

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
Android DispSync 详解
By Guo Chumou of TinyLab.org Jul 26, 2019
DispSync 是什么?
在 Android 4.1 的时候,Google 提出了著名的 “Project Butter”,引入了 VSYNC,把 app 画图,SurfaceFlinger 合成的时间点都规范了起来,减少了掉帧,增强了渲染的流畅度。但是这里有个问题,因为 VSYNC 是由硬件产生的,一旦产生了你就必须开始干活,不灵活。假设有这么一种需求,我希望在 VSYNC 偏移一段时间以后再干活,那么这个是硬件 VSYNC 提供不了,所以这个时候就必须引入软件模型。而 DispSync 就是为了解决这个需求引入的软件模型。DispSync 类似于一个 PLL(phase lock loop,锁相回路),它通过接收硬件 VSYNC,然后给其他关心硬件 VSYNC 的组件(SurfaceFlinger 和需要渲染的 app)在指定的偏移以后发送软件 VSYNC,并且当误差在可接受的范围内,将会关闭硬件 VSYNC。谷歌的这篇文档里面详细有一张非常准确的图:
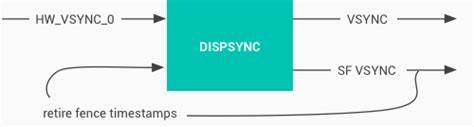
(为了方便,后面所有的硬件 VSYNC 使用 HW-VSYNC 代指,软件 VSYNC 使用 SW-VSYNC 代指)
综述
前面提到 DispSync 是一个模拟 HW-VSYNC 的软件模型,在这个模型里面包含几个部分:
DispSync
DispSync 的主体,主要负责启动 DispSyncThread,接收 HW-VSYNC 并且更新计算出 SW-VSYNC 间隔—— mPeriod
DispSyncThread
DispSync 的一个内部线程类,主要功能是模拟 HW-VSYNC 的行为,大部分时间都处于阻塞状态,利用 DispSync 算出的 mPeriod,周期性地在下一个 SW-VSYNC 时间点(加了偏移的)醒来去通知对 VSYNC 感兴趣的 Listener —— DispSyncSource
DispSyncSource
SurfaceFlinger 的一个内部类,实现了 DispSync::Callback 的接口,DispSyncThread 和 EventThread 的中间人
EventThread
VSYNC 的接收实体,收到 DispSync 的 SF-VSYNC 再进行分发,SurfaceFlinger 和 app 分别有自己的 EventThread—— sfEventThread 和 appEventThread
Connection
EventThread 内部类,任何一个对 VSYNC 感兴趣的(SurfaceFlinger,需要渲染画面的 app)都会在 EventThread 里面抽象为一个 Connection
EventControlThread
大部分博客都将其描述为硬件 VSYNC 的“闸刀”,也就是负责控制硬件 VSYNC 的开关
MessageQueue
SurfaceFlinger 用来在 sfEventThread 注册
DisplayEventReceiver
app 用来在 appEventThread 注册
下面来详细描述一下整个初始化的流程。
初始化
首先说明一下,DispSync 的初始化流程初看是十分复杂的,首先它涉及到比较多的线程,并且线程在很多时候是处于阻塞状态的,导致整个流程处于一个不连续的状态。因此谁把哪个线程唤醒了就变得十分重要,这也是理解整个初始化过程中的一个难点。
DispSync 和 DispSyncThread-01
DispSync 在 SurfaceFlinger 里只有一个实例 —— mPrimaryDipsSync,它在 SurfaceFlinger 的初始化分两部分,创建实例 mPrimaryDispSync 然后执行其 init() 方法。DispSync 的构造函数非常简单,都是一些赋值:
DispSync::DispSync(const char* name)
: mName(name), mRefreshSkipCount(0), mThread(new DispSyncThread(name)) {}
explicit DispSyncThread(const char* name)
: mName(name),
mStop(false),
mPeriod(0),
mPhase(0),
mReferenceTime(0),
mWakeupLatency(0),
mFrameNumber(0) {}
然后来看 init() 方法:
void DispSync::init(bool hasSyncFramework, int64_t dispSyncPresentTimeOffset) {
mIgnorePresentFences = !hasSyncFramework;
mPresentTimeOffset = dispSyncPresentTimeOffset;
mThread->run("DispSync", PRIORITY_URGENT_DISPLAY + PRIORITY_MORE_FAVORABLE);
// set DispSync to SCHED_FIFO to minimize jitter
struct sched_param param = {0};
param.sched_priority = 2;
if (sched_setscheduler(mThread->getTid(), SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO for DispSyncThread");
}
reset();
beginResync();
...
}
DispSycn::init() 最主要的就是工作就是让 DispSyncThread 运行起来,并且将其调度优先级改为 SCHED_FIFO,这样做的目的是什么呢?我们前面提到,DispSyncThread 大部分时间都在阻塞,它会“睡”到下次 SW-VSYNC 开始的时间戳,因此当其被唤醒的时候,高优先级能够保证其尽快地被调度,减少误差。执行完 mThread->run() 以后,就会开始执行 DispSyncThread::threadLoop():
virtual bool threadLoop() {
status_t err;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
while (true) {
Vector<CallbackInvocation> callbackInvocations;
nsecs_t targetTime = 0;
{ // Scope for lock
Mutex::Autolock lock(mMutex);
...
if (mStop) {
return false;
}
if (mPeriod == 0) {
err = mCond.wait(mMutex);
// 第一次初始化,由于 mPeriod 为 0,所以会先 block 在这里
目前 DispSyncThread 会阻塞在这里,我们接下去看。
EventThread-01
在 SurfaceFlinger 初始化的时候,会创建两个 EventThread,一个给 SurfaceFlinger,一个给 app:
void SurfaceFlinger::init() {
...
