

[置顶] 泰晓 RISC-V 实验箱,配套 30+ 讲嵌入式 Linux 系统开发公开课
认识神经网络:推理是怎样一种负载
by Chen Jie of TinyLab.org 2020/06/09
前言
在 PC 和移动端设备中,多媒体算得上是传统的计算密集型负载。伴随 Resolution 从 720P 到 4K,伴随 Codec 从 MPEG4 到 H264 再到 H265,伴随编码场合的增加,每一次对硬件算力提出更多要求。
直到..神经网络兴起,其推理负载一跃成为算力顶级巨兽。那么,与传统多媒体应用相比,推理负载有什么不同呢?
首先铺垫一些神经网络的背景,熟悉的童鞋可以跳过。
背景:认识神经网络
下面从一个物体识别网络(SSD)来快速建立第一印象。
本例子取自 SSD object detection: Single Shot MultiBox Detector for real-time processing,Jonathan Hui
另需指出,相关技术日新月异,本例提及技术已非 state of art,但仍值得以它入手,来了解下神经网络。
物体识别网络其效果如下图:

这个结果示意图中,网络识别出了两类、五个物体:
- 最左 1 个 Binding Box,标签为“15”(person)的买菜大叔。置信度为 0.953
- 其余 4 个 Binding Boxes, 标签为“7”(car)的四辆小汽车。留意最右 Binding box 的汽车,由于裁减和遮挡的缘故,置信度只有 0.562。
产生上述结果的神经网络 —— SSD 如下图所展示: 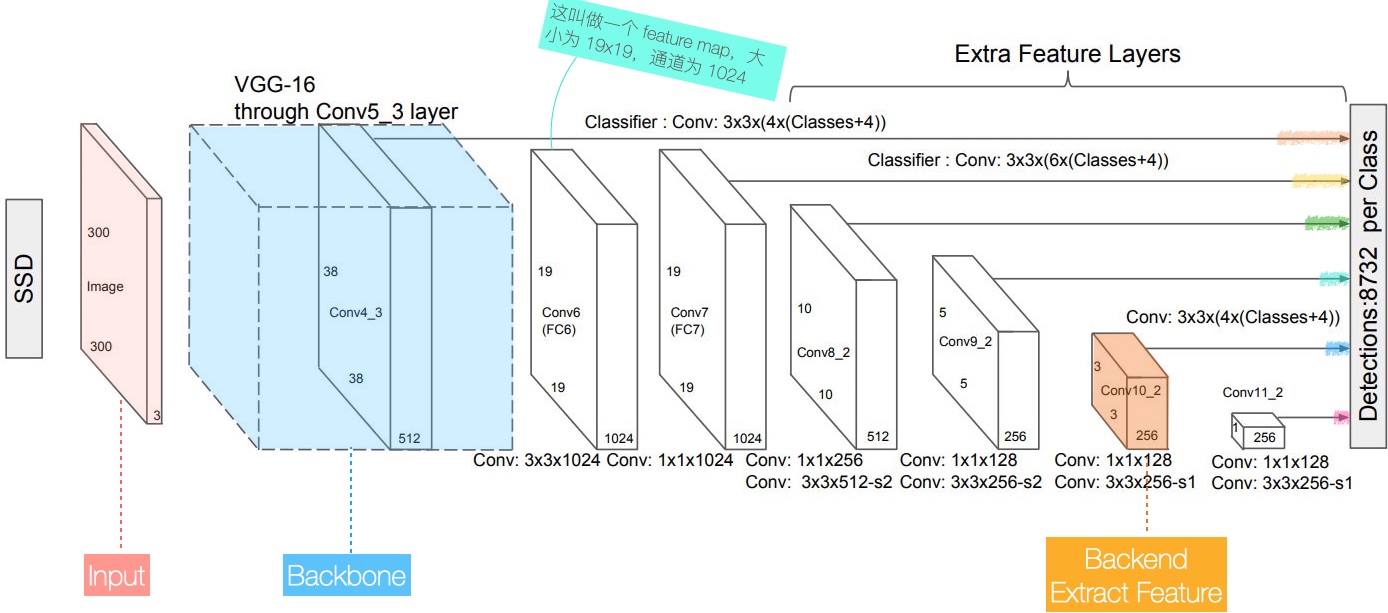
- Input:输入图片,300x300,3 通道 (R/G/B)
- Backbone:图示骨干网是 VGG-16
留意到骨干网的输入为 300x300x3,输出为 19x19x1024
- 尺寸缩小:300x300 → 19x19
- 通道变多:3 → 1024
论文曰:将画面中的信息编码在高维空间。故而 Backbone 也称作编码器。
与之相对的,在像素分割任务中,会把高维空间中的信息,逐一解开到平面,故而也叫做解码器。
考虑如何从 编码在高维空间中的信息 中提取最终结果。
首先,什么是最终结果?它分为两部分:
- Binding box —— x,y, width, height
- Binding box 在各类别的置信度。例如分 20 类(20 Classes),加上背景类(No Object),总共 21 类 —— 就有 21 个置信度
