

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
“茴”字有几种写法:系统负载是怎样计算的?(二)
By Chen Jie of TinyLab.org 2017-06-29 00:20:11
前言
简单说,机器学习中的 “机器” 就是统计模型,“学习” 就是用数据来拟合模型。
「初探计算机视觉的三个源头、兼谈人工智能|正本清源」,朱松纯(Song-Chun Zhu),加州大学洛杉矶分校 UCLA 统计学和计算机科学教授
大数据时代,统计很重要。通过统计事件、定期采样,定量评估现在,对比过去,预测将来。
系统负载,以及 CPU 利用率,也是统计得到的指标。指标对实际的拟合情况分好与更好,比如在近月,大名鼎鼎的 Linux 系统调优专家 Brendan Gregg 对现有 CPU 利用率统计提出了质疑,言其误导用户。
然而,诸如系统负载目下是如何统计的?—— “不就是个 C 实现的公式吗?” —— 这似乎是一个细究 “茴” 字有多少种写法的问题。
然而,吃掉一大块油腻腻新知识,不妨先从小处入手,追本溯源,知微见著。
本系列第二部分从负载均衡来看“系统负载”如何统计。公式不是重点,内核常见的定点拟浮点会继续剐蹭,而 CPU 拓扑层次结构、CFS 则成为浮光掠影般的沿途风景。
负载均衡
Linux kernel 中,每个 CPU 有专属 runqueue,“各自为政”,减少互扰。故而可能出现“忙的忙疯”,“闲的闲慌”,于是便需要负载均衡:
- 当任务被 fork / exec / wake up,其选择 “最闲” 的 CPU,即下表的 select_task_rq_fair(): “find_idlest_group() -then- find_idlest_cpu()”。
- 每隔一定时间、或本 CPU 即将入空闲,从“最忙”的 CPU 上选取任务,分担到当前 CPU 上。选择“最忙”的 CPU,即下表的 load_balance(): “find_busiest_group() -then- find_busiest_queue()”。
负载均衡沿着 CPUs 的层次结构进行,对于表中左半部分,自上而下,全局寻求“最闲 CPU”:
/* Code Snippet of select_task_rq_fair() */
...
for_each_domain(cpu, tmp) {
/*
* 简化期间,有意忽略基于 previous CPU 局部性原理的优化
* 即只考虑达到 “均衡” 效果。
* 如代码所展示,循环退出后 sd 指向顶级的 sched_domain
*/
...
if (tmp->flags & sd_flag)
sd = tmp;
}
...
else while (sd) {
struct sched_group *group;
int weight;
...
group = find_idlest_group(sd, p, cpu, sd_flag);
...
new_cpu = find_idlest_cpu(group, p, cpu);
...
/* Now try balancing at a lower domain level of new_cpu */
cpu = new_cpu;
weight = sd->span_weight;
/*
* cpu 属于 sd,其中 weight 表示 “sd 名下的 CPU 数”(故而下面 for_each_domain
* 循环中,要求 “weight <= tmp->span_weight” 其实是要求 sd 是符合要求的、
* 包含 cpu 的低层 sched_domain)—— 不然 sd 被再次赋值,
* 大循环在 “lower domain level(than sd)” 再迭代
*/
sd = NULL;
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
if (tmp->flags & sd_flag)
sd = tmp;
}
/* while loop will break here if sd == NULL */
}
...