// start the EventThread
mEventThreadSource =
std::make_unique<DispSyncSource>(&mPrimaryDispSync, SurfaceFlinger::vsyncPhaseOffsetNs,
true, "app");
mEventThread = std::make_unique<impl::EventThread>(mEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
impl::EventThread::InterceptVSyncsCallback(),
"appEventThread");
mSfEventThreadSource =
std::make_unique<DispSyncSource>(&mPrimaryDispSync,
SurfaceFlinger::sfVsyncPhaseOffsetNs, true, "sf");
mSFEventThread =
std::make_unique<impl::EventThread>(mSfEventThreadSource.get(),
[this]() { resyncWithRateLimit(); },
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
},
"sfEventThread");
前面提到,DispSyncSource 是 DispSyncThread 和 EventThread 的中间人,先来看一下 DispSyncSource 的构造函数:
class DispSyncSource final : public VSyncSource, private DispSync::Callback {
public:
DispSyncSource(DispSync* dispSync, nsecs_t phaseOffset, bool traceVsync,
const char* name) :
mName(name),
mValue(0),
mTraceVsync(traceVsync),
mVsyncOnLabel(String8::format("VsyncOn-%s", name)),
mVsyncEventLabel(String8::format("VSYNC-%s", name)),
mDispSync(dispSync),
mCallbackMutex(),
mVsyncMutex(),
mPhaseOffset(phaseOffset),
mEnabled(false) {}
请注意这里有一个非常重要的点,就是 mVsyncEventLabel(String8::format("VSYNC-%s", name))。SurfaceFlinger 的 DispSyncSource 传进来的 name 是 “sf”,app 的 DispSyncSource 传进来的 name 是 “app”,所以连起来就是 “VSYNC-sf” 和 “VSYNC-app”。为什么说重要呢?来看一段 systrace:

这里面的 VSYNC-app 和 VSYNC-sf 就是说的 DispSyncSource,至于它的意义,后面会提到。
然后 DispSyncSource 作为参数传给 EventThread 的构造函数:
EventThread::EventThread(VSyncSource* src, ResyncWithRateLimitCallback resyncWithRateLimitCallback,
InterceptVSyncsCallback interceptVSyncsCallback, const char* threadName)
: mVSyncSource(src),
mResyncWithRateLimitCallback(resyncWithRateLimitCallback),
mInterceptVSyncsCallback(interceptVSyncsCallback) {
for (auto& event : mVSyncEvent) {
event.header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
event.header.id = 0;
event.header.timestamp = 0;
event.vsync.count = 0;
}
mThread = std::thread(&EventThread::threadMain, this);
pthread_setname_np(mThread.native_handle(), threadName);
pid_t tid = pthread_gettid_np(mThread.native_handle());
// Use SCHED_FIFO to minimize jitter
constexpr int EVENT_THREAD_PRIORITY = 2;
struct sched_param param = {0};
param.sched_priority = EVENT_THREAD_PRIORITY;
if (pthread_setschedparam(mThread.native_handle(), SCHED_FIFO, ¶m) != 0) {
ALOGE("Couldn't set SCHED_FIFO for EventThread");
}
set_sched_policy(tid, SP_FOREGROUND);
}
构造函数的最主要功能就是把 EventThread 的线程主体 threadMain 运行起来并且设置其优先级为 SCHED_FIFO,接下来看 threadMain:
void EventThread::threadMain() NO_THREAD_SAFETY_ANALYSIS {
std::unique_lock<std::mutex> lock(mMutex);
while (mKeepRunning) {
DisplayEventReceiver::Event event;
Vector<sp<EventThread::Connection> > signalConnections;
signalConnections = waitForEventLocked(&lock, &event);
// dispatch events to listeners...
const size_t count = signalConnections.size();
for (size_t i = 0; i < count; i++) {
const sp<Connection>& conn(signalConnections[i]);
// now see if we still need to report this event
status_t err = conn->postEvent(event);
...
}
}
threadMain 的主要工作是调用 waitForEventLocked 等待一个 Event,然后在一个个地通知 signalConnections。至于这个 Event 和 signalConnections 分别是什么,后面会具体描述。现在先来看一下 waitForEventLocked 的逻辑:
// This will return when (1) a vsync event has been received, and (2) there was
// at least one connection interested in receiving it when we started waiting.
Vector<sp<EventThread::Connection> > EventThread::waitForEventLocked(
std::unique_lock<std::mutex>* lock, DisplayEventReceiver::Event* event) {
Vector<sp<EventThread::Connection> > signalConnections;
while (signalConnections.isEmpty() && mKeepRunning) {
bool eventPending = false;
bool waitForVSync = false;
size_t vsyncCount = 0;
nsecs_t timestamp = 0;
// 在前面 EventThread 的构造函数里面已经把 mVSyncEvent 数组内的所有 timestamp 都置为 0
// 因此在第一次初始化的时候,这个循环会直接退出
for (int32_t i = 0; i < DisplayDevice::NUM_BUILTIN_DISPLAY_TYPES; i++) {
...
}
// 第一次初始化的时候 mDisplayEventConnections 的数组也为空,count 为 0
size_t count = mDisplayEventConnections.size();
if (!timestamp && count) {
...
}
// 第一次初始化不执行这个循环
for (size_t i = 0; i < count;) {
...
}
// timestamp 为 0, waitForVSync 为 false
if (timestamp && !waitForVSync) {
...
} else if (!timestamp && waitForVSync) {
...
}
// eventPending 为 false,符合条件
if (!timestamp && !eventPending) {
if (waitForVSync) {
...
// waitForVSync 为 false,进入 else
} else {
// 最终,在第一次初始化的时候,EventThread 就阻塞在这里了
mCondition.wait(*lock);
}
}
}
...
}
好,到这里,SurfaceFlinger 创建的两个 EventThread 都会阻塞在上面代码提到的地方,SurfaceFlinger 的初始化继续执行。
补充:SurfaceFlinger 的启动
首先说明一下 mEventQueue 是在哪里被初始化的。是在 SurfaceFlinger 的另一个方法:
提到这里就需要 SurfaceFlinger 是怎么启动和初始化的。SurfaceFlinger 作为系统最基本最核心的服务之一,是通过 init.rc 的方式进行启动的(内容在 frameworks/native/services/surfaceflinger/surfaceflinger.rc):
service surfaceflinger /system/bin/surfaceflinger
class core animation
user system
group graphics drmrpc readproc input
onrestart restart zygote
...
然后就需要提到 SurfaceFlinger 的组成部分,init.rc 里面提到的 /system/bin/surfaceflinger 这个二进制文件,由 main_surfaceflinger.cpp 这个文件编译得到;而上面提到 DispSync,EventThread 等,都被编译到了 libsurfaceflinger.so 这个库。这也给了我们一个启示:当我们在自己调试 SurfaceFlinger 的时候,大部分时间都只需要重新编译 libsurfaceflinger.so 这个文件即可。
回来简单看一下 SurfaceFlinger 是如何启动的,来看看 main_surfaceflinger.cpp:
int main(int, char **) {
...
sp<SurfaceFlinger> flinger = DisplayUtils::getInstance()->getSFInstance();
...
flinger->init();
...