其次,该网络会在 6 个不同的分辨率上(图中,用于提取的 Feature map 尺寸分别为 38x38、19x19、10x10、5x5、3x3、1x1),输出物体识别结果,其中:
- Feature map 尺寸越大,其像素对应原图区域越小,从而注重原图细节 —— 对小尺寸物体敏感。
- Feature map 尺寸越小,其像素对应原图区域(术语曰:Receptive field,感受野)越大,从而注重大局 —— 对占据原图半壁江山的大尺寸物体,识别效果好。
最后,上图中橙色标出了某个分辨率 输出最终结果 的过程
- Feature map 尺寸为 3x3,它输出了 3x3x4 个结果
- 每个结果有 64,即 Binding box 本身,以及 60 个分类(含背景)
- 其中,3x3x4 代表了 Anchor boxes 的数量。
- “4” 代表对每个像素,分别生成了 4 个 Anchor boxes
- 什么是 Anchor boxes 呢?下图为一个 8x8 Feature Map,某个像素上的 4 个 Anchor boxes
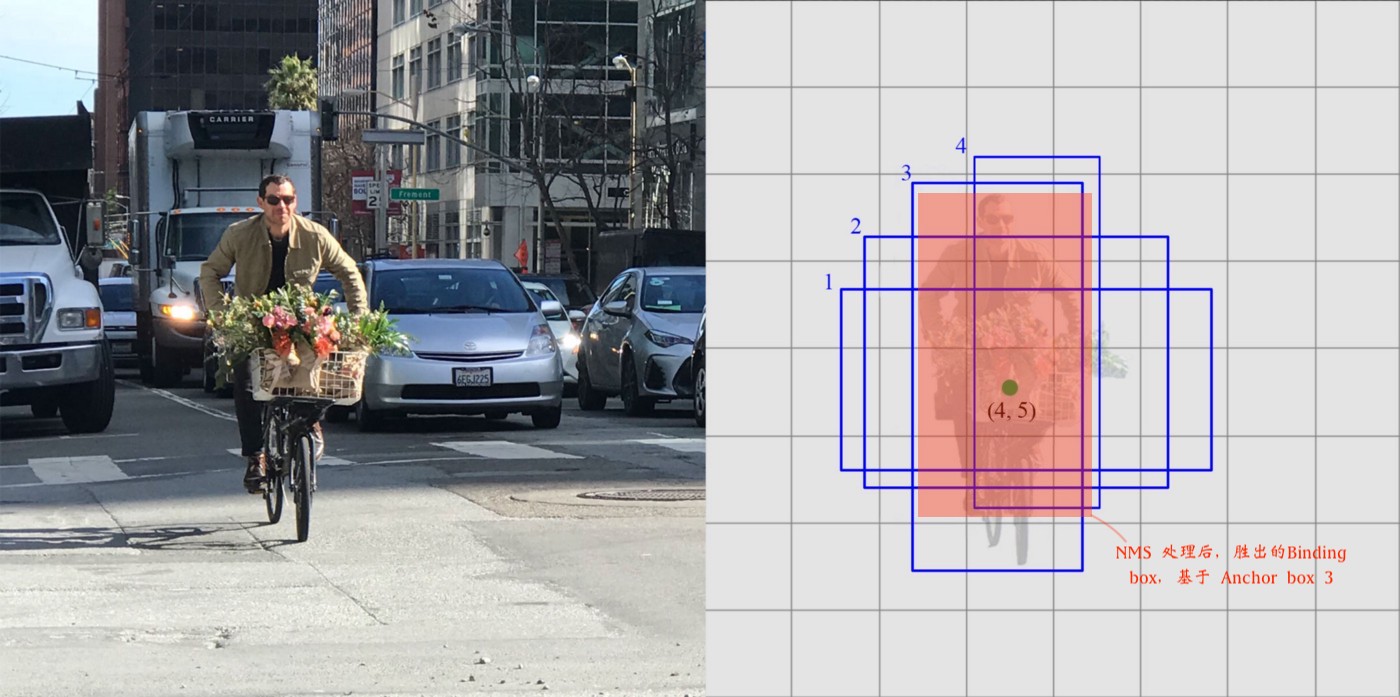
- 基于某个 Anchor box,网络推理出一个 Binding box (𝜟cx,𝜟cy, w, h)
- 此时,买菜大叔的每个像素就有 4 个候选 Binding boxes
- —— 需要 pk 出最佳 Binding box
- pk 通过名为 “NMS 的后处理” 来进行。NMS 意为非极大值抑制(Non Maximum Suppression)
Convolution:神经网络的基础算子
在上述 SSD 网络中,每一层几乎都是 Conv 算子。
Conv 是一个提取空域信息的算子,由它构成的神经网络叫做 CNN(Convolutional Neural Network)。
与之相对的,RNN 网络是一个提取时域信息的网络,常用于如语音识别。它也由基本算子所组成。
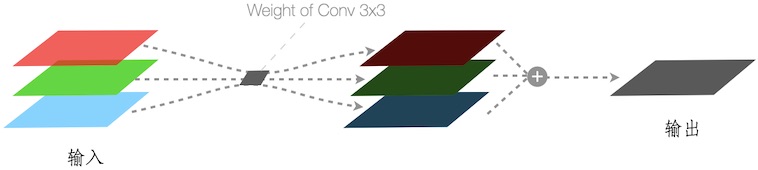
下图展示了一个 3x3 的 Conv 算子,其水平和垂直方向的 stride 为 2,padding 为 1:

- 输入图片经 padding 后,尺寸为 5x5
- 对其邻近的 3x3 个像素 ,与对应的 3x3 个权重 相乘,输出一个像素
对输入单个通道(例如,R、G 或 B 其一), Convolution 伪代码示意如下:
/**
