

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
KDBUS 实现为一个内核驱动,真地好吗?
by Chen Jie of TinyLab.org 2015/8/9
背景
KDBUS 是内核 IPC 进化的最新努力,试图提供带有总线(Bus)概念的高级 IPC 机制。总线概念,简单的说,就是得有如下元素:
- Bus Master:创建和拥有总线,负责总线资源的仲裁。比如 Binder 中的 Service Manager(SM),DBus 中的 DBus Daemon。
- 加入总线,分得总线上的地址。对于服务提供者而言,地址是服务名。
- 总线端点间点对点的通信,以及一对多的通信。
对于此类的 IPC 机制,有若干实现上的选项:
- 使用安卓下著名的 IPC - Binder
- 增强 AF_UNIX,或者增加一个新的 socket 类型 - AF_BUS。实现总线概念。
- 像 Binder 一样,写一个设备驱动。
Binder
Binder 带着微内核上的 IPC 风格:对于微内核而言,操作系统运作更依赖进程间的消息传递。而将消息传递的开销,尽量逼近系统调用开销(及延时),能够缓解微内核性能劣势。
Binder 中,全局服务发布在 ServiceManager 中。例如,想访问服务(同时也是远程对象)“com.hello.world”,首先由 ServiceManager 的 getService() 方法 来获得其 handle。其内部过程的一个猜测如下:
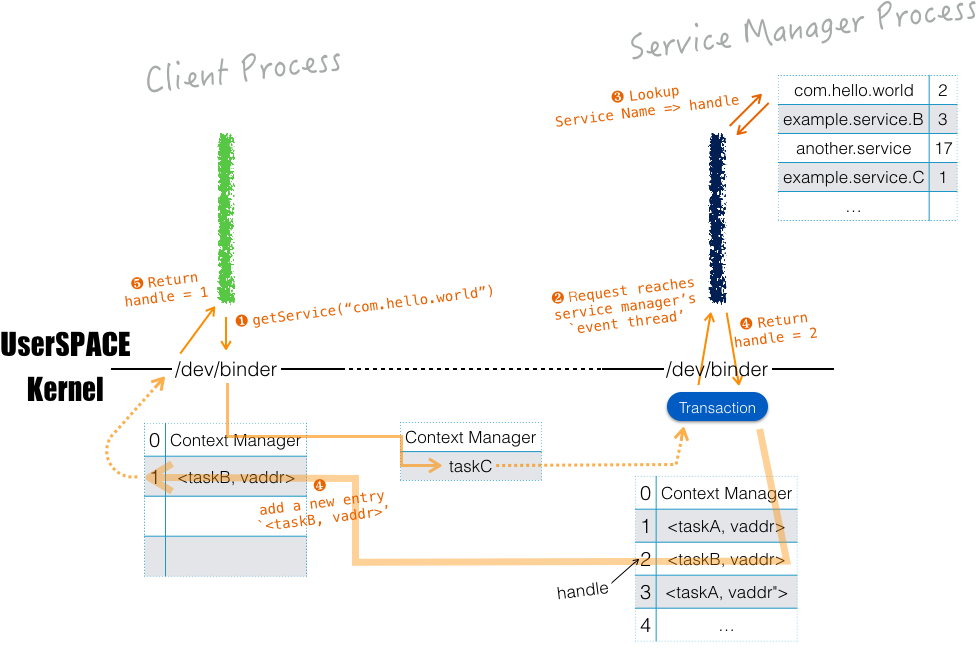
Binder 中,远程对象的 handle 可进一步传给他人,这有点像通过 UNIX socket 传 fd。
取得 handle 后,就可以进行 RPC。例如,调用 “com.hello.world” 之 hello() 方法,其内部过程的一个猜想如下:
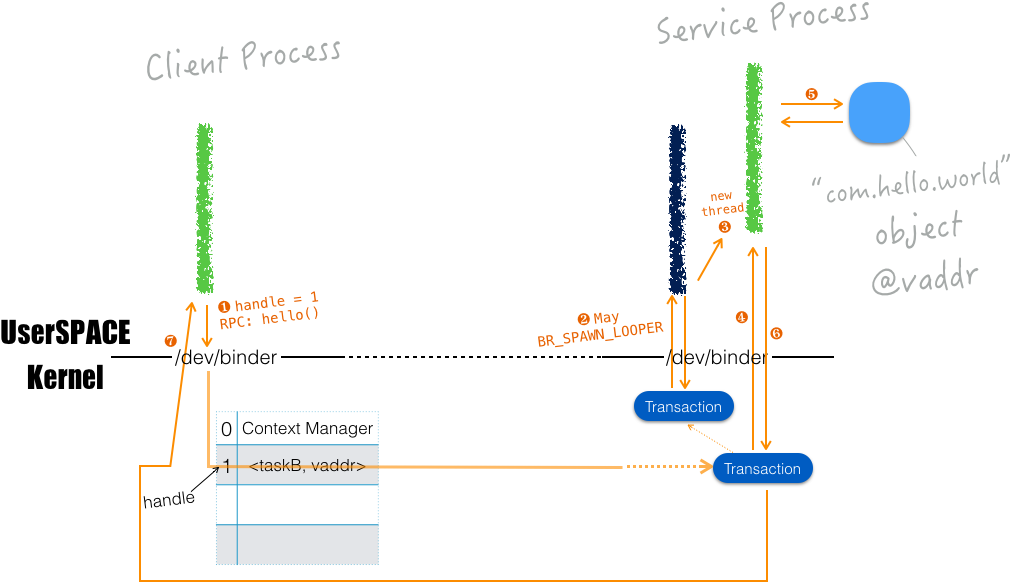
Binder 带有如下特点:
- Binder 调用都是同步的。A 向 B 发消息,致 A 暂停执行,而 B 生线程代 A 执行;B 中线程执行完将结果返回 A,A 继续执行 —— 这个过程就好像 A 发起了个系统调用一样。
- 线程优先级传递(Thread migration)。A 向 B 发消息, A 所在线程的优先级 就传递给 B 中 代 A 执行的线程。
- 节省拷贝:发送消息时,writer 直接写到 reader 的环状缓冲区中。比较 UNIX Domain 的 socket 传消息:1) writer: userspace to kernel; 2) in kernel: writer buffer to reader buffer; 3) reader: kernel to userspace,省略一次拷贝(步骤2 和 3 合并)。
- 导出本地对象:远端持有导出对象的引用,并由内核维持引用计数。
特点 1 和 2 提高确定性,并严格了优先级,有助于实时性;特点 3 降低了开销;特点 4 在于远程引用变为 0 时,得到通知,从而可实现按需启动,无请求时退出,节省资源占用。
关于 Binder 因“使用场景受限”落选,推测起来,可能是因为服务处理每一笔事务,都要对应一个线程,会受到最大线程数的限制(更糟的是,服务可能再调服务 —— 一次 IPC 背后涉及的线程会更多)。业务模型中,线程和每笔业务一一对应通常隐含伸缩受限。另一方面,KDBUS 立意于一个更加通用的使用场景,并不是局限于实时嵌入式环境。
需要说明的是,Binder 有一种 One-Way 调用,推测起来大概是 Client 将消息递送 Server 缓冲后,不等待结果,继续执行 - 即不关心结果的调用。似乎可用来实现异步的模型,例如 Server 持有 Client 的一个 Callback,通过 Callback 来返回结果。
AF_BUS
We are not creating a full address family in the kernel which exists for one, and only one, specific and difficult user —— David Miller