这里的重点就是这个 sp<SurfaceFlinger>,当被 sp 指针引用的时候,会触发 onFirstRef() 函数:
void SurfaceFlinger::onFirstRef()
{
mEventQueue->init(this);
}
这样,就走到了 MessageQueue 部分了:
MessageQueue
接着 EventThread,然后就执行到这里:
void SurfaceFlinger::init() {
...
mEventQueue->setEventThread(mSFEventThread.get());
mEventQueue 在前面的 SurfaceFlinger::onFirstRef() 中完成了初始化:
void MessageQueue::init(const sp<SurfaceFlinger>& flinger) {
mFlinger = flinger;
mLooper = new Looper(true);
mHandler = new Handler(*this);
}
接着来看一下很重要的 setEventThread():
void MessageQueue::setEventThread(android::EventThread* eventThread) {
if (mEventThread == eventThread) {
return;
}
if (mEventTube.getFd() >= 0) {
mLooper->removeFd(mEventTube.getFd());
}
mEventThread = eventThread;
mEvents = eventThread->createEventConnection();
mEvents->stealReceiveChannel(&mEventTube);
mLooper->addFd(mEventTube.getFd(), 0, Looper::EVENT_INPUT, MessageQueue::cb_eventReceiver,
this);
}
重点来了,前面创建的 SurfaceFlinger 的 EventThread 被作为参数传给了 setEventThread,并且执行了 EventThread 的 createEventConnection()。(注意,需要时时刻刻地记住,现在处理的 SurfaceFlinger 的 EventThread)
(后面为了方便,将使用 sfEventThread 指代 SurfaceFlinger 的 EventThread;使用 appEventThread 指代 app 的 EventThread)
EventThread::Connection
sp<BnDisplayEventConnection> EventThread::createEventConnection() const {
return new Connection(const_cast<EventThread*>(this));
}
在这里,sfEventThread 迎来了第一个(同时也是唯一的) Connection:
EventThread::Connection::Connection(EventThread* eventThread)
: count(-1), mEventThread(eventThread), mChannel(gui::BitTube::DefaultSize) {}
void EventThread::Connection::onFirstRef() {
// NOTE: mEventThread doesn't hold a strong reference on us
mEventThread->registerDisplayEventConnection(this);
}
status_t EventThread::registerDisplayEventConnection(
const sp<EventThread::Connection>& connection) {
std::lock_guard<std::mutex> lock(mMutex);
mDisplayEventConnections.add(connection);
mCondition.notify_all();
return NO_ERROR;
}
MessageQueue 调用 sfEventThread 的 createEventConnection 创建一个 Connection。由于 sp 指针的作用,将会调用 Connection::onFirstRef,最终这个 Connection 会被添加到 mDisplayEventConnections 并且唤醒在 EventThread - 01 中阻塞的线程。
EventThread-02
在前面把 EventThread 唤醒后,由于 signalConnections 为空,继续循环。然后由于新加入的 Connection count 为 -1,所以这个 EventThread 会继续阻塞,不过此时 mDisplayEventConnections 里面已经有一个 Connection 了。接着看下去。
EventControlThread-01
SurfaceFlinger::init() 接着运行到这里:
void SurfaceFlinger::init() {
...
mEventControlThread = std::make_unique<impl::EventControlThread>(
[this](bool enabled) { setVsyncEnabled(HWC_DISPLAY_PRIMARY, enabled); });
主要提一下的是,这个传进来的参数是一个 Lambda 表达式,具体的语法不讲。稍微解释一下这里传进来的 Lambda 表达式的意义就是,捕获列表为 SurfaceFlinger 本身,接受一个布尔参数,当这个 Lamda 表达式被调用的时候,会调用 SurfaceFlinger::setVsyncEnabled() 这个函数,这个函数后面会提到,也是一个很重要的函数。
EventControlThread 的构造函数的主要内容也是启动一个线程:
EventControlThread::EventControlThread(EventControlThread::SetVSyncEnabledFunction function)
: mSetVSyncEnabled(function) {
pthread_setname_np(mThread.native_handle(), "EventControlThread");
pid_t tid = pthread_gettid_np(mThread.native_handle());
setpriority(PRIO_PROCESS, tid, ANDROID_PRIORITY_URGENT_DISPLAY);
set_sched_policy(tid, SP_FOREGROUND);
}
void EventControlThread::threadMain() NO_THREAD_SAFETY_ANALYSIS {
auto keepRunning = true;
auto currentVsyncEnabled = false;
while (keepRunning) {
mSetVSyncEnabled(currentVsyncEnabled);
std::unique_lock<std::mutex> lock(mMutex);
// keepRunning 为 true,currentVsyncEnabled 为 false,mVsyncEnabled 默认值为 false,mKeepRunning 默认值为 true,因此 Lambda 表达式为 false,线程阻塞
mCondition.wait(lock, [this, currentVsyncEnabled, keepRunning]() NO_THREAD_SAFETY_ANALYSIS {
return currentVsyncEnabled != mVsyncEnabled || keepRunning != mKeepRunning;
});
currentVsyncEnabled = mVsyncEnabled;
keepRunning = mKeepRunning;
}
}
此时,EventControlThread 也会陷入阻塞之中。而 SurfaceFlinger 也将迎来初始化中最为复杂的一步。
唤醒所有线程
至此,SurfaceFlinger 总共起了四个线程 —— DispSyncThread,两个 EvenThread 和 EventControlThread,并且这四个线程全都处于阻塞状态。导致这些线程处于阻塞状态的原因是:
- DispSyncThread:
mPeriod为 0 - EventThread:
Connection->count为 -1 - EventControlThread:
mVsyncEnabled为 false
然后让我们一个个将其唤醒。
EventThread-03
接下来的 SurfaceFlinger 会进行非常复杂的初始化操作,EventThread 唤醒相关的调用流程如下(这里借用了这位大佬《Android SurfaceFlinger SW Vsync模型》的内容,写得非常棒,在学习的过程中能够得到了很大的启发):
initializeDisplays();
flinger->onInitializeDisplays();
setTransactionState(state, displays, 0);
setTransactionFlags(transactionFlags);
signalTransaction();
mEventQueue->invalidate();
mEvents->requestNextVsync() //mEvents是Connection实例
EventThread->requestNextVsync(this);
void EventThread::requestNextVsync(const sp<EventThread::Connection>& connection) {
...