* Input: W = 5, H = 5 | Conv: KW = 3, KH = 3
* Output: | Stride = 2
*/
for (int i = 0; i <= H - KH; i += S)
for (int j = 0; j <= W - KW; i += S) { // 对每个 3x3 邻近区域
for (int k = 0; k < KH; k++)
for (int l = 0; l < KW; l++)
//Output += Input * Weight
O[i / 2][j / 2] += I[i + k][j + l] * W[k][l];
}
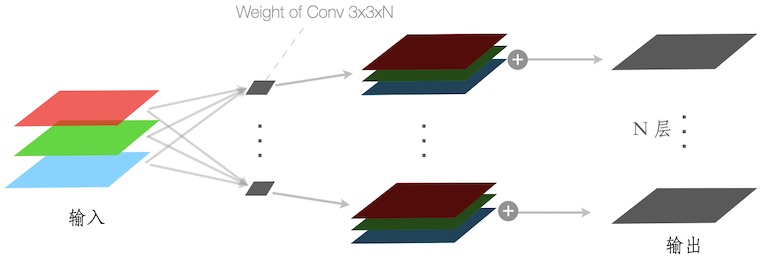
当考虑输入有 R / G / B 三个通道时,各输出结果,需进一步累加成一张图,如下图:
当考虑 Convolution 深度为 N 时,输出结果也有 N 个通道,如下图:
此时,Convolution 的权重文件是一个 3x3xN 的矩阵。
而所谓训练神经网络训练,或深度学习,就是在一次次迭代中,更新权重的过程。
训练后的网络,其权重通常是固定的。 用权重固定的网络计算得结果,叫做推理。例如用上述训练好的 SSD,检测工地施工人员,是否佩戴安全帽。
在附录中,进一步展示了不同参数和不同类型的 Convolutions。
Graph:算子构成的网络
下图手绘一组算子构成的神经网络,或叫做 Graph
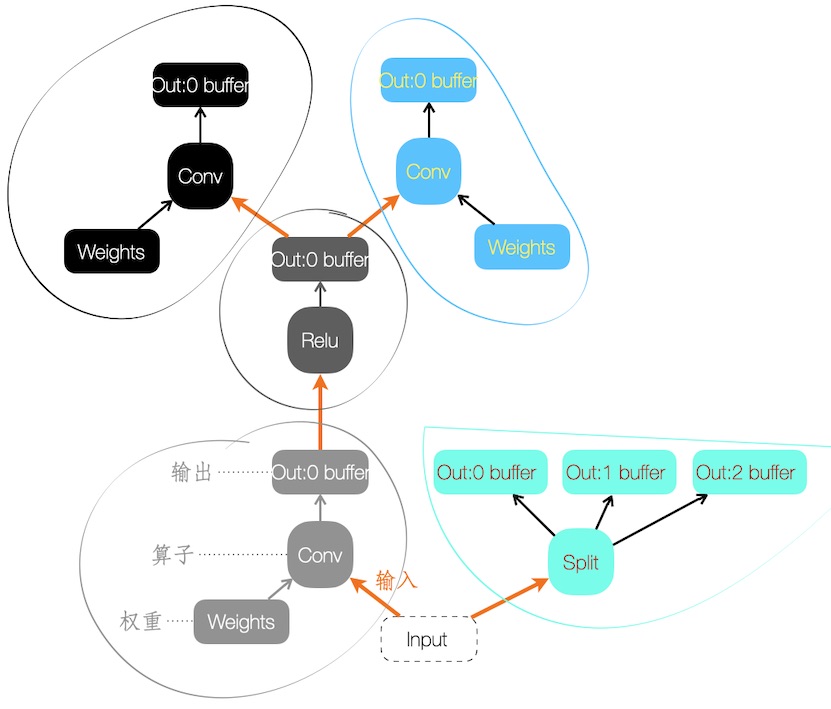
图中的节点,由三部分组成:
- 算子本身,包括类型和属性。例如某个 Convolution 算子,属性为 dim=3x3x256、stride=1、padding = …
- 算子输出的 Buffer(s)。可能输出多个 Buffers,例如图中的 Split 算子
- 算子的权重。并非每个算子都有
- 有权重的算子可被训练
而在调用网络时,需喂给它 Buffer(s) 作为输入,即图中的 Input。在 Tensorflow 称之为 Placeholder。
此处,插播一下 Buffer 格式简介。 一般而言是 4 维的 NCHW 或者 NHWC 格式
- N 代表 batch,例如某个自动驾驶方案配备了左右摄像头,那么左右两帧可以考虑 batch 在一起送入推理来提高运行效率。
- C 代表 Channel 数,对于输入的 RGB 图片而言:
- CHW:代表先是 R plane,再是 G plane,最后是 B plane
