mmap(), at which point the kernel will understand that mappings in the upper range are accessible.
在五级页表补丁集的最后一个补丁里描述了另一个有趣的问题。似乎有一些程序会“假设”对于一个虚拟地址来说,其只利用了低 48 位。基于该假设它们会在虚拟地址的除了低 48 比特位之外的高比特位中加入一些私有的编码信息。但这么做是有问题的,内核或许有一天会使用这些高比特位。为避免此类问题,默认情况下,当前针对 x86 系统的补丁缺省情况下对虚拟地址只使用低 48 位(译者注,即不会访问高于 256 TB 的虚拟地址空间)。如果一个应用程序需要访问更多的内存,并且不关心虚拟地址的话可以在调用 mmap() 时对其第一个参数传入一个高于最大限制的地址值,此时内核将允许程序访问超出部分的内存。
Anybody wanting to play with the new mode can do so now with QEMU, which understands five-level page tables. Otherwise it will be a matter of waiting for the processors to come out — and the funds to buy a machine with that much memory in it. When the hardware is available, the kernel should be ready for it.
任何想要尝试新的五级页表模式的人可以使用 QEMU 来模拟。否则,只好等新的处理器上市,当然为此还得准备好足够的资金来购买一台安装了如此多内存的系统。总而言之,内核要做的只是为此提前做好充分的准备。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