if (connection->count < 0) {
connection->count = 0;
mCondition.notify_all();
}
}
在这里把前面创建的那个 Connection 的 count 置为 0,并且唤醒阻塞的 EventThread,这个时候,mDisplayEventConnections 不为空并且 count 不为 -1,可以正常地运行了,EventThread::waitForEventLocked() 走到了这里:
} else if (!timestamp && waitForVSync) {
// we have at least one client, so we want vsync enabled
// (TODO: this function is called right after we finish
// notifying clients of a vsync, so this call will be made
// at the vsync rate, e.g. 60fps. If we can accurately
// track the current state we could avoid making this call
// so often.)
enableVSyncLocked();
}
void EventThread::enableVSyncLocked() {
// 一般都为 false
if (!mUseSoftwareVSync) {
// never enable h/w VSYNC when screen is off
if (!mVsyncEnabled) {
mVsyncEnabled = true;
mVSyncSource->setCallback(this);
mVSyncSource->setVSyncEnabled(true);
}
}
mDebugVsyncEnabled = true;
}
调用了 DispSyncSource::setCallback(),将 EventThread 和 DispSyncSource 联系在了一起:
void setCallback(VSyncSource::Callback* callback) override{
Mutex::Autolock lock(mCallbackMutex);
mCallback = callback;
}
接着调用 DispSyncSource::setVSyncEnabled:
void setVSyncEnabled(bool enable) override {
Mutex::Autolock lock(mVsyncMutex);
// true
if (enable) {
status_t err = mDispSync->addEventListener(mName, mPhaseOffset,
static_cast<DispSync::Callback*>(this));
...
}
最终调用了 DispSync::addEventListener:
status_t addEventListener(const char* name, nsecs_t phase, DispSync::Callback* callback) {
if (kTraceDetailedInfo) ATRACE_CALL();
Mutex::Autolock lock(mMutex);
// 保证了 mEventListeners 的唯一性
for (size_t i = 0; i < mEventListeners.size(); i++) {
if (mEventListeners[i].mCallback == callback) {
return BAD_VALUE;
}
}
EventListener listener;
listener.mName = name;
listener.mPhase = phase;
listener.mCallback = callback;
listener.mLastEventTime = systemTime() - mPeriod / 2 + mPhase - mWakeupLatency;
mEventListeners.push(listener);
// 唤醒 DispSyncThread
mCond.signal();
return NO_ERROR;
}
把 DispSyncSource 加到 mEventListeners,将 DispSync 和 DispSyncSource 联系在了一起,并且把前面阻塞的 DispSyncThread 唤醒,但是由于 mPeriod 还是为 0,因此 DispSyncThread 还是会继续阻塞。
不过此时从调用关系已经初步可以看到前面我说的那句 DispSyncSource 是 DispSync 和 EventThread 的中间人 是正确的了。
接着来看 DispSyncThread。
DispSync 和 DispSyncThread-02
设置 mPeriod 的流程如下(依旧引用了这位大佬的《Android SurfaceFlinger SW Vsync模型》的内容,再次感谢):
initializeDisplays();
flinger->onInitializeDisplays();
setPowerModeInternal()
resyncToHardwareVsync(true);
repaintEverything();
这里把 SurfaceFlinger::resyncToHardwareVsync() 分为两部分,先看上部分:
void SurfaceFlinger::resyncToHardwareVsync(bool makeAvailable) {
Mutex::Autolock _l(mHWVsyncLock);
if (makeAvailable) {
mHWVsyncAvailable = true;
} else if (!mHWVsyncAvailable) {
// Hardware vsync is not currently available, so abort the resync
// attempt for now
return;
}
const auto& activeConfig = getBE().mHwc->getActiveConfig(HWC_DISPLAY_PRIMARY);
const nsecs_t period = activeConfig->getVsyncPeriod();
mPrimaryDispSync.reset();
// 设置 mPeriod
mPrimaryDispSync.setPeriod(period);
// 默认为 false
if (!mPrimaryHWVsyncEnabled) {
mPrimaryDispSync.beginResync();
// 上部分结束
在 DispSync::setPeriod() 里面给 mPeriod 赋值,并且把 DispSyncThread 唤醒:
void DispSync::setPeriod(nsecs_t period) {
Mutex::Autolock lock(mMutex);
mPeriod = period;
mPhase = 0;
mReferenceTime = 0;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
}
void updateModel(nsecs_t period, nsecs_t phase, nsecs_t referenceTime) {
if (kTraceDetailedInfo) ATRACE_CALL();
Mutex::Autolock lock(mMutex);
mPeriod = period;
mPhase = phase;
mReferenceTime = referenceTime;
ALOGV("[%s] updateModel: mPeriod = %" PRId64 ", mPhase = %" PRId64
" mReferenceTime = %" PRId64,
mName, ns2us(mPeriod), ns2us(mPhase), ns2us(mReferenceTime));
// 这里把 DispSyncThread 唤醒
mCond.signal();
}
至此,DispSyncThread 也开始运转。
EventControlThread-02
接着看 SurfaceFlinger::resyncToHardwareVsync() 的下半部分:
...
mEventControlThread->setVsyncEnabled(true);
mPrimaryHWVsyncEnabled = true;
}
}
void EventControlThread::setVsyncEnabled(bool enabled) {
std::lock_guard<std::mutex> lock(mMutex);
mVsyncEnabled = enabled;
// 把 EventControlThread 唤醒
mCondition.notify_all();
}
把 EventControlThread 唤醒以后,会重新把 SurfaceFlinger 传进来的那个被 Lambda 表达式包裹的 SurfaceFlinger::setVsyncEnabled() 重新执行一下:
void SurfaceFlinger::setVsyncEnabled(int disp, int enabled) {
ATRACE_CALL();
Mutex::Autolock lock(mStateLock);
getHwComposer().setVsyncEnabled(disp,
enabled ? HWC2::Vsync::Enable : HWC2::Vsync::Disable);
}
void HWComposer::setVsyncEnabled(int32_t displayId, HWC2::Vsync enabled) {
if (displayId < 0 || displayId >= HWC_DISPLAY_VIRTUAL) {
ALOGD("setVsyncEnabled: Ignoring for virtual display %d", displayId);
return;
}
RETURN_IF_INVALID_DISPLAY(displayId);
// NOTE: we use our own internal lock here because we have to call
// into the HWC with the lock held, and we want to make sure
// that even if HWC blocks (which it shouldn't), it won't
// affect other threads.