- HWC:代表总共一个 plane,每个像素是 R+G+B 共24bits
不同的 Buffer 格式,是为了硬件效率的考虑。例如,为追求效率,还存在 NCHWC 格式 —— 部分通道独立成 plane,部分通道凑成 plane 中的一个像素。
内存中的图,存盘后便有了各种各样的格式。按使用场景:
- 训练中的图,权重(Wegihts)和网络结构分开存放。例如 Tensorflow 的 Checkpoints(权重)和 .py 中定义的网络结构。
- 部署后,仅进行推理的图:
- 权重被固化(freeze)到网络结构中
- 然后序列化成特定格式的文件。这样的格式有许多,如 Tensorflow 的 .pb,.tflite,以及其他平台生成的 .onnx 文件
SubGraph:异构计算的粒度
作为高负载的推理任务,为了能在端侧实时运行,硬件上会配置多组计算单元。例如 Nvidia 的 Xavier 平台,不仅有 GPU 用于推理,还有专用 DLA 来定向 offload。
进行异构推理计算时,需将一整个网络分成多个子网(SubGraph),不同子网被发往不同计算单元。
这些子网会进行针对性的转换,以便利用目标计算单元内建操作、片上缓存以及取指过程。
正片:多媒体 vs 推理
简介:多媒体负载
从两个场景入手来展开简介。
首先是一个直播场景,直播流以 udp 包,发给客户端的 1000 端口,随后拆包解码,在屏幕上显示内容:
# 以 GStreamer 为例的多媒体管线,其中 "!" 代表其前后元件连接起来
gst-launch-1.0 udpsrc port=1000 ! application/x-rtp,payload=96,media="video",encoding-name="H264",clock-rate="90000" ! \
rtph264depay ! h264parse ! ffdec_h264 ! waylandsink
# ^^^^^^^^^^^^^^^^^^^^^^^^^
划重点部分,从 rtp 包中解出 h264 有效负载(rtph264depay), 进行 h264 格式转换(h264parse 依需要是否转为 bytestream),最后送入解码器(ffdec_h264)。
这个例子中,控制流是所谓的 push mode —— rtph264depay、h264parse 和 ffdec_h264 就像链表中的三个函数指针,一个接着一个调用:
// 示意伪代码
rtph264depay->next = h264parse;