下图展示 CPUs 的拓扑层次结构(概念 - sched_domain 和 sched_group):
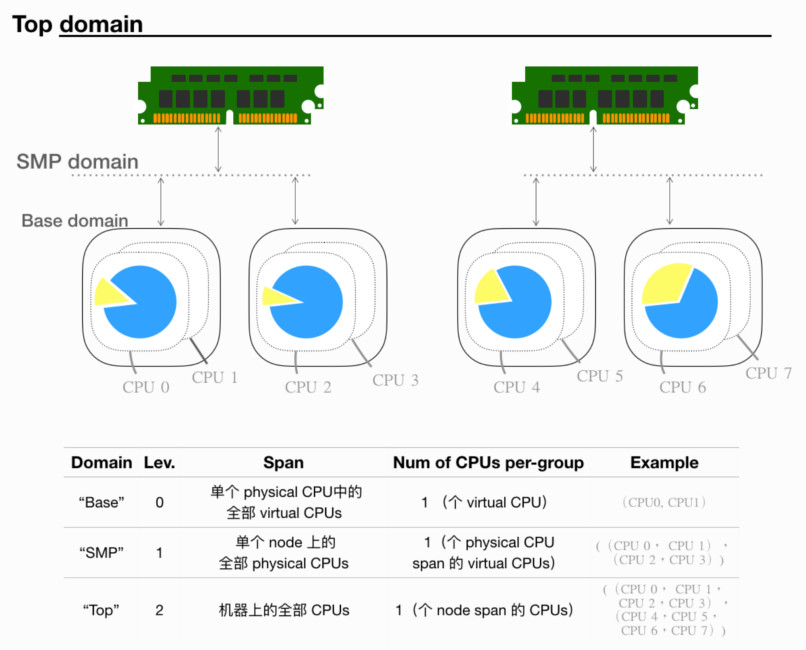
实现上,每个 level 对应一个 struct sd_data,含有 percpu 的 sched_domain / sched_group。故而可以用 sched_domain(levN, cpuK) 来表示一个 Domain,以下缩写为 “sd(N, K)”:
- sd(N-1, K) 为 sd(N, K) 的 child。
- sd(N-1, K),必然对应 sd(N, K) 的一个 group。其中,“对应”意为它们有相同的 cpumask。
- sd span 的 CPUs,可用 sched_domain_span() 得到,该函数返回一个
struct cpumask *。- sg 所属的 CPUs,可用 sched_group_cpus()得到,同样返回一
struct cpumask *。在简单情形中,若 cpuJ ∈ sd(N, K),则 sd(N, K) 与 sd(N, J) 具有相同 span、相同的一组 sched_group。
在复杂情形中(SD_OVERLAP),若 cpuJ ∈ sd(N, K),则 sd(N, J) 其 span 可能为空,此时 sd(0…N-1, J) span 都为空。找到部分线索参见:
- build_sched_domain():parent sd span 必然包含 child sd span。sd 之 span 源自
sched_domain_topology_level->sched_domain_mask_f()- build_overlap_sched_groups() 和 build_group_mask()
- init_numa_topology_type() 注释中,关于 NUMA 拓扑的描述
- sched-domains.txt
表中的右半部分,自下而上、由频转疏,找到指定层级“最忙”的 CPU,分担其任务到当前 CPU。这个过程好比遇争上诉,从基层人民法院(上诉最频繁),不服再诉中级人民法院、高级人员法院直至最高人民法院(上诉最不频繁):
/*
* Code Snippet of rebalance_domains(struct rq *rq, enum cpu_idle_type idle):
* Call Stack:run_rebalance_domains() → rebalance_domains()
* or run_rebalance_domains() → nohz_idle_balance() → rebalance_domains()
*/
...
for_each_domain(cpu, sd) {
...
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
...
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
...
/*
* Code Snippet of idle_balance(struct rq *this_rq, struct rq_flags *rf)
*/
...
for_each_domain(this_cpu, sd) {
...
if (sd->flags & SD_BALANCE_NEWIDLE) {
t0 = sched_clock_cpu(this_cpu);
pulled_task = load_balance(this_cpu, this_rq,
sd, CPU_NEWLY_IDLE,
&continue_balancing);
...
/*
* Code Snippet of load_balance(int this_cpu, struct rq *this_rq,
* struct sched_domain *sd, enum cpu_idle_type idle,
* int *continue_balancing):
*/
...
struct sched_group *group;
struct rq *busiest;
struct lb_env env = {
.sd = sd,
.dst_cpu = this_cpu,
.dst_rq = this_rq,
.dst_grpmask = sched_group_cpus(sd->groups),
.idle = idle,
.loop_break = sched_nr_migrate_break,
.cpus = cpus,
.fbq_type = all,
.tasks = LIST_HEAD_INIT(env.tasks),
};
if (!should_we_balance(&env)) {
*continue_balancing = 0;
goto out_balanced;
}
group = find_busiest_group(&env);
if (!group) {
schedstat_inc(sd->lb_nobusyg[idle]);
goto out_balanced;
}
busiest = find_busiest_queue(&env, group);
if (!busiest) {
schedstat_inc(sd->lb_nobusyq[idle]);
goto out_balanced;
}
...
env.src_cpu = busiest->cpu;
env.src_rq = busiest;
ld_moved = 0;
if (busiest->nr_running > 1) {
...
