

[置顶] Linux Lab v1.2 升级部分内核到 v6.3.6,升级部分 QEMU 版本到 v8.0.2,新增 nolibc 和 NOMMU 开发支持,另有新增 4 款虚拟开发板:ppc/ppce500, arm/virt, loongarch/virt 和 s390x/s390-ccw-virtio。Linux Lab 发布 v1.2 正式版,新增 4 款虚拟开发板,支持 LoongArch, Linux v6.3.6 和 QEMU v8.0.2
大开脑洞:丹佛核心,碰上超线程与逆超线程
by Chen Jie of TinyLab.org 2015/4/15
前言:丹佛微架构很快
最近,先是某表火爆销售,随后 12 寸的新 Macbook 也终于开卖。后者的一些评测报告也纷纷出现,最有意思的大概是下面这个:
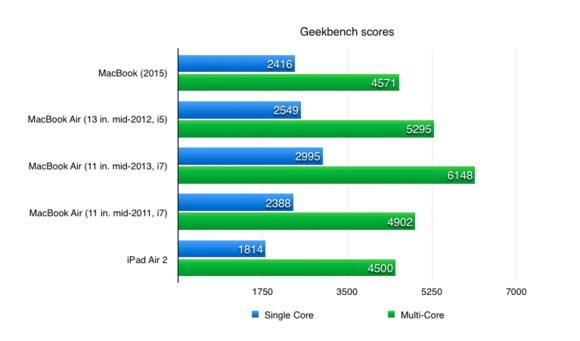
iPad Air2 A8X CPU 的性能渐近新 Macbook 搭载的低功耗版 Core M。这大概是苹果产品上,首次嵌入式 CPU 性能如此接近桌面级 CPU —— 并不是 Intel CPU 不给力,只是 ARM 阵营发展太猛。
说到 ARM 阵营的强 CPU,除了水果的 A8,就数 NVIDIA 丹佛(Denver)核心的 Tegra K1。后者采用了独特的动态剖析,并据此生成优化 VLIW (Very Long Instruction Word) 代码并缓存起来,供后续使用。进一步了解可戳这里。
丹佛微架构之喻
如果我们能站在 CPU 的一排执行单元前,看着指令进来,最壮观的景象大概是下面这个样子:
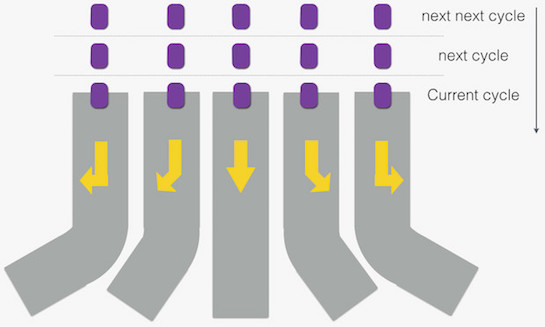
—— 就好像一排车流,驶在各自车道上,通过这个路口。这里,紫色的“车”好比是指令,而各“车道”则类比做各个执行单元。如果 CPU 能长时间保持上述壮景,性能就碉堡了!
那么问题来了,怎样做到每个时刻内,每条“车道”都有“车”在跑呢?
现应用于产品的,有两技术,一种叫做乱序执行,就是通过增加硬件来调度指令,这是主流技术。
另一种,走的是软件方式:或编译时,或运行时生成 VLIW 指令 —— 如果将一般的指令,比作占有一条“车道”的“车”,那么 VLIW 指令就是一次占满全部“车道”的“超宽” “连环” “车”。此方法的好处在于省硬件,省下的芯片面积可以用来增强其他硬件功能;另外 VLIW 本身就是调度结果的一个保存,即无需每次进行指令调度,从而节能。因此 NVIDIA 放出豪言:“Dynamic Code Optimization is the architecture of the future”。
当然,理想是美好的,现实是带感的,带着一丝骨感。站在 Tegra K1 的执行单元前,相当时间大概会看到下面的景象:
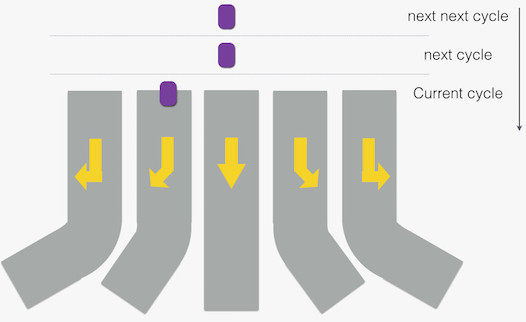
每时刻只有一辆“车”(指令)跑在一个 “车道”(执行单元)上通过路口(确切的说,这也算是理想,实际上会有一些时刻没有一辆“车”通过路口)—— 偌大的超宽 n “车道”,就这么白白浪费了。换句话说,这种情况下,Tegra K1 退化成了一个顺序执行的 CPU。
丹佛碰上超线程
顺序执行的 CPU,常有用到另一种增加执行单元利用率的方法,且耗的硬件资源不多。这方法大名叫做“超线程”,学名唤做“同时多线程”(SMT)技术。即是将来自两个以上线程的指令混在一起,丢给执行单元:
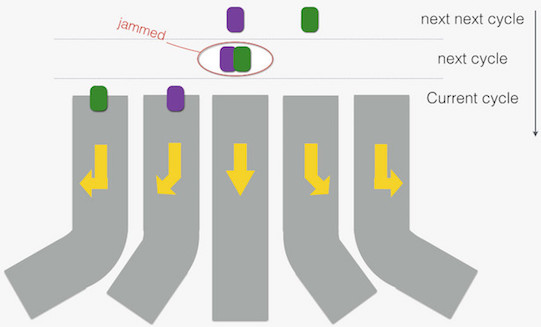
上图继续前文的比喻,绿色“车” 和紫色“车” 类比为来自两线程的指令,当它们行驶在不同“车道”上时(使用不同执行单元),“车道”的利用率提升了(执行单元利用率提升了)。这对 Tegra K1 这样拥有丰富执行单元的硬件而言,是非常划得来的。
不过当一组 VLIW 指令被执行时,“车道”被完全占满,另一线程指令连着好几个周期得不到执行,就像下面酱紫:
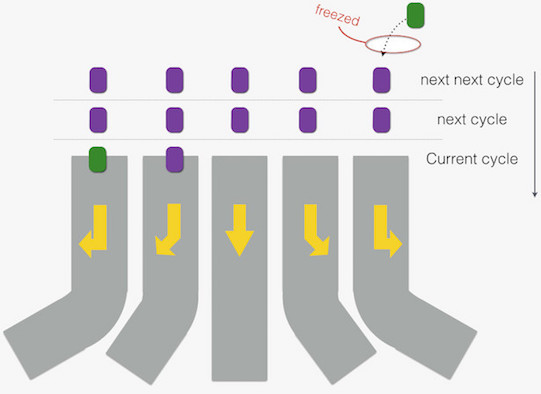
综上,很容易脑洞出,提高丹佛微架构下各执行单元利用率的方案:
- 当前执行非 VLIW 指令时,让其进入 超线程 模式,即从多个线程取指令,并发执行。
- 当前执行 VLIW 指令时,仅从单个线程取指令,换言之,逆超线程 模式。
那么,如何实现之?更进一步地说,操作系统的调度器该如何去支持呢?
矢量调度:游刃与超线程与逆超线程的戏法
接上节问,在此提出矢量调度 - 操作系统的任务调度器一次调度一个线程去执行,而矢量调度一次调度一组线程。这组线程又分一个 焦点线程 和 一群 背景线程:
- 焦点线程。焦点线程就是本该被调度的线程 - 用 Linux CFS 调度算法的判定,就是运行时间最少的线程。
- 背景线程。趁着焦点线程运行的空隙来运行。即当焦点线程无法完全消耗微处理器的执行资源时,背景线程去用起来。
举几个情景为例:
- 当_焦点线程_执行一组 VLIW 指令时,此时执行资源完全消耗,所有背景线程停止。
- 当某个_背景线程_此刻需执行一组 VLIW 指令时,该背景线程被停止(因对执行资源的完全消耗妨碍了焦点线程的执行)。
- 当_焦点线程_时间片耗尽,调度器计算和调度本组所有线程。调度器的调度时刻,完全取决于焦点线程。
- 当某个_背景线程_执行遇到缺页异常时,该背景线程被停止(因会触发调度,而调度仅由焦点线程决定)。
- 调度器调度 背景线程,可多于硬件超线程虚拟出的核数 - 当有背景线程停止时,处理器马上从下一个预备的背景线程取指。
- 处理器有相应寄存器来指明各背景线程的执行时间,以作调度决策之输入。
进一步扩大脑洞,除了丹佛这样特殊的微架构,矢量调度还可用于通常的 CPU - 即将数个 CPU 核 “并成一体”。例如场景“将一帧数据分块多线程处理,等全部处理完后输出下一阶段”。此时将分块处理的线程们作一次矢量调度,同时在(预留的?)数个CPU 核上执行。
猜你喜欢:
- 我要投稿:发表原创技术文章,收获福利、挚友与行业影响力
- 知识星球:独家 Linux 实战经验与技巧,订阅「Linux知识星球」
- 视频频道:泰晓学院,B 站,发布各类 Linux 视频课
- 开源小店:欢迎光临泰晓科技自营店,购物支持泰晓原创
- 技术交流:Linux 用户技术交流微信群,联系微信号:tinylab
| 支付宝打赏 ¥9.68元 | 微信打赏 ¥9.68元 | |
 |  请作者喝杯咖啡吧 |  |
Read Related:
Read Latest:
- Denver 2
- 超线程 1
- 逆超线程 1
- HT 1
- Hyper-Threading 1
- NVIDIA 2
- SMT 4
- Tegra 1
- Tegra K1 3
- VLIW 2
- 丹佛 1
- 矢量调度 1
- Scheduler 11
- ISA 4