h264parse->next = ffdec_h264;
for (elem = rtph264depay; elem; elem = elem->next) {
res = elem->func(in_bufs, out_bufs);
in_bufs = out_bufs;
}
接着是视频播放场景。从 cloudlab.mp4 文件中,分离出视频流,随后塞入 queue、解码器并显示在屏幕。
gst-launch-1.0 filesrc location=cloudlab.mp4 ! qtdemux name=mdemux mdemux.video_0 ! \
queue ! ffdec_h264 ! waylandsink
# ^^^^^^^^^^^^^^^^^^^^^^^^
作为非实时的场景,播放速率会按设定帧数(例如 25fps)进行。这是由 waylandsink 来把关的,它会根据 Buffer 的 timestamp 来决定何时消费:
// 示意伪代码
consumer_thread() {
for (;;) {
buf = input.retrieve()
wihle (buf.timestamp < now)
wait();
render(buf);
}
}
上述控制流是所谓的 pull mode,即通过一个线程,主动决定何时读取输入,并渲染在屏幕。
通常而言,端上会有硬件的解码器,用它替换 伪代码示例中 ffdec_h264 即可。为使用这个解码器,Buffer 需从系统内存 upload 到设备内存,并把解码后的结果再 download 回来。
GStreamer 使用了一个名为 GstMemory 来 统一 地描述位于设备或系统内存中的 Buffer;而 Buffer 的元数据,诸如 Width / Height / Stride / Format (NV12, RGB…),以及 Timestamp 等,由 GstMeta 来描述。
最后再用一个 GstBuffer 来绑定 GstMemory 和 GstMeta,作为一个整体进行生命周期管理。
比较:推理与多媒体负载
神经网络推理负载,已超过多媒体成了端上计算资源的头号黑洞。附录给出一个对该负载加速的概述,基于各种算法和软件上的方法。
同多媒体负载一样,推理也存在专用加速硬件,如 GPU 以及更专用的 ASIC 芯片。
例如 Telsa 的 Autopilot 自动驾驶系统,HW 3.0 就是基于其自研的专用 ASIC 芯片。比 HW 2.5 基于 GPU 的方案,效率上会高不少。