Mutex::Autolock _l(mVsyncLock);
auto& displayData = mDisplayData[displayId];
if (enabled != displayData.vsyncEnabled) {
ATRACE_CALL();
auto error = displayData.hwcDisplay->setVsyncEnabled(enabled);
RETURN_IF_HWC_ERROR(error, displayId);
displayData.vsyncEnabled = enabled;
char tag[16];
snprintf(tag, sizeof(tag), "HW_VSYNC_ON_%1u", displayId);
// 在 systrace 看到的就是在这里
ATRACE_INT(tag, enabled == HWC2::Vsync::Enable ? 1 : 0);
}
}
在这里,真正地去开启 HW-VSync。然后由于 SurfaceFlinger 接收了 HW-VSync,然后辗转发给 DispSync,DispSync 接收,校正 SW-VSYNC。而整个 DispSync SurfaceFlinger 部分的初始化的流程也最终完成。
注意,上面说的是 SurfaceFlinger 部分。前面提到,总共有两个 EventThread,而上面分析的都是 sfEventThread,下面简单地描述一下 appEventThread 的流程,其实 EventThread 到 DispSync 这部分都是一致的,只是 EventThread 的 Connection 的注册流程不一样。sfEventThread 是 MessageQueue 去注册 Connection,而 appEventThread 则是另一种方法。
appEventThread
SurfaceFlinger 接收 VSYNC 是为了合成,因此 sfEventThread 的 Connection 只有一个,就是 SurfaceFlinger 本身;而 app 接收 VSYNC 是为了画帧,appEventThread 会有很多很多个 Connection。
app 本身是如何在 appEventThread 注册一个 Connection 的,与这篇文章的主体有点偏移,这个可以另开一篇文章来详细说明,流程也是非常复杂,这里只简单地描述:核心就是 libgui 下面的 DisplayEventReceiver,它在初始化的时候会调用 SurfaceFlinger::createEventConnection:
sp<IDisplayEventConnection> SurfaceFlinger::createDisplayEventConnection(
ISurfaceComposer::VsyncSource vsyncSource) {
if (vsyncSource == eVsyncSourceSurfaceFlinger) {
return mSFEventThread->createEventConnection();
} else {
return mEventThread->createEventConnection();
}
}
然后后面的流程就跟前面的一致了。
小结
通过上面的描述,依据各个类的依赖关系,其实可以总结出这么一个图:
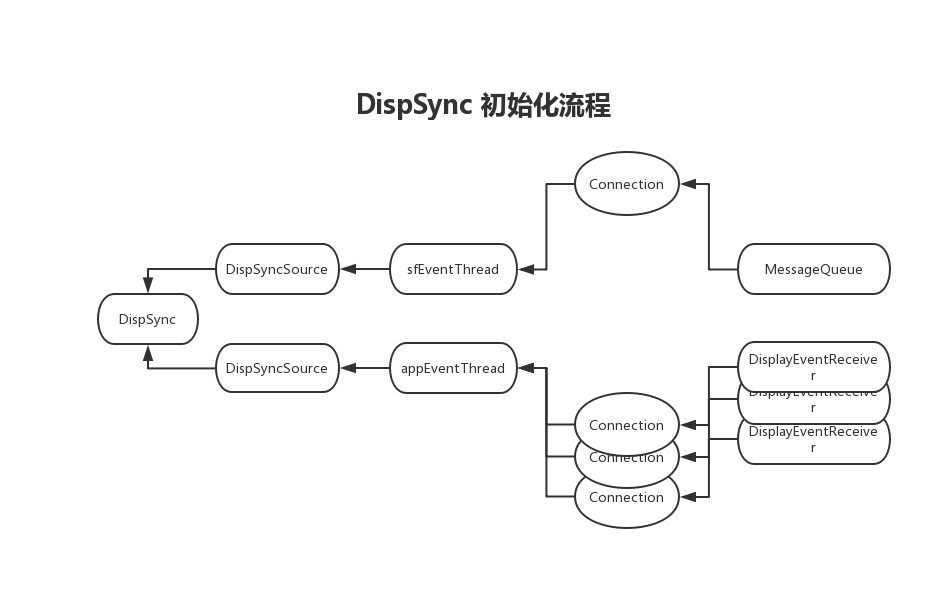
请注意箭头方向。
运作流程
前面提到,引入 DispSync 的目的是为了通过 SF-VSYNC 来模拟 HW-VSYNC 的行为并且通过加入 offset 来让通知时机变得灵活。因此理解整个 DispSync 的流程就可以归结为下面几个部分:SF-VSYNC 通知周期 mPeriod 的计算;SF-VSYNC 的模拟方式以及 SF-VSYNC 传递流程,分别来看。
mPeriod 计算逻辑
前面提到,DispSync 通过接收 HW-VSYNC 并且更新计算出 SW-VSYNC 间隔—— mPeriod,首先看一下 DispSync 是如何收到 HW-VSYNC。
先看一下 SurfaceFlinger 这个类:
class SurfaceFlinger : public BnSurfaceComposer,
public PriorityDumper,
private IBinder::DeathRecipient,
private HWC2::ComposerCallback
SurfaceFlinger 实现了 HW2::ComposerCallback 的接口,然后当 HW-VSYNC 到来的时候,HWC 会将 HW-VSYNC 发生的时间戳发给 SurfaceFlinger,然后 SurfaceFlinger 会转发给 DispSync:
class ComposerCallbackBridge : public Hwc2::IComposerCallback {
public:
...
Return<void> onVsync(Hwc2::Display display, int64_t timestamp) override
{
mCallback->onVsyncReceived(mSequenceId, display, timestamp);
return Void();
}
...
};
void SurfaceFlinger::onVsyncReceived(int32_t sequenceId,
hwc2_display_t displayId, int64_t timestamp) {
...
{ // Scope for the lock
Mutex::Autolock _l(mHWVsyncLock);
if (type == DisplayDevice::DISPLAY_PRIMARY && mPrimaryHWVsyncEnabled) {
needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp);
}
}
// 这个很重要,后面会提到
if (needsHwVsync) {
enableHardwareVsync();
} else {
disableHardwareVsync(false);
}
}
重点看 DispSync 怎么处理这些 HW-VSYNC,是在 addResyncSample() 这个函数:
bool DispSync::addResyncSample(nsecs_t timestamp) {
Mutex::Autolock lock(mMutex);
size_t idx = (mFirstResyncSample + mNumResyncSamples) % MAX_RESYNC_SAMPLES;
mResyncSamples[idx] = timestamp;
if (mNumResyncSamples == 0) {
mPhase = 0;
mReferenceTime = timestamp;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
}
if (mNumResyncSamples < MAX_RESYNC_SAMPLES) {
mNumResyncSamples++;
} else {
mFirstResyncSample = (mFirstResyncSample + 1) % MAX_RESYNC_SAMPLES;
}
updateModelLocked();
if (mNumResyncSamplesSincePresent++ > MAX_RESYNC_SAMPLES_WITHOUT_PRESENT) {
resetErrorLocked();
}
...