通过新加入一个 Address Family AF_BUS 到 socket(2) 接口中,支持总线概念 IPC 的实现。(嗯哼,我们知道常见的 socket Address Family 有 IPv4 的 AF_INET,IPv6 的 AF_INET6,kernel 与 userspace 通信的 AF_NETLINK 以及 本地进程间通信管道 AF_UNIX)
AF_BUS 的原始设计和实现由 Collabora 为 Genivi 联盟完成。
AF_BUS 原始设计中,Bus Master 通过 bind(2) 来开启一个 “Bus”;加入 bus 通过 connect(2) 调用。地址都是 64 位的,但分了不同段:某段由 kernel 来分配;某段由 Bus Master 来分配;某段是总线上的广播。并进一步引入了类似 DNS 的过程,即例如,对应到支持 DBus 实现,需将服务名映射到 64 位地址。而实现上,每个接入总线的端点有自己的 DNS 缓冲,并在需要时向 Bus Master 来更新。
从上述描述可以看出,原始设计比较冗余和复杂。
AF_BUS 被内核网络子系统维护者 David Miller 一票否决,原因似乎有这些:
- 可靠的消息多播无法实现
- 不会为 DBus 一个用户来创建一种通用 socket Address Family
KDBUS
Kdbus is clearly not ready. That is hopefully fixable. But not even admitting to the problems is not every going to get things fixed. —— Linus Torvalds
经历了 AF_BUS 之后,开发力量开始转向 KDBUS,即实现一个专一服务于 DBus 的设备驱动。风格上有点像将 socket 操作装入 ioctl(2) 中。
KDBUS 引入了 Bloom filter 算法来进行多播信息的匹配,比如当某个 DBus 服务 ready 时,总线上有如下广播:
sender=org.freedesktop.DBus dest=(null destination) path=/org/freedesktop/DBus interface=org.freedesktop.DBus member=NameOwnerChanged arg0="com.example.someservice.provider" arg1="" arg2=":1.103" // 将上述字串的集合,通过一组哈希算法,生成集合位图 bitmapMessage
某个端点通过 bus_add_match(),监听上述总线广播,如下:
match for
sender == org.freedesktop.DBus &&
path == /org/freedesktop/DBus &&
interface == org.freedesktop.DBus &&
member == NameOwnerChanged &&
arg0 == "com.example.someservice.provider" &&
// 将上述字串的集合,通过一组哈希算法,生成集合位图 bitmapMatch
则匹配过程如下:
if bitmapMessage & bitmapMatch == bitmapMatch:
// Here: bitmapMessage contains bitmapMatch
// Let's do an exact check to filter out
// bloom filter false positive
if message.sender == match.sender &&
message.path == match.path &&
message.interface == match.interface &&
message.member == match.member &&
message.arg0 == match.arg0:
// Matched!
KDBUS 最新争论在于其当前的消息可靠多播实现,导致了系统失去响应。经过数轮邮件,Linus 出面吼了吼:“I’m quite disappointed in the kdbus proponents in this thread. Dismissing clear problem reports and now this.”(对 KDBUS 开发者的辩解表示失望,并强调应正视而不是回避问题。)
再遇 AF_BUS,我们重新出发?
KDBUS 实现为设备驱动,许多调用成为没有 API 风格可言的 ioctl,确实十分难看。