同多媒体硬件加速一样,端上推理有硬件加速,例如 GPU,DSP,或是 GPU + DSP。此时,对 Buffer 进行抽象,是框架层面实现 zero-copy 以及 less-format-conversion 等优化路径的必需。
Nvidia 作为横跨图形和人工智能领域、炙手可热的 GPU 供应商,在推进一个 Generic Allocator 方案。在 Buffer format 基础上,丰富 format modifier 来描述 tiling 情况,并方便各个硬件对格式的协商。
从控制流角度来看,GPU 作为推理负载的常用硬件,其控制流类似 push mode —— 算子在 GPU 上实现为 kernel,输出输入串起的两个 kernels 会排队在 command queue 中,依次被执行。
Pull mode —— 因其存在条件判断及阻塞逻辑 —— 对推理加速硬件而言,通常是不友好的。
Apple 在 A13 处理器的两个大核中,加入了机器学习加速单元 AMX,扩展了相应的 AMX 指令集。这种直接入驻 CPU 的方式,应该能改善加速单元对 “条件有分支不友好” 的现状。
最后的一个比较角度,考虑推理和多媒体流中,负载最重的部分,例如推理的 Conv 算子和多媒体的编/解码器。
- 从实现上看,两者都可基于 GPU 实现
h264_CUVID 是ffmpeg 包含的、基于 CUDA 的 h264 解码器。
- 从功能上看,存在纯基于神经网络的视频编/解码器(自有编码过程)。不过仍属试验性质,压缩比相近但算力要求更高
神经网络的算子优化,正从人工编写的高质量代码,逐步依赖机器自动调优、生成更高质量代码。前者的代表是 cuDNN库(以及依赖的数学库 cuBlas 库),它是 Nvidia 提供的、人工编写的算子实现。
后者的代表,例如 tvm 的 auto tuning 机制、以及 polyhedral scheduling。
这些机器自动调优的方法,同样可以应用在多媒体编/解码器的优化中。
Unified Graph: 推理与多媒体
前一节比较推理和多媒体负载,我们发现:
- 两者都有异构计算情形。这意味 buffers 在不同计算单元流转时,存在 zero-copy 和 less-format-conversion 等优化机会。而这样的优化,必然要定义 buffer 抽象 以及 buffer allocator
- 控制流上,推理多数情况类比 pull mode
