

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 368869: 内存规整(compaction)
原文:Memory compaction 原创:By corbet @ Jan. 6, 2010 翻译:By unicornx 校对:By Xiaojie Yuan
The longstanding memory fragmentation problem has been covered many times in these pages. In short: as the system runs, pages tend to be scattered between users, making it hard to find groups of physically-contiguous pages when they are needed. Much work has gone into avoiding the need for higher-order (multi-page) memory allocations whenever possible, with the result that most kernel functionality is not hurt by page fragmentation. But there are still situations where higher-order allocations are needed; code which needs such allocations can fail on a fragmented system.
我们已经多次讨论了由来已久的内存碎片问题。简而言之:随着系统的运行,经过不同用户的分配请求后,页框会变得十分分散,这使得在需要分配内存时很难找到物理上连续的页框。为了尽可能减少对 “高阶”(higher-order,即多个连续页框)内存的分配请求,内核做了大量的工作,目前大多数内核功能已经不会受到内存碎片的影响。但即便如此,仍然存在需要分配 “高阶” 内存的情况; 一旦碎片太多,分配不了需要的内存,就会导致相关操作执行失败。
It’s worth noting that, in one way, this problem is actually getting worse. Contemporary processors are not limited to 4K pages; they can work with much larger pages (“huge pages”) in portions of a process’s address space. There can be real performance advantages to using huge pages, mostly as a result of reduced pressure on the processor’s translation lookaside buffer. But the use of huge pages requires that the system be able to find physically-contiguous areas of memory which are not only big enough, but which are properly aligned as well. Finding that kind of space can be quite challenging on systems which have been running for any period of time.
值得注意的是,从某种程度上说,这个问题正在变得更加严重。现代处理器不再限于使用传统的 4K 大小的页框;它们可以在进程的部分地址空间中支持大得多的页(即 “巨页” (”huge pages”))。使用巨页会带来真正的性能优势,主要原因是减小了对处理器的转换后备缓冲区(translation lookaside buffer)的压力。但是使用巨页要求系统能够找到物理上连续的内存区域,这些区域不仅要足够大,而且还必须确保按适当方式满足字节对齐的要求。在一个已经运行了一段时间的系统上要想找到符合这些条件的内存空间非常具有挑战性。
Over the years, the kernel developers have made various attempts to mitigate this problem; techniques like
ZONE_MOVABLEand lumpy reclaim have been the result. There is still more that can be done, though, especially in the area of fixing fragmentation to recover larger chunks of memory. After taking a break from this area, Mel Gorman has recently returned with a new patch set implementing memory compaction. Here we’ll take a quick look at how this patch works.
多年来,内核开发人员已经做出各种尝试来缓解这个问题;这些尝试包括定义新的域 ZONE_MOVABLE 和引入 块状回收(lumpy reclaim) 这样的技术。但是,光有这些还不够,特别是在解决内存碎片以及生成更大的内存块方面。在该领域淡出了一段时间的 Mel Gorman 最近又回来了,并带来了一个新的补丁用于实现 内存规整(memory compaction)。在这里,给大家简短介绍一下这个补丁的工作原理。
Imagine a very small memory zone which looks like this:
假设存在一个非常小的内存域(zone),如下图所示:

Here, the white pages are free, while those in red are allocated to some use. As can be seen, the zone is quite fragmented, with no contiguous blocks of larger than two pages available; any attempt to allocate, for example, a four-page block from this zone will fail. Indeed, even two-page allocations will fail, since none of the free pairs of pages are properly aligned.
页框为白色表示空闲,而红色的是由于某种用途被分配了的页框。可以看出,该域(zone)中的空闲页框非常分散,没有大于两页的连续内存块;如果要从该域中分配包含连续四页的内存块必将失败。实际上,即便是分配包含两页连续的内存也会失败,因为所有连续两页的内存块都不满足伙伴系统对内存分配的对齐要求(译者注,伙伴系统要求每个内存块的第一个页框的页框编号必须是 2 的整数次幂)。
It’s time to call in the compaction code. This code runs as two separate algorithms; the first of them starts at the bottom of the zone and builds a list of allocated pages which could be moved:
下面来演示一下规整(compaction)算法的工作原理。代码中会运行两个独立的扫描;第一个扫描从域的底部(bottom)开始(译者注,如下图所示从左往右进行扫描),一边扫描一边将可以移动(movable)的页框记录到一个列表中:
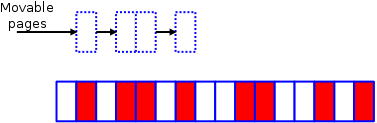
Meanwhile, at the top of the zone, the other half of the algorithm is creating a list of free pages which could be used as the target of page migration:
同时,在区域的顶部(top),另一个扫描(译者注,如下图所示从右往左)创建另一个列表,用于记录可作为页框迁移目标的空闲页框位置:
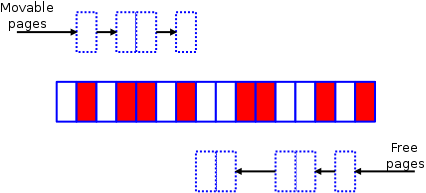
Eventually the two algorithms will meet somewhere toward the middle of the zone. At that point, it’s mostly just a matter of invoking the page migration code (which is not just for NUMA systems anymore) to shift the used pages to the free space at the top of the zone, yielding a pretty picture like this:
最终,两个扫描会在域中间的某个位置相遇(意味着扫描结束)。此时,剩下的工作主要是调用 页面迁移(page migration)功能(从这里我们可以看到页面迁移的功能已经不仅仅只针对 NUMA 系统)将左边扫描得到的已分配的页框上的内容转移到右边空闲的空间中,产生的结果如下如下所示,规整后的内存看上去是不是很整齐?