对比 Binder 同样实现为设备驱动,一方面它是将微内核风格调用引入,对内核已有子系统而言也许是“异域风情”的;另一方面作为产品工程考量应优先,故采取最小影响的设备驱动。这些理由来看,Binder 的实现有其合理性。
而 KDBUS 作为一出生就立意并入内核的项目,做成了一个设备驱动来回避阻力、放弃了优雅,似乎做了回缩头乌龟。
在 KDBUS 争论中,一些开发者再次提出,AF_BUS(或增强 AF_UNIX)更加优雅。
另一方面看了 AF_BUS 原始设计,拖沓和不够简练。于是,本着自己动手,不求一蹴而就(Just for fun,right?),但求借机窥豹,了解网络子系统,在此设计了新的 AF_BUS。
struct sockaddr_bus
地址设计是此版 AF_BUS 设计简于原始设计的关键:
struct sockaddr_bus {
sa_family_t sbus_family; /* AF_BUS */
unsigned short sbus_addr_ncomp;
char sbus_path[BUS_PATH_MAX];
uint64_t sbus_addr[BUS_ADDR_COMP_MAX];
};
sockaddr_bus 有两部地址,第一部分是总线名称 .sbus_path。第二部分是总线上的地址 .sbus_addr。
举几个地址例子:
- Bus Master 创建新总线:
struct sockaddr_bus addr = {
.sbus_family = AF_BUS,
.sbus_addr_ncomp = 3
};
memcpy(addr.sbus_path, "/var/run/system_bus",
sizeof("/var/run/system_bus"));
memcpy(addr.sbus_addr, "org.freedesktop.DBus",
sizeof("org.freedesktop.DBus"));
/* 通过 bind(2) 调用,开启一个 bus */
bind(sock_fd, &addr, sizeof(struct sockaddr_bus));
总线上的地址,包括 Bus Master 己的地址,统一由 Bus Master 来分配。
- 多播地址
struct sockaddr_bus addr = {
.sbus_family = AF_BUS,
.sbus_addr_ncomp = 8
};
char *sbus_addr;
int bus_path_sz = sizeof("/var/run/system_bus");
int bus_path_aligned_sz = ((bus_path_sz + 1 /* +1 是为了结尾的 '*',见后 */)
+ 7) & ~7 /* 64 位对齐 */;
int addr_sz = 4 /* .sbus_family + .sbus_addr_ncomp */ +
bus_path_aligned_sz +
64 /* .sbus_addr_n_comp == 8 */;
memcpy(addr.sbus_path, "/var/run/system_bus", bus_path_sz);
sbus_addr = (char *) &addr + addr_sz - 64;
sbus_addr[-1] = '*'; /* 这是多播地址 */
memcpy(sbus_addr, bloom_filter_bitmap, 64);
sendto(sock_fd, message, message_sz, 0,
&addr, add_sz);
此处展示了一个紧凑排列的 sockaddr_bus, 其中,.sbus_path 这段空间以 ‘*’ 结尾,指示这是个多播地址。而多播总线地址 .sbus_addr 实质上是个 Bloom filter 中的 bitmap,从而可按照 Bloom filter 算法来进行接收匹配。
- 内核消息的地址
strcut sockaddr_bus addr = { 0, };
int addr_sz = sizeof(addr);
recvfrom(sock_fd, buf, buf_sz,
&addr, &addr_sz);
if (addr.sbus_family == AF_BUS &&
strcmp(addr.bus_path,
"/var/run/system_bus") == 0 &&