- 高负载部分,两者都可以应用 自动调优 。例如对于 CUDA 编程,将各个维度展开到 block、thread 上。并调整 Statements 的顺序,提升计算并行度和访存局域性
本节则抛砖引玉,进行一些开放式的展望。
在多数实际应用中,多媒体和推理是低头不见抬头见的邻居。例如从摄像头采集画面,处理后送入推理,进行物体识别;或麦克风采集音频,处理后送入语音识别。
另一方面,几乎所有的推理引擎(Google TF Lite、Nvidia TensorRT、Qualcomm SNPE、Arm NN、Intel OpenVINO、Tencent NCNN、Alibaba MNN、 …)只描述了推理图结构。
考虑负载相似性和应用上的耦合,展望统一的图(Unified Graph),描述一个多媒体 + 推理的混合流,从而对 App 开发者隐藏优化细节(流的 overlap、buffer 跨界流转,甚至是算子的跨界合并),榨干硬件性能的同时,又方便应用开发。
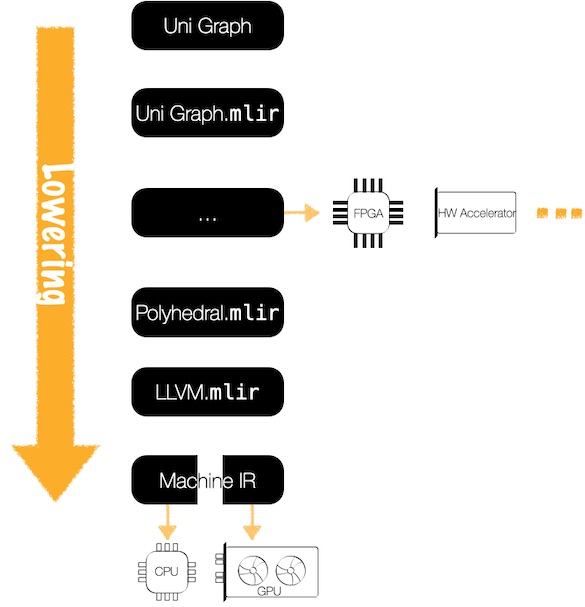
进一步展望,按照 Multi-Level IR 概念,将 Unified Graph 逐步 Lowering 并复用各层的优化 Pass,使得这个“多媒体 + 推理” 的管线得到极致优化。
附录
Convolution Gallery
| Conv | Diagram |
|---|---|
| Conv 3x3, no-padding, stride=1 | 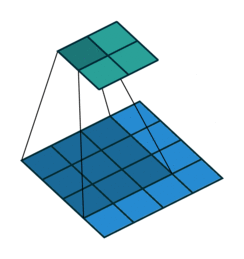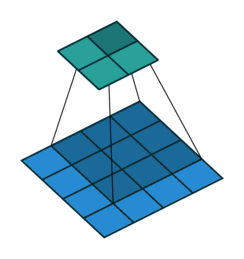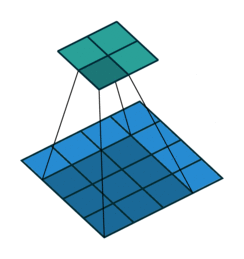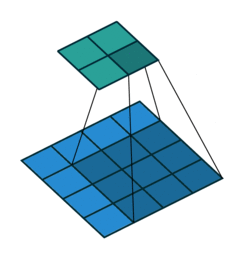 |
| Conv 3x3, no-padding, stride=2 | 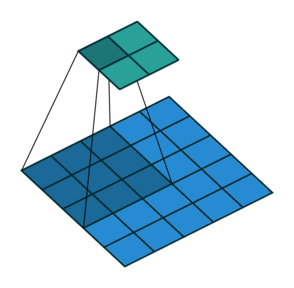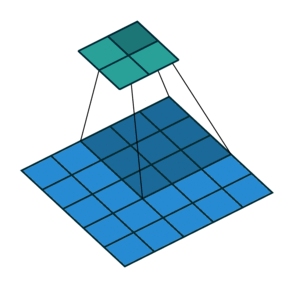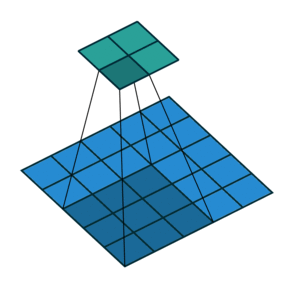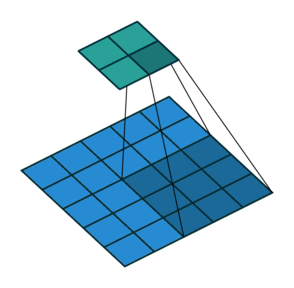 |
| Conv 3x3, same-padding, stride=1 | 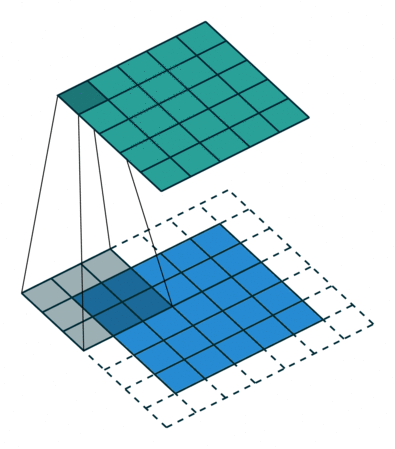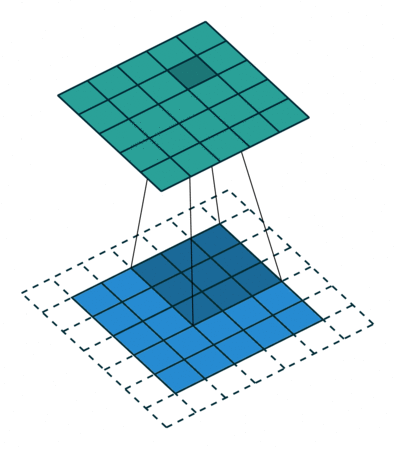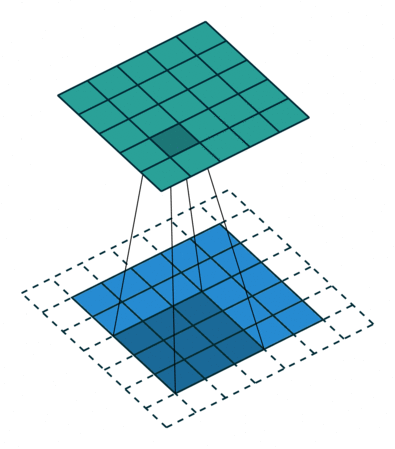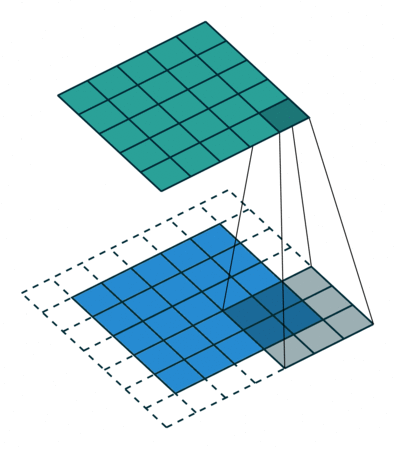 |
