

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
LWN 121618: 另一种避免内存碎片化(memory fragmentation)的方法
原文:Yet another approach to memory fragmentation 原创:By Jonathan Corbet @ Feb. 1, 2005 翻译:By unicornx 校对:By Shaolin Deng
A number of developers have taken a stab at the problem of memory fragmentation and the allocation of large, contiguous blocks of memory in the kernel. Approaches covered on this page recently include Marcelo Tosatti’s active defragmentation patch and Nick Piggin’s kswapd improvements. Now Mel Gorman has jumped into the fray with a different take on the problem.
针对内存碎片(memory fragmentation)问题,许多开发人员已经做了深入研究,其目的都是为了改进内核分配大容量且连续的内存块的性能。最近在这方面的提案包括 Marcelo Tosatti 的 主动碎片整理(active defragmentation)补丁 和 Nick Piggin 的 kswapd 改进方案。现在,Mel Gorman 也参与进来并对这个问题提出了自己不同的想法。
At a very high level, the kernel organizes free pages as shown in the diagram below.
首先让我们先用下图复习一下内核(译者注,即伙伴(buddy)系统,专有名词,下文不再翻译)组织空闲物理页框的方式。
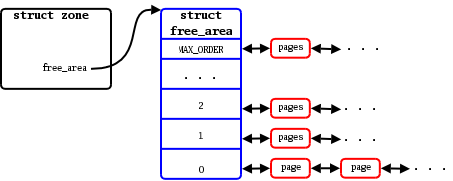
The system’s physical memory is split into zones; on an x86 systems, the zones include the small space reachable by ISA devices (
ZONE_DMA), the regular memory zone (ZONE_NORMAL), and memory not directly accessible by the kernel (ZONE_HIGHMEM). NUMA systems divide things further by creating zones for each node. Within each node, memory is split into chunks and sorted depending on its “order” - the base-2 logarithm of the size of each block. For each order, there is a linked list of available blocks of that size. So, at the bottom of the array, the order-0 list contains individual pages; the order-1 list has pairs of pages, etc., up to the maximum order handled by the system. When a request for an allocation of a given order arrives, a block is taken off the appropriate list. If no blocks of that size are available, a larger block is split. When blocks are freed, the buddy allocator tries to coalesce them with neighboring blocks to recreate higher-order chunks.
系统的物理内存被划分为多个区域(zone);在一个典型的 x86 系统上,这些区域包括:由 ISA 设备使用的一块较小的内存区(ZONE_DMA)(译者注:ISA 是 Industry Standard Architecture 的缩写,上世纪 80 年代用于 IBM 个人电脑的一种 16 位内部总线),常规内存区(ZONE_NORMAL),和内核不能直接访问的内存区(ZONE_HIGHMEM)。在 NUMA 系统上则进一步为每个节点(node)创建类似的区域。在每个节点(node)内(针对每个区域(zone)),所有的空闲页框被分组为不同类型的内存块,每种类型的内存块存放在各自对应的链表中(所有的链表则组织在上图所示的数组 free_area 中)。每一种类型的内存块由连续的物理页框组成,包含的页框数是以 2 为底数的 order 次幂,order 的取值为从 0 到 11(译者注:order 的值就是上图中对应数组的下标,MAX_ORDER 的值就是 11)。具体来说,上图中自下而上,order 为 0 的数组项所对应的链表中存放的内存块的大小是单个页框;order 为 1 的数组项所对应的链表中存放的内存块的大小是两个页框;依次类推,直到最上面的 order 值 为 MAX_ORDER 的数组项和其对应的链表。每次处理内存申请请求时,内核 buddy 系统根据请求指定的 order 值,从对应的链表中进行分配。如果对应的 order 链表中没有可用的内存块,内核就往上一级到更高的 order 对应的链表中找到一个更大的内存块,并将其一分为二后再进行分配。当归还内存块时,buddy 系统则尝试将释放的内存块与相邻的同样大小的块合并以创建更 “高阶” 的内存块(译者注,“高阶”(higher-order)内存,即页框连续且大小大于一个页框(order 大于 0)的内存块,下文直接用 high-order 指代,不再翻译)。
In real-life Linux systems, over time, the larger blocks tend to get split up, to the point that larger allocations can become difficult. A look at
/proc/buddyinfoon a running system will tend to show quite a few zero-order pages available (one hopes), but relatively few larger blocks. For this reason, high-order allocations have a high probability of failure on a system which has been up for a while.
在实际运行中,随着时间的推移,较大的内存块往往会被分解,以至于想要申请较大的内存变得困难。查看运行系统上的 /proc/buddyinfo,常常会发现系统中存在相当多的 order 为 0 的内存块(即只含有一个独立的页框),但更高 order 对应的内存块则相对较少。出于这个原因,higher-order 内存的分配问题在长时间运行的系统上具有较高的失败概率。
Mel’s approach is to split memory allocations into three types, as indicated by a new set of
GFP_flags which can be provided when memory is requested. Memory allocations marked by__GFP_USERRCLMare understood to be for user space, and to be easily reclaimable. In general, all that’s required to reclaim a user-space page is to write it to backing store (if it has been modified). The__GFP_KERNRCLMflag marks reclaimable kernel memory, such as that obtained from slabs and used in caches which can, when needed, be dropped. Finally, allocations not otherwise marked are considered to not be reclaimable in any easy way.