bool modelLocked = mModelUpdated && mError < (kErrorThreshold / 2);
return !modelLocked;
}
这里需要重点说明这里面几个变量的意义(在 DispSync.h 这个头文件里面有说明):
- mPeriod 这个就是 DispSync 根据 HW-VSYNC,计算出来的 SW-VSYNC 的时间间隔,单位是纳秒。 这里有人可能会有疑问,这个值的意义在哪?硬件是以一个固定的时间间隔去发 HW-VSYNC,为什么还需要去计算一个新的时间间隔?直接跟 HW-VSYNC 的时间间隔一致不行吗? 这个当做作业留给大家思考。
- mPhase 这个说实话我看了好久一直都看不懂这个值的意义
- mReferenceTime 这个是第一次收到 HW-VSYNC 的时间戳,用来当做 DispSync 的参考标准
- mWakeupLatency DispSyncThread 是通过睡到下一次 SW-VSYNC 应该发生的时间戳来模拟 HW-SYNC 的,但是这种“睡”到特定时间点肯定是有延迟的。通过计算睡醒的时间戳和目标时间戳就可以算出这个延迟,总延迟不能超过 1.5ms
- mResyncSample 长度 32,用来记录收到硬件 VSYNC 的时间戳的数组,不过被解释为一个 ring buffer,新的会覆盖旧的
- mFirstResyncSample 记录了 mResyncSample 这个 ring buffer 的开头
- mNumResyncSamples 接收到硬件 VSYNC 的个数
DispSync 将从 SurfaceFlinger 发来的 HW-VSYNC 的时间戳都给记录到一个 ring buffer,当有了足够多的 HW-VSYNC 了以后(目前是 6 个即以上),就可以开始来拟合 SF-VSYNC 的间隔 mPeriod 了,是在 DispSync::updateModelLocked() 里面计算的,核心算法就在这里了。分为两部分,一部分是 mPeriod 的计算:
void DispSync::updateModelLocked() {
if (mNumResyncSamples >= MIN_RESYNC_SAMPLES_FOR_UPDATE) {
nsecs_t durationSum = 0;
nsecs_t minDuration = INT64_MAX;
nsecs_t maxDuration = 0;
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
size_t prev = (idx + MAX_RESYNC_SAMPLES - 1) % MAX_RESYNC_SAMPLES;
nsecs_t duration = mResyncSamples[idx] - mResyncSamples[prev];
durationSum += duration;
minDuration = min(minDuration, duration);
maxDuration = max(maxDuration, duration);
}
durationSum -= minDuration + maxDuration;
mPeriod = durationSum / (mNumResyncSamples - 3);
...
mPeriod 的计算十分简单,把所有的 HW-VSYNC 前后相减算出 HW-VSYNC 的时间间隔,然后去掉一个最小值和最大值,然后所有 HW-VSYNC 的时间戳之和除以总个数就是 mPeriod 了。这里有一个问题就是为什么在最后除的时候是除数是 3?其实很简单,因为前面的 for 循环是从 1 开始算起的,所以循环结束一下 durationSum 其实是 mNumResyncSamples - 1 个 HW-VSYNC 的总和,然后再去掉一个最大和最小,所以总数是 mNumResyncSamples - 3。
另一部分是 mPhase 的计算,这一块看上去好像挺复杂的,甚至还有三角函数:
...
double sampleAvgX = 0;
double sampleAvgY = 0;
// scale 的意义是,每 ms 代表了多少度。(总量除以总个数等于每个的值)
double scale = 2.0 * M_PI / double(mPeriod);
// Intentionally skip the first sample
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
// sample 是误差
nsecs_t sample = mResyncSamples[idx] - mReferenceTime;
// 这里 (sample % mPeriod) 看上去挺唬人的,但是其实就是保证 sample 不会大于或者等于 mPeriod,否则这里的 samplePhase 算出来就是 2π 了
// 所以这里 samplePhase 算出来的就是把误差转成度数
double samplePhase = double(sample % mPeriod) * scale;
// 这两个后面是为了用来计算误差平均的度数
sampleAvgX += cos(samplePhase);
sampleAvgY += sin(samplePhase);
}
sampleAvgX /= double(mNumResyncSamples - 1);
sampleAvgY /= double(mNumResyncSamples - 1);
// 根据等比关系,算出平局误差度数对应的 ns 值
mPhase = nsecs_t(atan2(sampleAvgY, sampleAvgX) / scale);
ALOGV("[%s] mPhase = %" PRId64, mName, ns2us(mPhase));
if (mPhase < -(mPeriod / 2)) {
mPhase += mPeriod;
ALOGV("[%s] Adjusting mPhase -> %" PRId64, mName, ns2us(mPhase));
}
if (kTraceDetailedInfo) {
ATRACE_INT64("DispSync:Period", mPeriod);
ATRACE_INT64("DispSync:Phase", mPhase + mPeriod / 2);
}
// Artificially inflate the period if requested.