/*
* cur_ld_moved - load moved in current iteration
* ld_moved - cumulative load moved across iterations
*/
cur_ld_moved = detach_tasks(&env);
...
if (cur_ld_moved) {
attach_tasks(&env);
ld_moved += cur_ld_moved;
}
...
负载均衡的世界很大,回到主题,只看看 “负载均衡场景” 中,关于“系统负载”的计算。为简化期间,下面以 find_busiest_queue() 为出发点,进行探索之旅。
CPU 之 Capacity 和 Weighted Load
/*
* Code Snippet of find_busiest_queue(struct lb_env *env,
* struct sched_group *group)
*/
struct rq *busiest = NULL, *rq;
unsigned long busiest_load = 0, busiest_capacity = 1;
int i;
for_each_cpu_and(i, sched_group_cpus(group), env->cpus) {
unsigned long capacity, wl;
...
rq = cpu_rq(i);
...
capacity = capacity_of(i);
wl = weighted_cpuload(i);
...
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu capacity, so
* that the load can be moved away from the cpu that is
* potentially running at a lower capacity.
*
* Thus we're looking for max(wl_i / capacity_i), crosswise
* multiplication to rid ourselves of the division works out
* to: wl_i * capacity_j > wl_j * capacity_i; where j is
* our previous maximum.
*/
if (wl * busiest_capacity > busiest_load * capacity) {
busiest_load = wl;
busiest_capacity = capacity;
busiest = rq;
}
}
比较负载熟重孰轻的指标 —— “加权平均负载(weighted_cpuload)” 除 “CPU 虚拟算力”(capacity_of)。
加权平均负载
weighted_cpuload() 返回 struct cfs_rq.runnable_load_avg,后者在以下俩处更新:
- enqueue_entity_load_avg() / dequeue_entity_load_avg()
- update_cfs_rq_load_avg() →
__update_load_avg()
我们已经知道,每个 CPU 对应一个 struct rq(runqueue)。每个 sched_class 的实现,就是从 runqueue 选取 / 切换 sched_entity。对于覆盖 SCHED_NORMAL/SCHED_BATCH 的 CFS 调度器而言,其在 runqueue 有个 root cfs runqueu(rq.cfs)。cfs runqueue 用红黑树来组织 sched_entity,其中 sched_entity 背后可能是一个 task,也可能是 cfs runqueue(即所谓的 group scheduling)。
task 入列和出列时 —— enqueue_task_fair() / dequeue_task_fair() —— 会 hook 到 enqueue_entity_load_avg() / dequeue_entity_load_avg():
/* se 为入列 / 出列的 sched_entity */
struct sched_avg *sa = &se->avg;
/* 入列 */
cfs_rq->runnable_load_avg += sa->load_avg;
cfs_rq->runnable_load_sum += sa->load_sum;
/* 出列 */
cfs_rq->runnable_load_avg =
max_t(long, cfs_rq->runnable_load_avg - se->avg.load_avg, 0);
cfs_rq->runnable_load_sum =