addr.sbus_addr_ncomp == 0)
// This is a message from kernel
某些时候,例如 Bus Master 需要收到总线上端点的异常退出通知,这些通知来自内核。其地址如上所示。
特权操作皆由 Bus Master 所仲裁
仲裁的形式是通过 cmsg(3) 来完成的,例如接入总线为特权操作,未接入总线的 socket 只能向 Bus Master 发接入请求:
struct msghdr msghdr = {
.msg_name = &addr, /* bus master's addr */
.msg_namelen = addr_len,
.msg_iov = &auth_iovec,
.msg_iovlen = 1,
};
msghdr.msg_controllen = CMSG_SPACE(sizeof(struct ucred));
msghdr.msg_control = alloca(msghdr.msg_controllen);
cmsg = CMSG_FIRSTHDR(&msghdr);
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_type = SCM_CREDENTIALS;
cmsg->cmsg_len = CMSG_LEN(sizeof(struct ucred));
ucred = (struct ucred *) CMSG_DATA(cmsg);
ucred->pid = getpid();
ucred->uid = getuid();
ucred->gid = getgid();
sendmsg(sock_fd, &msghdr, MSG_NOSIGNAL);
Bus Master 处理接入请求:认证接入者身份,并应用访问控制策略。若允许,则:
... msghdr.msg_iov = &reply_iovec; msghdr.msg_iovlen = 1; msghdr.msg_controllen = CMSG_SPACE(sizeof(struct sockaddr_bus)); msghdr.msg_control = alloca(msghdr.msg_controllen); cmsg = CMSG_FIRSTHDR(&msghdr); /* * 通过 Control Message 通知内核赋予 peer 总线地址 * 并将分配的地址返回给 peer */ cmsg->cmsg_level = BUS_SOCKET; cmsg->cmsg_type = SCM_OWNED_ADDR; cmsg->cmsg_len = CMSG_LEN(sizeof(struct sockaddr_bus)); memcpy(CMSG_DATA(cmsg), &ret_addr, sizeof(struct sockaddr_bus)); sendmsg(sock_fd, &msghdr, MSG_NOSIGNAL);
除了接入总线,特权操作可以是:
- 申请 well-known 的总线地址
- 申请往某个多播地址发消息
- 申请收某个多播地址的消息
- …
通用,性能和其他
AF_BUS 是为实现各种总线概念 IPC(例如 Binder 和 DBus)之基础,而不是单一服务于某个高层 IPC。另一方面,消息的可靠多播仍是实现上的重点关注。目前也有一些类似的(可靠?)多播机制,例如 netlink(7) 向多播组发送 UEVENT 消息,也许可为借鉴。
另在性能上,可以结合 eBPF 来将消息过滤转到内核进行,减少用户态不必要的唤醒。例如多播信息接收中,用 eBPF 来过滤 Bloom filter false positive(误匹配)情形。
最后,可通过传递 memfd 实现点对点的、基于共享内存的通信(无系统调用且无多余拷贝)。这种方式可进一步由高层 IPC 所封装:
bus = bus_open_fd(fd /* memfd */); // 此类“bus”上的消息可省略序列化和反序列化中的部分工作, // 例如大小尾端转换,字串编码转换等,来进一步减少额外开销
这样,在某些需极低延时的应用中,例如音频应用如 PluseAudio,也可使用 DBus 等高层 IPC,而不是私有 IPC 协议,从而进一步拓展高层 IPC 的使用面,使操作系统中的各模块更具整体性。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