Mel 的 方法 是将待分配的内存分为三种类型(译者注:根据其补丁的描述,分别是 UserReclaimable、KernelReclaimable 和 KernelNonReclaimable),和新增的一组 GFP_ 标志所对应(译者注, GFP 即 Get Free Page 的缩写),这些标志在申请内存时由申请者指定。如果申请者传入了 __GFP_USERRCLM 这个标记,则说明需要分配的内存将被用于用户空间而且是易于回收(reclaim)的。通常,回收用户空间所对应的页框所要做的无非就是将其备份到磁盘中(如果其内存内容已经被修改的情况下)。另外一个标志是 __GFP_KERNRCLM ,如果指定了该标记则说明本次申请的内存用于内核空间且也是可以被回收的,譬如用于 slab 的高速缓存。最后,如果既没有指明 __GFP_USERRCLM 也没有指明 __GFP_KERNRCLM 则说明本次申请的内存不能以任何简单的方式回收。
Then, the buddy allocator’s data structures are expanded to look something like this:
按照以上思路,buddy 系统的数据结构被扩展为如下所示(译者注,该图,包括下文的介绍根据的是 Mel 的 补丁最初的设计方式,最终实际合入主线的代码和这里并不一致,但大致思路是雷同的,可供借鉴):
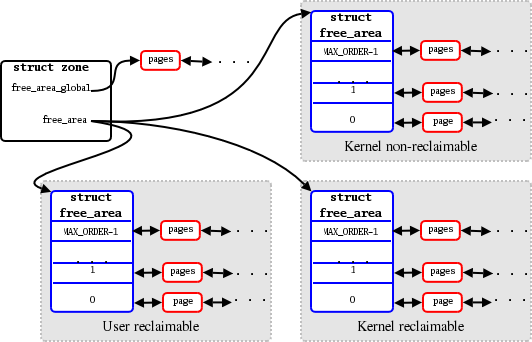
When the allocator is initialized, and all that nice, virgin memory is still unfragmented, the
free_area_globalfield points to a long list of maximally-sized blocks of memory. The threefree_areaarrays - one for each type of allocation - are initially empty. Each allocation request, when it arrives, will be satisfied from the associated free_area array if possible; otherwise, one of theMAX_ORDERblocks fromfree_area_globalwill be split up. The portion of that block which is not allocated will be placed in the array associated with the current memory allocation type.
初始化阶段内存尚未产生碎片,补丁使用 free_area_global 这个字段指向一个链表,用于维护尚未分割的最大 order 的内存块。原来的一个 free_area 数组被扩展为三个 free_area 数组,每个数组对应上节介绍的一种类型。收到内存分配请求时,如果和指定的分配类型对应的 free_area 中尚有剩余,则直接从该数组中分配;否则,内核从 free_area_global 中找到一个 order 为 MAX_ORDER 的内存块,并将其拆分。拆分后剩下未分配的内存块将被放置在与本次指定的分配类型相对应的数组中。
When memory is freed and blocks are coalesced, they remain within the type-specific array until they reach the largest size, at which point they go back onto the global array.
反之,当某内存块被归还给 buddy 系统并合并时,它们将被保留在原分配时指定的类型所对应的数组中,直到它们的大小达到最大值(order 为 MAX_ORDER),此时它们将被移回到 free_area_global。
One immediate benefit from this organization is that the pages which are hardest to get back - those in the “kernel non-reclaimable” category - are grouped together into their own blocks. A single pinned page can prevent the coalescing of a large block, so segregating the difficult kernel pages makes the management of the rest of memory easier. Beyond that, this organization makes it possible to perform active page freeing. If a high-order request cannot be satisfied, simply start with a smaller block and free up the neighboring pages. Active freeing is not yet implemented in Mel’s current patch, however.
这样组织内存的一个直接好处是,最难回收的那些页框,即类型为 “内核空间且不可回收”(”kernel non-reclaimable”) 的页框,被限定在它们自己的连续的内存块中(译者注,从上文的描述可知,任何一个页框都被赋予一个类型且只能和同类型的邻近页框进行合并)。在引入补丁修改之前,那些不可回收的页框会阻碍合并的发生,因此将这些不可回收的页框与可回收的页框隔离开来会方便我们管理可回收的内存。此外,基于该设计还可以进一步实现主动释放页框(active page freeing)的功能,即如果无法满足 high-order 内存分配请求,我们可以主动找到一个较小的内存块并释放其相邻的页框(从而试图合并并得到满足需要的较大的内存块)。但是,当前 Mel 的补丁还未考虑实现这个功能。
Even without the active component, this patch helps the kernel to satisfy large allocations. Mel gives results from a memory-thrashing test he ran; with a vanilla kernel, only three out of 160 attempted order-10 allocations were successful. With a patched kernel, instead, 81 attempts succeeded. So the new allocation technique and data structures do help the situation. What happens next remains to be seen, however; there seems to be a big hurdle to overcome when trying to get high-order allocation patches merged.
即使还未支持主动释放,这个补丁也已经能够帮助我们极大地改善内核 higher-order 内存分配的性能了。Mel 给出了压力测试的对比结果;基于主线内核(代号 vanilla),反复尝试申请 order 为 10 的大内存,160 次中只有 3 次成功。添加补丁后,同样次数申请可以成功 81 次。看起来,新的设计确实有助于改进这个问题。但这个补丁能否最终被内核主线所接受,还有很长的路要走,有待继续观察。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 | 微信打赏 | |
 |  请作者喝杯咖啡吧 |  |
Read Album:
- LWN 531148: Linux 内核文件中的非常规节
- Linux 内核的代码仓库管理与开发流程简介
- LWN 600644: 扩展内核栈
- LWN 563185: 优化抢占
- LWN 575497: 我们很快就可以有 Deadline 调度器了吗?