max_t(s64, cfs_rq->runnable_load_sum - se->avg.load_sum, 0);
而 __update_load_avg(u64 now, int cpu, struct sched_avg *sa, unsigned long weight, int running, struct cfs_rq *cfs_rq) 是统计的核心函数:
- delta =
now - sa->last_update_time,时间单位为 ns,随后sa->last_update_time就被更新成 now。 - delta »= 10,采样间隔 为 ~1us(1024ns),故而 delta == 0 则放弃本次采样(此时,
sa->last_update_time不变)。 统计间隔 为 ~1ms(1024us),如下图中,某次 delta 超过了 ~1ms,分成三段分别统计 load_sum:
- 补齐:历史(非本周期)负载的统计起点,补齐到周期起始,方便计算。
- 衰减:补齐后,对历史负载,进行衰减。
- 累加:累加当前周期内的负载。
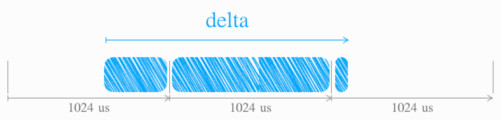
对应代码:
/*
* Code Snippet of __update_load_avg()
* 简化期间,只关注 cfs_rq->runnable_load_avg 相关,且“多功能”复用的分支被移除
*/
scale_freq = arch_scale_freq_capacity(NULL, cpu);
delta_w = sa->period_contrib; /* 前次记录的,本周期已经过的时间 */
if (delta + delta_w >= 1024) { /* 超过一个周期,进行统计 */
decayed = 1;
sa->period_contrib = 0;
/* ❶ 补齐 */
delta_w = 1024 - delta_w;
scaled_delta_w = cap_scale(delta_w, scale_freq);
sa->load_sum += weight * scaled_delta_w;
// ^^^^^^ Question 1
cfs_rq->runnable_load_sum += weight * scaled_delta_w;
delta -= delta_w;
/* ❷ 衰减 */
periods = delta / 1024;
delta %= 1024;
/* 已计入的历史负载,经历 N 周期后,进行相应衰减 */
sa->load_sum = decay_load(sa->load_sum, periods + 1);
// ^^^^^^^^^^ Question 2
cfs_rq->runnable_load_sum =
decay_load(cfs_rq->runnable_load_sum, periods + 1);
/* 尚未计入的历史(持续)负载,在 1...N 周期的各衰减求和,再计入 */
contrib = __compute_runnable_contrib(periods);
// ^^^^^^^^^^^^^^^^^^^^^^^^^^ Question 3
contrib = cap_scale(contrib, scale_freq);
sa->load_sum += weight * contrib;
cfs_rq->runnable_load_sum += weight * contrib;
}
/* ❸ 累加 */
scaled_delta = cap_scale(delta, scale_freq);
sa->load_sum += weight * scaled_delta;
cfs_rq->runnable_load_sum += weight * scaled_delta;
sa->period_contrib += delta;
/* 完成统计,更新均值 */
if (decayed) {
sa->load_avg = div_u64(sa->load_sum, LOAD_AVG_MAX);
// ^^^^^^^^^^^^ Question 4
cfs_rq->runnable_load_avg =
div_u64(cfs_rq->runnable_load_sum, LOAD_AVG_MAX);
}
一个快速 get knowledge 的方法是 ask the right questions,提问助于聚焦。就上述代码而言,此处准备了若干问题:
- 任务们在队列中呆了一段时间,便是负载(当前 CPU 的 TODO list)。计算时,负载已经随 CPU freq 缩放,那不错。但乘 weight 是作甚?换言之 weight 定义是什么?
- 衰减历史负载的算法 —— decay_load 是怎样的?
- 尚未汇入的历史负载,如何汇入并自带衰减效果?
- LOAD_AVG_MAX 的值为何是 47742?