| Transposed Conv 3x3, padding=1, stride=2 | 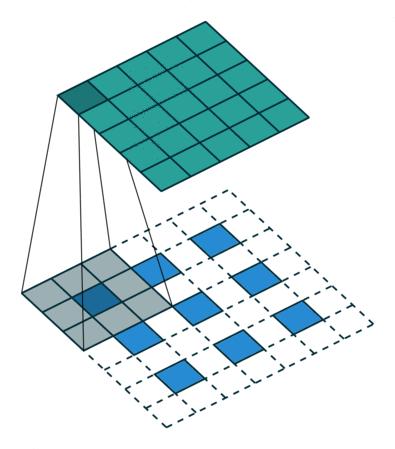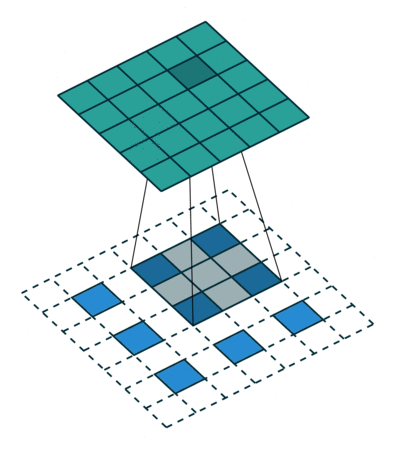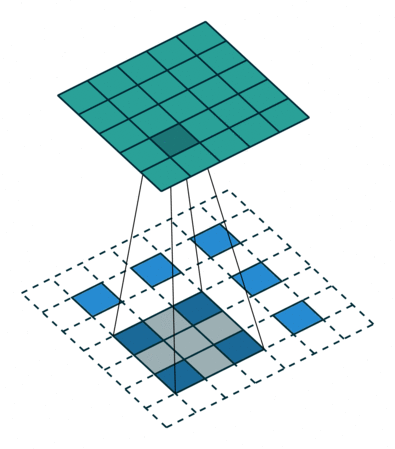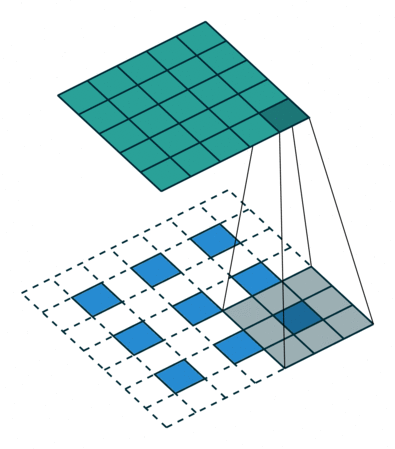 |
| Dilated Conv, no-padding, dilation=1, stride = 1 | 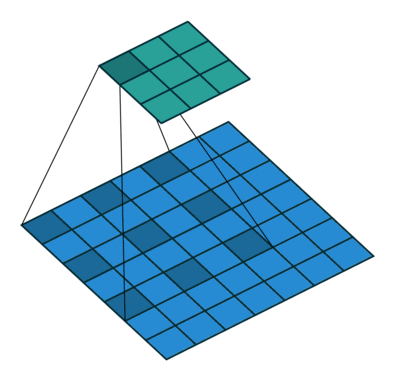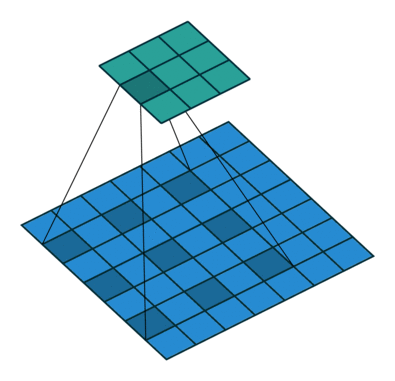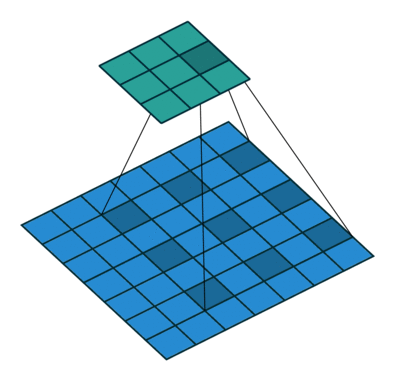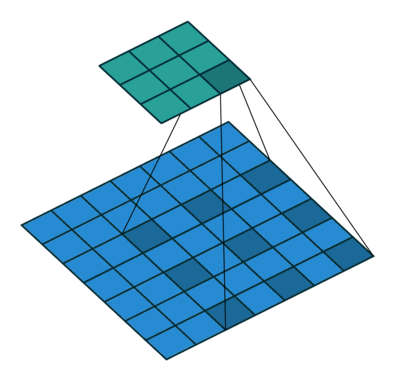 |
端侧推理加速方法集
| 分类 | 方法 | 背后私语 |
|---|---|---|
| 优化推理网络 | 使用经典轻量网络 | 例如,Mobilenet 系列,ShuffleNet 系列 |
| 自动生成高效网络 | 例如,作加法的 NAS(Neural Architecture Search),作减法的 Once for All | |
| … | ||
| 优化推理实现 | 算子的高效实现算法 | 例如,Conv 有滑窗、Im2col 和 Winograd 三种实现算法 |
| 精度换速度 | 例如,量化计算,用 int8 甚至 int4,来替代 fp32 | |
| 算子的合并 | 例如, - 垂直合并:输入输出串起的算子合成一个,收效明显。相当于把访存密集型,转变为计算密集型 - 水平合并:多路并行算子,合成一个塞入 GPU 等超宽硬件。类比通过拼车,提高运客效率 | |
| 单个算子的自动调优(Auto-tune) | 调整算子实现中,多个循环中的语句(statements):其先后顺序,或者到 thread / block 的映射,术语曰 schedule,只不过调度的是 statements | |
| … |
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