mPeriod += mPeriod * mRefreshSkipCount;
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
mModelUpdated = true;
上面的逻辑其实可以用下图来阐述:
而 mPhase 最终是根据下面的等比公式计算出来的:\[\frac{2\pi}{mPeriod} = \frac{Angle}{mPhase}\]
最后,看一下 DispSync::addResyncSample 这个函数的返回值,这个返回值非常重要,当通过统计 SW-VSYNC 的误差小于阈值的时候(这个误差的计算涉及到了 Fence,目前我对这部分内容理解得还不是很透彻,等彻底理解了以后再来填坑),返回 true 给 SurfaceFlinger 的时候,SurfaceFlinger 则会调用 SurfaceFlinger::disableHardwareVsync 把 HW-VSYNC 给关了。
SW-VSYNC 的生成与传递
mPeriod 计算出来以后,DispSyncThread 就可以依据这个值来模拟 HW-VSYNC 了(实际上计算流程和模拟流程是相互独立的,分别在两个不同的线程上完成),所以流程都在 DispSyncThread 的 threadLoop() 里面:
virtual bool threadLoop() {
status_t err;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
while (true) {
Vector<CallbackInvocation> callbackInvocations;
nsecs_t targetTime = 0;
{ // Scope for lock
Mutex::Autolock lock(mMutex);
if (mStop) {
return false;
}
if (mPeriod == 0) {
err = mCond.wait(mMutex);
if (err != NO_ERROR) {
ALOGE("error waiting for new events: %s (%d)", strerror(-err), err);
return false;
}
continue;
}
// 这里计算出下一个确切的 SW-VSYNC 的时间戳
targetTime = computeNextEventTimeLocked(now);
bool isWakeup = false;
if (now < targetTime) {
if (targetTime == INT64_MAX) {
err = mCond.wait(mMutex);
} else {
// 睡到下一个 SW-VSYNC 为止
err = mCond.waitRelative(mMutex, targetTime - now);
}
if (err == TIMED_OUT) {
isWakeup = true;
} else if (err != NO_ERROR) {
return false;
}
}
now = systemTime(SYSTEM_TIME_MONOTONIC);
// Don't correct by more than 1.5 ms
static const nsecs_t kMaxWakeupLatency = us2ns(1500);
if (isWakeup) {
mWakeupLatency = ((mWakeupLatency * 63) + (now - targetTime)) / 64;
mWakeupLatency = min(mWakeupLatency, kMaxWakeupLatency);
}
callbackInvocations = gatherCallbackInvocationsLocked(now);
}
if (callbackInvocations.size() > 0) {
fireCallbackInvocations(callbackInvocations);
}
}
return false;
}
这里通过依据 mPeriod 算出下一个 SW-VSYNC 的时间戳,计算 SW-VSYNC 的时间戳的逻辑比较简单,就不过多描述。然后通过条件变量直接睡到下一个 SW-VSYNC,然后一个个地通过调用 DispSyncSource 的 onDispSyncEvent 回调来进行 SW-VSYNC 的通知。然后 DispSyncSource 的 onDispSyncEvent 又会调用 EventThread 的 onVSyncEvent:
void EventThread::onVSyncEvent(nsecs_t timestamp) {
std::lock_guard<std::mutex> lock(mMutex);
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = 0;
mVSyncEvent[0].header.timestamp = timestamp;
mVSyncEvent[0].vsync.count++;
mCondition.notify_all();
}
这里就可以回答一下在提到的问题,mVSyncEvent 和 mDisplayEventConnections 以及 signalConnections 这三个数组的意义和区别:
- mVSyncEvent 一个长度为 NUM_BUILTIN_DISPLAY_TYPES 的数组,代表这一个 Vsync Event,这个可能是 VSYNC 事件,也有可能是屏幕插拔这种事件等。这个 NUM_BUILTIN_DISPLAY_TYPES 是一个 enum 变量:
enum DisplayType {
DISPLAY_ID_INVALID = -1,
DISPLAY_PRIMARY = HWC_DISPLAY_PRIMARY,
DISPLAY_EXTERNAL = HWC_DISPLAY_EXTERNAL,
DISPLAY_VIRTUAL = HWC_DISPLAY_VIRTUAL,
NUM_BUILTIN_DISPLAY_TYPES = HWC_NUM_PHYSICAL_DISPLAY_TYPES,
};
从这里就可以看到,至少在这个版本的 Android 除了一个 virtual display(这是 SurfaceFlinger 提供的一个非常有用的功能,很多常见的需求例如录屏就是通过 virtual display 来实现的,这里不展开,有需要的话再写一篇文章详细描述)已经是支持多屏幕了,只不过呢,目前的代码里面都是写死只处理主屏,也就是 Display 0 的事件。
- mDisplayEventConnections
这个就是用来存储前面提到的
EventThread::Connection的数组,在调用EventThread::registerDisplayEventConnection()的时候,就会把这个 Connection 加到这个数组里面。 - signalConnections
EventThread::waitForEventLocked最大的作用就是返回这个数组,这个数组存的是所有希望接收下一个 SW-VSYNC 的 Connection,而是否接收 Connection 的标志是 connection->count 的值:-1 代表不接收 SW-VSYNC;0 代表只接收一次,EventThread 发现 connection->count 的值为 0 的时候,会把它加到 signalConnections 以便其能够接受到这一次的 SW-VSYNC 之后,会将其 count 置为 -1;大于 0 就表明会一直接收。