另外,本节负载计算,涉及的全部是 CFS 治下 Normal 类型任务。那么 RT 任务是如何在负载计算中体现?答案是不体现,RT 被视作预留的 CPU 算力。下节讨论预留算力的评估。
目测 CPU 的虚拟算力
大小核的 CPU 固有不同的算力,由 capacity_orig_of() 返回,其值由 arch_scale_cpu_capacity() 给出。而 capacity_of() 返回剔除 RT 预留以后的算力。“剔除 RT 预留以后的算力” 由 update_cpu_capacity() 来更新。
想象一下,当有实时任务需严格按时完成,简单粗暴做法对标专用硬件单元。但若要 Cost down,可通过调度算法,在通用处理器中预留算力,优先供给实时任务。
在 Linux 调度器层面,任务分成 RT / Normal 和 Idle 三大类。其中 RT 任务存在时,具有 CPU 的绝对占用权,换言之,可视作被预留的算力。如下图所示:
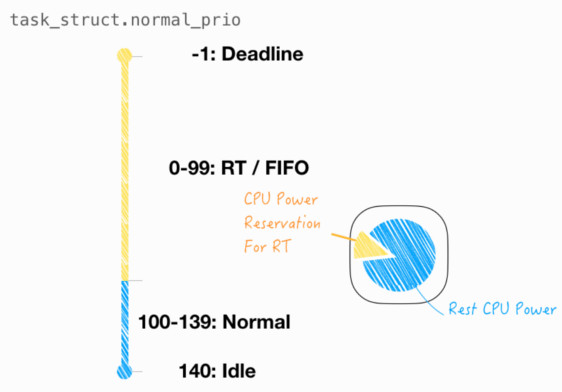
其对应代码如下:
/* ❶ Code Snippet of update_cpu_capacity() */
unsigned long capacity = arch_scale_cpu_capacity(sd, cpu);
cpu_rq(cpu)->cpu_capacity_orig = capacity;
capacity *= scale_rt_capacity(cpu);
capacity >>= SCHED_CAPACITY_SHIFT; /* 模拟浮点乘法,保留 10 位精度 */
算力折扣系数,由 “❷ scale_rt_capacity()“ 给出,其含义为一段时间内,非“RT 时间” 占比((delta + (sched_avg_period() - rt_avg)) / total or 1.0 - rt_avg / total):
/* ❷ Code Snippet of scale_rt_capacity() */
age_stamp = READ_ONCE(rq->age_stamp);
avg = READ_ONCE(rq->rt_avg);
delta = __rq_clock_broken(rq) - age_stamp;
if (unlikely(delta < 0))
delta = 0;
total = sched_avg_period() + delta;
used = div_u64(avg, total);
if (likely(used < SCHED_CAPACITY_SCALE))
return SCHED_CAPACITY_SCALE - used;
return 1;
“RT 时间” rq->rt_avg,统计自“sched_rt_avg_update()”,同样分为 ❸ 当前周期内的负载 的累加 和 ❹ 历史(非本周期) 的衰减。
/*
* ❸ Code Snippet of sched_rt_avg_update()
*
* - 调用时机:tick 落在 RT 任务时
*/
rq->rt_avg += rt_delta * arch_scale_freq_capacity(NULL, cpu_of(rq));
sched_avg_update(rq);
/*
* ❹ Code Snippet of sched_avg_update()
*
* - sched_avg_period() 返回 sysctl_sched_time_avg 的一半
* - sysctl_sched_time_avg 即 /proc/sys/kernel/sched_time_avg_ms,默认为 1s
*/
s64 period = sched_avg_period();
while ((s64)(rq_clock(rq) - rq->age_stamp) > period) {
/*
* Inline assembly required to prevent the compiler
* optimising this loop into a divmod call.
* See __iter_div_u64_rem() for another example of this.
*/
asm("" : "+rm" (rq->age_stamp));
rq->age_stamp += period;
rq->rt_avg /= 2;
}
小结
本篇从负载均衡场景,粗略介绍了负载均衡时机,以及它是沿着 CPU 多核拓扑层级进行的。随后简化在 find_busiest_queue() 中,即如何判断 CPU “最忙”,这是通过 “加权平均负载”,除上 “CPU 虚拟算力” 来归一比较。
其中,“加权平均负载”,汇总 cfs_rq 中任务的呆了多长时间,由 update_cfs_rq_load_avg() → __update_load_avg() 更新 —— 累加考虑任务的权重(weight)和 “CPU 那时频率” 的折扣;平均是按周期衰减历史值。算式的细节限于篇幅,未作展开,留若干问题,将在下一篇作答案。
“CPU 虚拟算力”,是在 CPU 实际算力基础上(arch_scale_cpu_capacity()),剔除预留给 RT 的算力。预留给 RT 算力,实际上就是 非“RT 时间” 占比。而 “RT 时间”,除了当前值 —— “频率折扣后的 RT runtime”,还包含历史值的衰减(此处衰减,相比上条要剧烈很多)。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