We now have a nice, eight-page, contiguous span of free space which can be used to satisfy higher-order allocations if need be.
现在我们得到了一个拥有大小为 8 页并且连续的可用空间,可用于满足更 “高阶” 的内存分配。
Of course, the picture given here has been simplified considerably from what happens on a real system. To begin with, the memory zones will be much larger; that means there’s more work to do, but the resulting free areas may be much larger as well.
当然,这里展示的流程和真实系统比起来已经大大简化了。特别地,实际的内存域会大得多;这意味着扫描的工作量也会大很多,但由此获得的空闲区也可能更大。
But all this only works if the pages in question can actually be moved. Not all pages can be moved at will; only those which are addressed through a layer of indirection and which are not otherwise pinned down are movable. So most user-space pages - which are accessed through user virtual addresses - can be moved; all that is needed is to tweak the relevant page table entries accordingly. Most memory used by the kernel directly cannot be moved - though some of it is reclaimable, meaning that it can be freed entirely on demand. It only takes one non-movable page to ruin a contiguous segment of memory. The good news here is that the kernel already takes care to separate movable and non-movable pages, so, in reality, non-movable pages should be a smaller problem than one might think.
所有的这一切只有在扫描过程中碰到的实际页框都是可移动时才有效。然而并非所有页框都是可以随意移动的;只有通过页表间接映射的并且还要保证没有被锁定的那些页框才是可移动的。因此,大多数用户空间的页框都是可以移动的(因为是通过用户虚拟地址访问);移动时所需要的只是简单地调整相关的页表条目即可。直接被内核使用的绝大多数内存都无法移动,尽管其中一些可以被回收,但也是必须在必要的情况下才会被释放。只要存在一个真正不可移动的页框就会妨碍我们生成连续的内存块。但好消息是内核已经注意并隔离了可移动页和不可移动页存放的区域,因此,实际上,不可移动页框所造成的问题并不会像我们想象的那么严重。
The running of the compaction algorithm can be triggered in either of two ways. One is to write a node number to
/proc/sys/vm/compact_node, causing compaction to happen on the indicated NUMA node. The other is for the system to fail in an attempt to allocate a higher-order page; in this case, compaction will run as a preferable alternative to freeing pages through direct reclaim. In the absence of an explicit trigger, the compaction algorithm will stay idle; there is a cost to moving pages around which is best avoided if it is not needed.
可以通过两种方式触发运行内存规整。一种是通过将节点号写入 /proc/sys/vm/compact_node,就可以对指定的 NUMA 节点上的内存进行规整。另一种是当系统在尝试分配更高阶的内存时,如果发生内存不足,则作为主动回收(direct reclaim)的选择之一,内核可以执行规整操作来释放页框。在明确的触发条件没有被满足的情形下,内存规整是不会被执行的;因为移动页框是一件耗时的操作,除非万不得已,最好避免此类操作。
Mel ran some simple tests showing that, with compaction enabled, he was able to allocate over 90% of the system’s memory as huge pages while simultaneously decreasing the amount of reclaim activity needed. So it looks like a useful bit of work. It is memory management code, though, so the amount of time required to get into the mainline is never easy to predict in advance.
Mel 对内存规整补丁运行了一些简单的测试,结果显示,通过启用内存规整,能够将超过 90% 的系统内存整理成较大的连续页,同时还降低了所需的回收的工作量。看起来这个补丁对内核是有帮助的。但由于它涉及到内存管理部分的代码,因此何时能被主线接纳还真不好确定。(译者注,该补丁随 2.6.35 版本合入主线。)
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