onVSyncEvent 的作用是新增一个 VSyncEvent 并且把 EventThread 唤醒,EventThread 统计了所有对 SW-VSYNC 感兴趣的 Connection 并且都加到 signalConnections,最后会通过一个循环调用每个 connection 的 postEvent() 函数,SurfaceFlinger 就会开始走合成的流程,app 就会开始走渲染的流程。至此,SW-VSYNC 完成了传递的全过程。
小结
当整个初始化完成以后,整个 DispSync 模型就开始运作起来了。我们先简单地把整个流程描述一下:
SurfaceFlinger 通过实现了
HWC2::ComposerCallback接口,当 HW-VSYNC 到来的时候,SurfaceFlinger 将会收到回调并且发给 DispSync。DispSync 将会把这些 HW-VSYNC 的时间戳记录下来,当累计了足够的 HW-VSYNC 以后(目前是大于等于 6 个),就开始计算 SW-VSYNC 的偏移 mPeriod。计算出来的 mPeriod 将会用于 DispSyncThread 用来模拟 HW-VSYNC 的周期性起来并且通知对 VSYNC 感兴趣的 Listener,这些 Listener 包括 SurfaceFlinger 和所有需要渲染画面的 app。这些 Listener 通过 EventThread 以 Connection 的抽象形式注册到 EventThread。DispSyncThread 与 EventThread 通过 DispSyncSource 作为中间人进行连接。EventThread 在收到 SW-VSYNC 以后将会把通知所有感兴趣的 Connection,然后 SurfaceFlinger 开始合成,app 开始画帧。在收到足够多的 HW-VSYNC 并且在误差允许的范围内,将会关闭通过 EventControlThread 关闭 HW-VSYNC。
然后这个流程我们可以得到下面这张跟初始化非常接近,只是方向相反的 SW-VSYNC 的传递图:
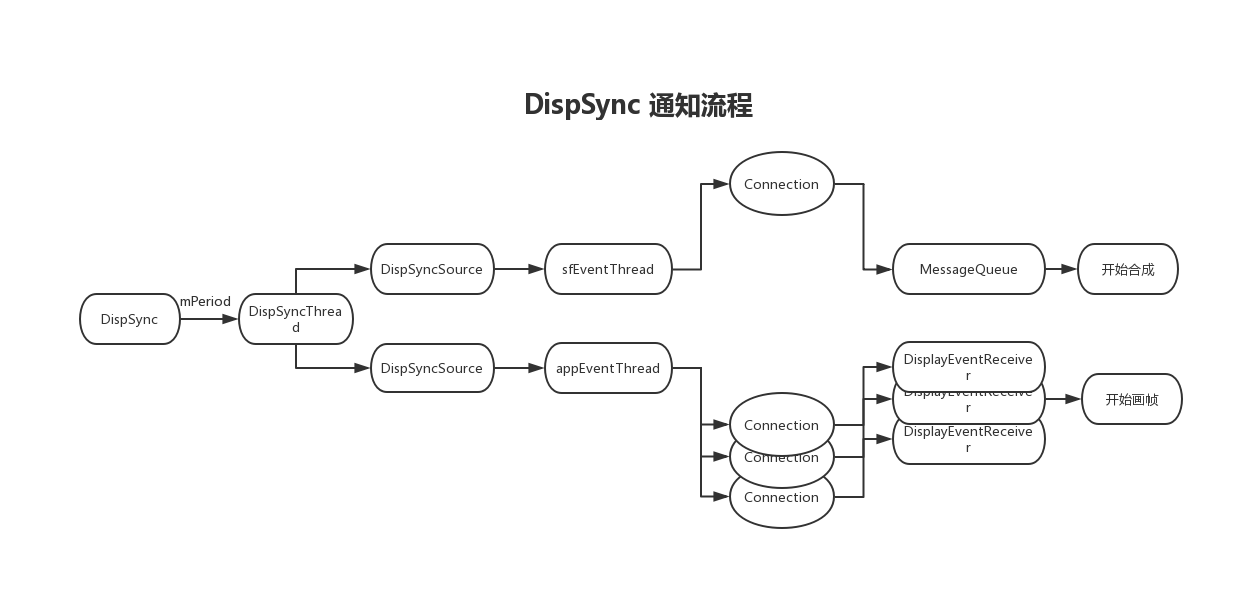
为什么要引入偏移
写了这么多内容,可能很多人还是无法理解引入软件模型的意义所在,前面我们提到是让整个流程更加灵活这句话可能也不是很好理解,因此在这里详细描述一下。
首先呢,先来看一下 DispSync 的第一个提交的 commit message,它详细地描述了引入了 DispSync 的初衷:
commit faf77cce9d9ec0238d6999b3bd0d40c71ff403c5
Author: Jamie Gennis <jgennis@google.com>
Date: Tue Jul 30 15:10:32 2013 -0700
SurfaceFlinger: SW-based vsync events
This change adds the DispSync class, which models the hardware vsync event
times to allow vsync event callbacks to be done at an arbitrary phase offset
from the hardware vsync. This can be used to reduce the minimum latency from
Choreographer wake-up to on-screen image presentation.
Bug: 10624956
Change-Id: I8c7a54ceacaa4d709726ed97b0dcae4093a7bdcf
意思就是希望能够通过 DispSync 来减少 app 渲染的内容到屏幕的事件延迟,也就是传说中的跟手性。这里需要说明一下从 app 渲染画面到显示到屏幕的一个简易 pipeline(这部分内容参考了这篇博客,建议细读,写得十分好!)。
首先需要说明的是,为了严格保证显示的流畅,防止画面撕裂的情况发生,画面更新到屏幕面板需要在 HW-VSYNC 开始的时候才做。
没有 DispSync 的时候:
- 第 1 个 HW-VSYNC 到来時, App 正在画 N, SF 与 Display 都沒 buffer 可用
- 第 2 个 HW-VSYNC 到来時, App 正在画 N+1, SF 组合 N, Display 沒 Buffer 可显示
- 第 3 个 HW-VSYNC 到来時, App 正在画 N+2, SF 组合 N+1, Display 显示 N
- 第 4 个 HW-VSYNC 到来時, App 正在画 N, SF 组合 N+2, Display 显示 N+1
从上面这个简易的 pipeline 可以看到,App 画的帧得得两个 HW-VSYNC 之后才能显示到屏幕面板上,也就是大概 33.3ms。但是,现在大部分的情况是,硬件的性能已经足够快了,画一帧的时间和合成的时间不需要一个 HW-VSYNC 了,这个时候 DispSync 的作用就来了。通过引入 offset,当 offset 为正值时,App 和 SurfaceFlinger 都是在 HW-VSYNC 往后 offset ms 才开始工作的,这个时候 App 画帧到最终显示到面板上的延迟就变成了 (2 * VSYNC_PERIOD - (offset % VSYNC_PERIOD)),这样就变相地减少了这个延迟,增强了跟手性,其实这个就是当初引入 DispSync 的初衷。
反过来可以这么想,假设把 offset 变为负值,这个时候 App 渲染和 SurfaceFlinger 合成可用的时间就变长了,在某些负载比较重的场景,这个可以优化渲染性能。
甚至还有这种情况,假设在某些场景,App 渲染和 SurfaceFlinger 合成的总时间都足够短,那么如果设置合理的话,例如 app 的 offset 设置为 0,SurfaceFlinger 的 offset 设置为 VSYNC_PERIOD/2,那么就能够保证 App 渲染到显示到面板的时间差在一个 HW-VSYNC 内完成。
从上面的分析就可以看到,这个就是引入软件模型的灵活性的体现,根据不同的需求对 offset 进行不同的取值,可以得到不同的效果。
有什么用?
学了 DispSync 有什么用呢?其实不是说学了 DispSync 有用,而是透过 DispSync 我们学到了 VSYNC 分发的整个流程,这个能够去解释很多问题。这里举一个例子。前段时间一加 7 Pro 推出了首款 90 Hz 屏幕的手机,很多评测机构都纷纷表示,微博滑动等界面感觉更加流畅了,这背后的原理是什么呢?这个时候就可以使用前面学到的知识来分析一波了。这里的 90 Hz 指的就是 HW-VSYNC。然后根据前面的渲染 pipeline,在没有 DispSync 的情况下,由于 HW-VSYNC 的从普通的 60 Hz变成了 90 Hz,VSYNC 的时间间隔从 16.6ms 减少到了 11.1ms,从前面的 pipeline 可以得出,app 从渲染到显示的延迟减少了 10ms 左右,这个延迟减少是十分明显的,因此会有一个“流畅”的感觉。因此能否这么想的,当屏幕的刷新率变成了 90 Hz 甚至是 120 Hz 以后,DispSync 的作用可能就越来越小了,那个时候谷歌会不会把它去掉呢?这个可以看一下后面 Android 的改动,至少在目前,在这个 90 Hz 即将普及的今天,Android Q 的 DispSync 还是保留着的。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥6.66元 | 微信打赏 ¥6.66元 | |
 |  请作者喝杯咖啡吧 |  |
